W3ACT User Guide
W3ACT USER GUIDE
W3ACT USER GUIDE
-
7.1) Look up a URL
7.2) Add Target
7.3) Edit/View modes
7.4) Overview Tab
7.5) Metadata Tab
7.6) Crawl policy and schedule
7.7) NPLD Tab
-
8.1) Requesting permissions for open access
-
9.1) Legal Deposit Library Collections
9.2) Researcher led collections
9.3) External agencies
9.4) Key sites
9.5) News sites:
-
13.1) Naming Conventions
13.2) Scheduling Guidelines [to be completed]
13.3) Licence Document
** **
Non-Print Legal Deposit Regulations came into force in the UK in April 2013. The Legislation brought about a huge transformation in web archiving in the UK Legal Deposit Libraries necessitating new workflows to deal with the selection, annotation and curation of content harvested both as part of the broad domain crawls and as part of more frequent and targeted crawling activity.
The Annotation Curation Tool (W3ACT) has been developed to meet the requirements of subject specialists wishing to curate web content harvested under the Legislation. W3ACT enables users to perform numerous curatorial tasks including the assignation of metadata and crawl schedules to web content, quality assurance and the ability to request permission for open access to selected websites.
A broad crawl of the UK Web Domain is performed annually by the British Library. The scope of the crawl includes all websites that have a UK top-level domain suffix (currently .uk, .scot, .london, .cymru and .wales); websites identified as being in scope by automated hosting checks and websites that have been identified as being in scope by additional manual checks, such as evidence of a UK postal address. In addition, several hundred national and regional online news publications are crawled on a daily or weekly basis. Furthermore, a list of 'key sites' defined and moderated by the Legal Deposit Web Archiving Sub Group (which reports to the Legal Deposit Implementation Group) are crawled on a regular basis.
A stipulation of the Legal Deposit Legislation is that content crawled under the Act can only be accessed within the reading rooms of the Legal Deposit Libraries. The LDLs aim to make selected permission-cleared content publically available through the UK Web Archive http://www.webarchive.org.uk.
Getting Started
W3ACT is available online at https://www.webarchive.org.uk/W3ACT/. To register to use W3ACT contact Nicola Bingham, Web Archivist, British Library [email protected], 01937 54 6972
After your account has been set up, you can log in to W3ACT by going to https://www.webarchive.org.uk/act/
Your User Name is your email address. A temporary password will be provided for you to log in with.
You should change your password after first logging in by going to: Users & Agencies -> Change Password https://www.webarchive.org.uk/act/passwords
If you have forgotten your password please email [email protected].
User account details should never be shared among users. This is so that a clear audit trail of activity within W3ACT is maintained.
Within W3ACT there exist a set of Roles each of which has an associated list of permissions. It is usual to set up new users with 'User' privileges until they are more experienced in using W3ACT at which point the account can be 'upgraded' to give access to more functions within the tool.
SysAdmin : Retains overall system control.
Archivist : No more than one Archivist per Legal Deposit Library** is allowed**. The Archivist moderates targets created by other users, administers collections and sends out permission requests. The Archivist has responsibility for ensuring that users of the tool adhere to the guidelines and principles set out in this document. The Archivist Role will not be created for external organisations using W3ACT.
Expert User : Can add new targets and request permissions for open access. Can edit other user's targets.
User : Can add new targets and request permissions for open access.
Viewer : Can search/view existing targets only.
Closed : Assigned to a user who is no longer active. When a staff member with a W3ACT user account leaves an Organisation their account will be set to 'Closed'.
For the full list of actions associated with each Role see: https://www.webarchive.org.uk/act/roles/list
There are several ways to search and browse for content in W3ACT.
If you know the URL, Target (or part of the URL or Target) type it in the Look up a URL bar (Targets -> Look up a URL) https://www.webarchive.org.uk/act/targets/lookup
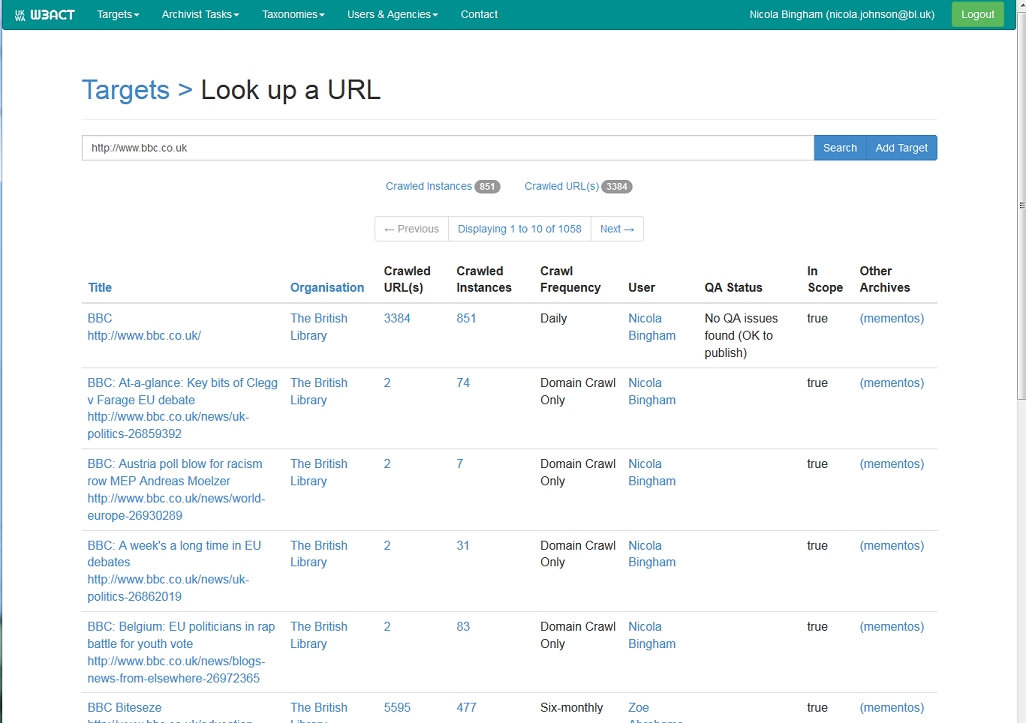
Figure 1. Look up URL screen
W3ACT returns all the Target records meeting the search criteria.
If you are searching for a particular URL it is likely that it will have been crawled automatically under NPLD, however a W3ACT Target record describing the URL may not have been created. If a record does not exist, the user is given the option of creating one by selecting the 'Add Target' button.
To browse for content in W3ACT go to Targets -> List Targets: https://www.webarchive.org.uk/act/targets/list?s=title
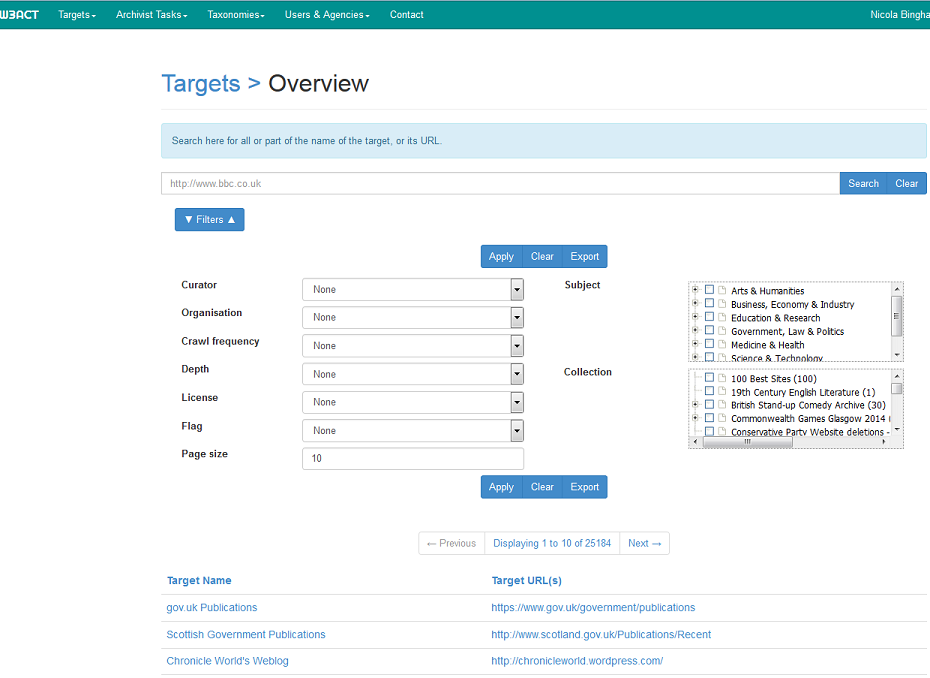
Figure 2.Target Overview
This section of the tool allows the user to query existing Target records in W3ACT by applying filters such as curator, organisation, collection, subject term, permissions status.
The number of results returned on the page can be adjusted by editing the 'Page size' text box. To view or edit a Target record, click on the Target Name in the column on the left of the screen.
Reports can be generated from queries created on the Target Overview screen (Figure 2.) and exported into csv format for management information purposes. To create a report, apply the appropriate filters in the Target Overview screen and hit the 'Export' button.
Reports on Target creation and Licences can be generated from the Reports menu.
https://www.webarchive.org.uk/act/reports
A Target is any portion of the Web that you wish to harvest and/or curate. 'Target' usually equates to a 'website' however it can be a section of a website or even a single document such as a PDF or blog post. If you have identified web content that you would like to describe and archive then it is a Target.
Before adding a new Target record to W3ACT you should check to see whether the URL already exists as a record on the system. To do this, go to the 'Look up a URL' screen (Figure 1). If the URL is in scope for NPLD then it is likely that it will have already been harvested as part of our domain crawling activity however there may not necessarily be a Target record describing the URL. It is not possible to create duplicate Target records. If you enter a URL for which a Target record exists, the system will prevent you from saving the record.
If no record exists for your URL, hit 'Add Target' and a blank 'New Target' record will open. A number of fields have to be completed at this stage, although not all of them are mandatory. Those that are mandatory are marked with a red asterisk. It is possible to save the Target record and add more details at a later stage.
Within the Target record there is a View and Edit mode. If you find that you cannot edit the fields within the Target record check to see whether the View or Edit Tab is selected.

Figure 3. New Target record
Title. Construct a title for the Target record. The title should be expressed, as far as possible, as it is on the live website however there are some Naming Conventions which should be adhered to when constructing a Title. This ensures consistency and will aid the end user in browsing the archive. See Appendix 13.1.
Seed URLs. The Seed URL field is auto-populated with the URL that was entered in the ‘Look up URL’ search box. It may be that additional URLs should be crawled in order to take a complete copy of the website.
It is worth checking to see what a URL actually resolves to. For example, a lot of http://domain.com sites will redirect to http://www.domain.com and so the latter should be used as the crawler will not automatically crawl both.
Separate additional URLs by commas. Include the protocol i.e., http://.
UK Hosting (automated check). This look up is performed automatically by the system after the record has been saved by connecting to a Geo IP database. See section 7.7) NPLD tab, page 15-16.
UK top-level domain (Includes .uk, .london, .scot, .wales and .cymru domains). This look up is performed automatically by the system after the record has been saved. See section 7.7) NPLD tab, page 15-16.
UK Registration. This look up is performed automatically by the system after the record has been saved by looking up a Who Is database. See section 7.7) NPLD tab, page 15-16.
QA Status: To be completed after the target has been crawled.
Live Site Status: This is automatically updated by the system.
Key Site: this list is moderated by the Legal Deposit Web Archiving Sub Group (see page xxx) and is to be completed by the Archivist only. Please do not check this button. Candidates for key sites should be passed onto the LD Web Archiving Sub Group representative from your organisation. The Key sites check box will only be available to Archivists in a later iteration of W3ACT.
WCT ID: Legacy admin fields. This field records the Target ID from the Web Curator Tool, if this Target was imported from WCT.
SPT ID: Legacy admin fields. This field records the Selection ID, if this Target was imported from the Selection, Permission Tool (BL Targets only).
Keywords: Free text keywords, private to you.
Tag(s): Keywords common to all users, controlled centrally and visible to other users.
Synonyms: Some websites use aliases to host content. For example www.company.co.uk may be the same website as www.company.com. If this is the case with the URL you are adding, record it here. Both URLs will be recorded in W3ACT and the system will prevent another user from creating a record to archive the same website. Seeds entered into the Synonyms field will not be crawled however they will prevent another user from creating a Target record with this URL.
*You do not have to save the record before moving between tabs (it does not hurt if you do). *
Figure 4.

Figure 4. Metadata Tab
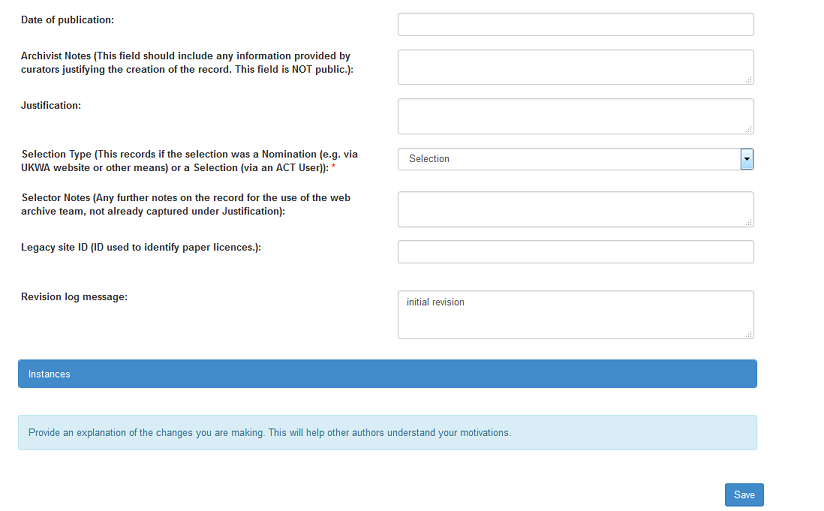
Figure 5. Metadata tab continued.
Description: A free text description of the Target. The description should be factual and neutral in tone. The publisher's own description may need to be moderated if using it in this field. This field is not publically available at the moment however it is intended to be in the future.
Subject: Assign subject terms to the Target by selecting from the drop down list. As many subject terms as appropriate can be selected. Sub-categories can be viewed by selecting the plus ('+') symbol next to the top level subject headings which expands the list. The subject terms are presented to users of the web archive to allow content browsing.
Collections: Targets can be added to collections by selecting the relevant collection term. Some collections have sub-categories which can be viewed by selecting the plus '+' symbol. To find out more about collections, including how to set one up, see section 9) pages 19-20.
Nominating Organisation: The organisation that nominated this website. This field is automatically populated with the nominating organisation (or agency) of the logged in user.
Originating Organisation: The organisation(s) responsible for creating the content. The originating organisation will often be reflected in the Title of the Target record, but not necessarily. For example the 'People's War' project was produced by the BBC. In this case "BBC" would be noted as the Originating Organisation.
Selector: The user that added this Target record. This field is automatically populated with the name of the logged in user.
Language: Record the predominant language in which the website or page is written. The ability to record more than one language is being developed and will be available shortly.
Author(s): A named individual responsible for creating the content. The name of the author is usually reflected in the title of the Target record, but this is not always the case. For example the Guido Fawkes Blog (http://order-order.com/) is authored by Paul Staines. In this example, "Guido Fawkes" is entered as the Title and "Paul Staines" is entered as the Author.
Flag(s): Check boxes can be used to flag the Target for attention of the web archivist. For more information on using the QA flags see section 10, page 22.
Flag notes: This field is used to provide more details about the flagged issue.
Date of publication: Use to record a publication date if it is significant.
Archivist Notes: This field should include any information provided by curators justifying the creation of the record. This field is not public.
Selection Type: This field records whether the selection was a Nomination received via the UKWA website or a Selection added by a W3ACT User. This record is auto populated depending on whether the record is being created by a logged in user via W3ACT or passed to W3ACT from the nomination form on the public interface.
Selector Notes: Any further notes on the Target for the use of the Web Archive team, not already captured in the Archivist Notes field.
Legacy site ID: This is used to cross reference the Target record with paper licences that were used by the BL outside of the electronic licencing process. This is a redundant field displaying historical information.
Revision log message: Note any subsequent changes you make to this page after saving the record.
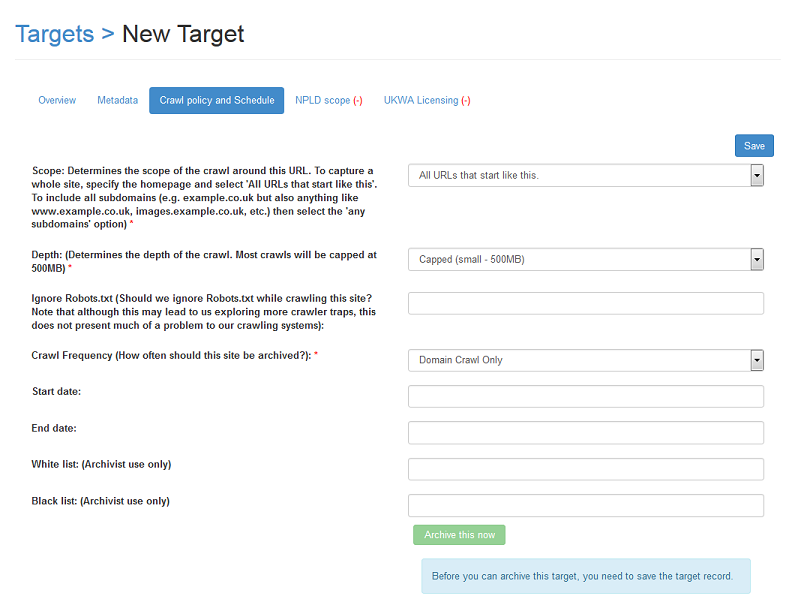
Figure 6. Crawl policy and schedule.
Crawl policy and schedule is only editable by those with the Expert User role or above.
Scope: Determines the scope of the crawl for this URL. To capture a whole site, specify the root or entry level directory of a website and select 'All URLs that start like this'. To include all subdomains (e.g. example.co.uk but also anything like www.example.co.uk, images.example.co.uk, etc.) then select the 'any subdomains' option).
Depth : Can only be edited by the Archivist. This determines the depth of the crawl. Most crawls will be capped at 500MB.
Ignore Robots.txt Can only be edited by the Archivist. Should we ignore Robots.txt while crawling this site? The robots.txt file should be viewed for every Target record URL entered. To do this, append "robots.txt" to the root of the domain name, e.g. "http://www.example.co.uk/robots.txt". A robots.txt file may look something like this:
User-agent: *
Disallow: /
The "User-agent: *" means this section applies to all robots. The "Disallow: /" tells the robot that it should not visit any pages on the site.
The above example shows a very restrictive robots.txt policy. In this case, the crawl profile should be set to "ignore robots.txt".
Note that although ignoring robots.txt may lead to us exploring more crawler traps, this does not present much of a problem to our crawling systems.
Crawl Frequency. How often should this site be archived? For recommendations on scheduling see Appendix xx
Start date: The date at which the crawl should start.
End date: If this is left blank, the Target URL will be revisited indefinitely. If the Target should only be gathered for a fixed period of time, for example, to cover a fixed event such as a General Election, set an end date.
White list: Archivist use only.
Black list: Archivist use only.
Archive this now: Selecting this button will schedule a crawl immediately after saving the target record. Use only if the gather is urgent, for example if the site is to go offline imminently. Only available to Archivist.
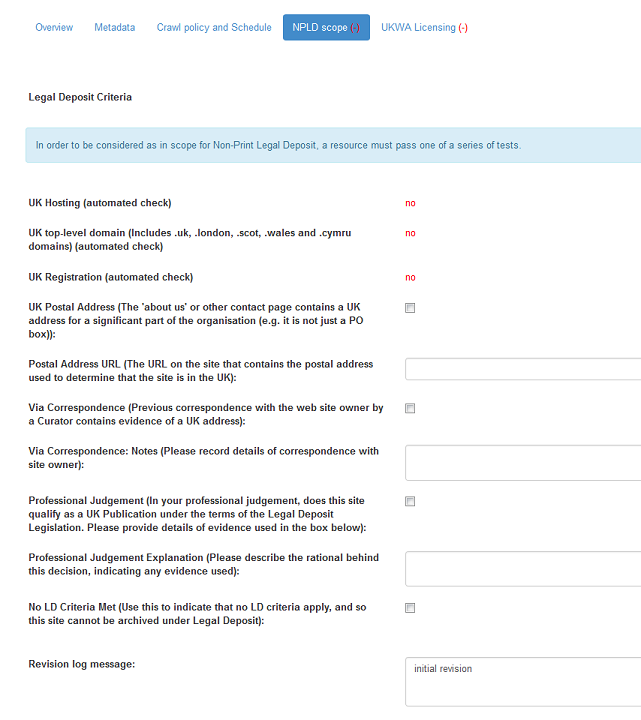
Figure 7. NPLD Tab
In order to be considered in scope for Non-Print Legal Deposit, a URL must pass one of a series of tests. Upon saving a Target record, the system runs three automated tests on the URL. If the URL meets one or more of the NPLD checks, the red negative symbol (-) on the NPLD tab will change to a green plus (+).
If the URL passes any one of the automated tests, no further action is required on the part of the user, the URL will be crawled automatically according to its schedule. If the Target URL fails all the automated tests, one of the other criteria (below) must be addressed manually by the curator.
UK Hosting: this check is run automatically by the tool against a GeoIP database after saving the record. Automatic Geo-IP has been implemented to look up UK hosts using an external IP geolocation database. This functionality has been added to the Heritrix crawler so that UK-located hosts are automatically allowed and added to the list of URLs to be crawled.
UK top-level domain : This check is run automatically against the relevant UK top level domain names.
(.uk, .london, .scot, .wales and .cymru).
UK Registration: An automated check is made against a Who Is database for ownership of a domain name.
UK Postal Address : The 'about us' or other contact page contains a UK address for a significant part of the organisation (e.g. it is not just a PO box). Both the check box and the URL field must be completed.
Postal Address URL : The URL on the site that contains the postal address used to determine that the site is in the UK. Both the check box and the URL field must be completed.
Via Correspondence : Previous correspondence with the web site owner by a Curator contains evidence of a UK address.
Via Correspondence : Notes: Please record details of correspondence with site owner. If you have received an email from a website owner in which a postal address has been given, for example, this can be recorded here. Both the check box and the URL field must be completed.
Professional Judgement : In your professional judgement, does this site qualify as a UK Publication under the terms of the Legal Deposit Legislation. Please provide details of evidence used in the box below.
Professional Judgement Explanation : Please describe the rationale behind this decision, indicating any evidence used. **Both the check box and the URL field must be completed. **
The following is an example of a 'Professional Judgement' justification for the Twitter account of David Cameron, https://twitter.com/David_Cameron: "This is the Twitter profile of David Cameron, the Prime Minister of the UK and Leader of the Conservative Party".
No LD Criteria Met : Use this to indicate that no LD criteria apply, and so this site cannot be archived under Legal Deposit. It may be that the target will change at a later date and will pass one of the LD criteria.
Revision log message: Note any subsequent changes you make to this page after saving the record.

This section of the tool allows curators to initiate the permissions process for open access to Target records through the Open UK Web Archive http://www.webarchive.org.uk.
To request permission for open access open the UKWA Licensing tab in the Target record.
Figure 8. UKWA Licensing tab.
Licence (The licence terms under which this site is archived and made available): Select the appropriate licence. The Open UKWA Licence (2014-) is the current, general permissions request which should be sent out for the general licence type. At the time of writing this guide, the licence and permissions licences for the different agencies using W3ACT are under review, however the text of the BL licence is appended, Appendix 13.3).
Open UKWA licence requests : This shows the current status of any requests to site owners for Open UKWA licences. If the permissions process has not yet been initiated, you can begin the process using the 'Open Licence Request' button.
Before you can request an Open UKWA licence, you need to save the target record. You cannot open a new licence request if a request is already queued.
To request that a licence for open access is sent to a website owner hit the green Open Licence request button. A new crawl permission form is opened up.
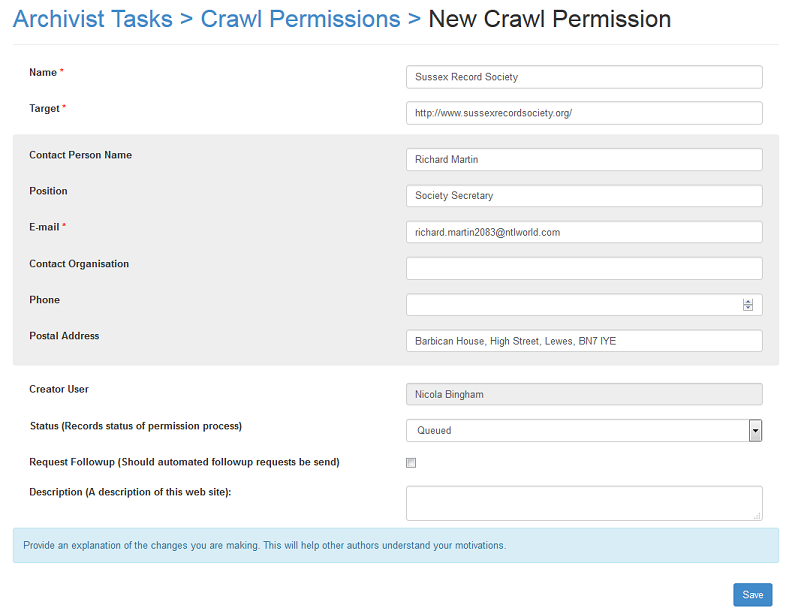
Figure 9. New permissions request form.
Complete the relevant fields. The required fields have a red asterisk against them. Website publishers are contacted by email.
Use the request follow up check box to indicate that you would like a follow up permission sent at a later date if we do not hear from the site publisher straight away. Alternatively the "Crawl Permissions" link takes you to the current status of a crawl permission.
Crawl permissions are put into a queue before being reviewed and sent out by the Archivist.
If the website publisher completes the licence document then the permission status of the Target record automatically changes to Granted. The red negative symbol (-) on the UKWA Licensing tab will change to a green positive (+).
Only the Archivist is able to send out permission requests. This is to ensure a controlled permissions process and to safeguard against the possibility of website publishers being contacted more than once. Licences for content harvested through the Document Harvesting process are also managed within W3ACT and the Archivist must ensure that publishers of 'Watched Targets' are not contacted with web archiving permission requests.
Archivists must be aware of publisher relationships carried out in their own organisations and not duplicate contacts, as this is confusing for publishers and potentially institutionally damaging. National news media publishers must not be contacted at the current time.

Figure 10) Resetting the licence
This field can be used by the Archivist to reset the license status within the Target record if a mistake has been made in the crawl permissions workflow.
Collections are groups of websites brought together on a particular theme: event-based, topical, or subject-oriented. Creating special collections is a 'value added' means of selecting content and requires additional curatorial attention including descriptive metadata. Collections are selected, described and crawled at a frequency appropriate to individual items within the collection. Everything selected for focused crawls is also added to the annual domain crawl to be crawled on an ongoing basis, so long as it remains in scope.
Various types of collection are undertaken:
The Legal Deposit Web Archiving Sub Group (LDWASG)* coordinates around 5 or 6 Legal Deposit Library collections per year. The subject of these collections is usually relevant to a specific event or theme, often with some kind of national or international significance (e.g. General Elections, Olympic & Paralympic Games, or major anniversaries such as the Centenary of the First World War). The LDWA sub group canvasses proposals for focussed collections from content specialists across the LDLs and decides which ones will go ahead, instigating and supporting them.
* The Legal Deposit Web Archiving Sub Group (LDWASG) oversees the end to end process of web archiving for non-print legal deposit across LDLs. As one of the groups in the NPLD governance structure, it reports directly to the Legal Deposit Implementation Group. Membership of this sub group includes a representative of each of the Legal Deposit Libraries plus key members of the Web Archiving team (as necessary), including, but not limited to, Engagement and Liaison Manager and Web Archivist. The British Library will initially fill the roles of Chair and Secretary (as of 2015).
Other collections can be instigated at any time on a particular theme or area of interest. They can be set up by individuals, external agencies or a combination of both. Examples include the French in London Special Collection (http://www.webarchive.org.uk/ukwa/collection/63275098/page/1) which is managed by a researcher at the University of Westminster.
If you would like to set up a collection you should discuss it with the Archivist in your organisation and complete a scoping document, an example of which is appended to this guide (Appendix 13.4).
Increasingly, the LDLs seek to work in partnership with external agencies to develop collections in line with the partner's area of expertise or collection scope. This is a good way to harness expertise in a wide range of content areas and/or provide a service to those organisations that are unable to carry out web archiving themselves. Examples of external organisations who manage collections administered by the BL include the Live Art Development Agency (http://www.thisisliveart.co.uk/) and the British Stand-up Comedy Archive at the University of Kent (http://www.kent.ac.uk/library/specialcollections/standupcomedy/index.html).
Collections managed by external agencies should be overseen by an Archivist and, in particular licences for open access must be directly administered by the Archivist through W3ACT and not handled outside of the system. Having said this, a better response rate is garnered if the partner's themselves communicate with website publishers by way of a pre-permissions or introductory email if open access is being sought for the collection. An example of a pre-permissions or introductory email can be provided on request by the Archivist.
The selection of 'key sites' is another way in which content is prioritised to receive greater attention in curation and quality assurance. The list is moderated by Legal Deposit Web Archiving Sub Group which instigates a review of the list, once a year to receive proposed revisions. As of July 2015 the key sites list stands at c 260.
Key sites are:
(i) permanent rather than occasional or time-limited;
(ii) of general interest in a particular sector of the life of the UK and/or its constituent nations;
(iii) usually the sites of organisations, or of individuals acting in their official or semi-official capacity (although some exceptionally influential individuals, such as some celebrities or journalists might be included);
(iv) a whole domain, rather than subsections or individual pages;
(v) hosted in the UK, or substantially published here. They need not have a domain that ends in .uk – there will be some eligible sites with .org, .com or other addresses.
The list will not be comprehensive: that is, the inclusion of a particular site will not require that all sites with equivalent or analogous functions are also included.
A list of several hundred national and local news media sites is maintained by the web archiving team in consultation with the other LDLs via the Legal Deposit Web Archiving Sub Group.
Comprehensive news coverage ensures that when an immediate response is needed to an emerging news event, such as the death of a major public figure or a natural disaster, relevant content has already been captured.
Quality assurance (QA) refers to the process of examining the characteristics of websites captured by W3ACT to ensure that they have been harvested as comprehensively as possible. In the selective web archiving model, undertaken through the Web Curator Tool, harvested websites could be rejected (deleted) if they were not successful enough to become valid archival copies. In the Legal Deposit/W3ACT workflow, content is not deleted, however it is possible to ensure that a better harvest is achieved with future captures by changing the crawl parameters.
Users and Expert Users have the ability to review their harvested websites and perform a first line of QA in W3ACT. Links within the tool allow users to browse harvested content and flag issues for the attention of the Archivist who performs a second line of QA, diagnosing the issues and altering the crawl parameters as appropriate.
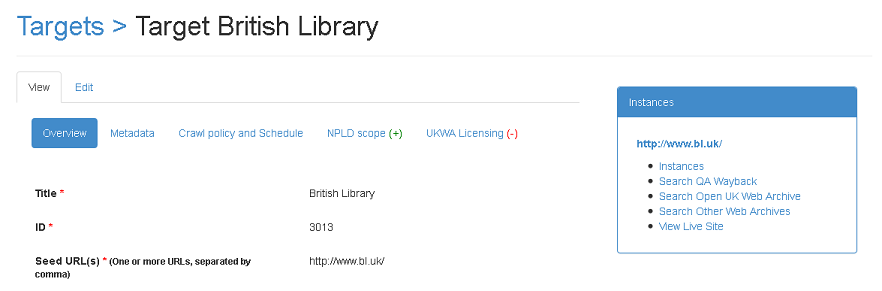
Figure 11. Links to harvested websites from Target record
Within the Target record on the Overview Tab, links in the 'Instances' box on the right of the screen, take the user to harvested copies of websites (Figure 11.).
Instances : This link takes you to individual snapshots of the Target website, allowing you to make notes at instance level [NJB: workflow to be confirmed].
Search QA Wayback : link to harvested snapshots on the Wayback timeline. The Wayback is a key piece of software that web archives worldwide use to 'play back' archived websites in the user's browser.
Search the Open UK Web Archive : Link to harvested copies of this website in the Open UK Web Archive, if permission has been cleared. Websites that do not have licences for open access will not appear here.
Search Other Web Archives : Links to harvested copies of this website in other archives via the Mementos Service. This is useful to compare harvested copies of websites in other archives.
View Live Site: Link to the live version the website**.**
When performing QA the harvested copy of the website (Search QA Wayback) should be viewed alongside the live site (View Live Site).
Make a note of the issues in the Target record, Metadata Tab by checking the appropriate box and briefly describing the issues (Figure 12, below).

Figure 12. QA Flags and notes
W3ACT users should not worry about diagnosing issues, rather should they simply record any obvious problems for the attention of the Archivist who will escalate issues to the Crawl Engineer as appropriate.
The broad criteria to consider when assessing a harvested website can be classed as follows:
• Capture: whether the intended content has been captured as part of a harvest
• Intellectual content: whether the intellectual content can be replayed in the Access Tool
• Behaviour: whether the harvested copy can be replayed including the behaviour present on the live site, such as the ability to browse between links interactively
• Appearance: look and feel of a website
One or more of the following three flags can be checked to capture QA Issues:
QA Issue – Content
QA Issue – Appearance
QA Issue – Functionality
The Archivist then picks up a report of Targets with QA Issues and will begin diagnosis.
Note to Archivists – Reports on Targets with QA Issues flagged by users can be viewed on the List Targets page https://www.webarchive.org.uk/act/targets/list?s=title by selecting the appropriate Flag and selecting 'Apply'. The report can be configured by Curator, Organisation, Collection etc. by applying filters using the drop down menus.
Figure 13. QA Report for Archivists.
[NJB: this section incomplete] Common issues associated with web harvests.
• Links in the harvested site jumps to live website, instead of linking to harvested content within the web archive.
• The crawler is in an indefinite loop (i.e. crawler trap).
In most cases this can be resolved by applying filters and re-harvesting the site with refined crawl settings.
• Robots.txt has prevented the crawler from reaching certain parts of the site such as images or style sheets.
Crawl settings can be refined to ignore robots.txt and the site re-gathered.
• Most of the content is inaccessible because it is dependent on dynamic user interactions, e.g. user input in search forms.
• Significant content is inaccessible because it relies on Flash and Flash Navigation which currently cannot be captured.
A test crawl is recommended for such sites to determine how much content can be captured.
• Content of the site is only accessible through JavaScript (e.g. menus).
This issue can sometimes be omitted if a website has an HTML site map.
• Streaming media content forms a significant part of the website.
• The content is dependent on embedded external applications e.g. Google Earth, Google Maps, YouTube etc
A target is the portion of the Web that you want to harvest, archive and describe. It can contain multiple URLs or seeds. It contains scheduling information.
An instance is a single harvest of a target that is scheduled to occur or has already occurred at a specific date and time.
As such, each target in W3ACT will over time have many instances associated with it, each of which will have individual QA and crawl data.
A seed is a URL which the crawler uses to initiate a harvest. Targets can have multiple seeds. Crawl profiling instructs the crawler how the seed is to be treated, e.g. "this URL and all sub domains", "all URLs that match this host".
The following guidelines should be adhered to when creating Target titles.
As a general rule the title of a Target record should be written as it is on the website. There are some exceptions and general rules which should help with consistency.
Acronyms
If the Target describes an organisation which has an acronym in the title, spell out the title in full with the acronym appended in brackets: e.g., Botanical Society of the British Isles (BSBI) The abbreviation can only be used in exceptional cases if the organisation is more commonly known by it: e.g., NSPCC - National Society for the Prevention of Cruelty to Children
Definite articles
Append the 'The' to end the title: e.g., 'Daily Mail, The' or 'Guardian, The'
Sub-sections of a website
If your Target describes an article or sub-section of a website, put the main website heading or publication title first appending the article or section title separated by a colon:
e.g., Daily Mail, The: Hospitals will have to shrink or close under new plans to treat more patients in the community e.g., BBC News: Death of Nelson Mandela e.g., Personnel Today: London mayor Ken Livingstone claims 2012 Olympic Games will benefit the careers of 20,000 Londoners
Social Media
The name of the organisation or individual should come first followed by "on Facebook".
e.g. Labour Party on Facebook
The titles of Twitter accounts should be constructed as follows:
Title (named individual or organisation) ->Twitter Handle in brackets -> "on Twitter"
e.g. David Cameron (@David_Cameron) on Twitter
e.g. Liberal Democrats (@LibDems) on Twitter
The following is the text of the current Web Archiving Licence form used by the British Library Web Archiving Program:
You have reached this page because your website has been selected by the British Library to be included in its Web Archive. If you are happy for your site to be archived, please complete the Licence form below.
If you are not the sole owner of copyright (and other rights) in the content of your site, please ensure you have cleared the permissions with other contributors to your site. It should be noted that the British Library reserves the right to take down any material from the archived site which, in its reasonable opinion either infringes copyright or any other intellectual property right or is likely to be illegal.
We select and archive sites to represent aspects of UK documentary heritage and as a result, they will remain available to researchers in the future. The British Library works closely with leading UK institutions to collect and permanently preserve the UK web, and our archive can be seen at www.webarchive.org.uk.
For more information about copyright and how your archived website will be made available, please see the FAQs. Alternatively, if you have any queries or need further information, please do not hesitate to contact us.
The British Library Web Archiving Licence
I / We the undersigned grant the British Library a licence to make any reproductions or communications of this web site as are reasonably necessary to preserve it over time and to make it available to the public: (All fields marked * are compulsory)
Licence:
Title of Website: *
Web Address (URL): *
LICENCE GRANTED BY:
Name: *(organisation or individual)
Position: *
E-mail: *
Postal Address:
Contact Organisation:
Tel:
Any other information:
Third-Party Content: *
Is any content on this web site subject to copyright and/or the database right held by another party?*
Yes No
In consideration of the British Library archiving the website, and crediting me on the UK Web Archive, I confirm that I am authorised to grant this licence on behalf of all owners of copyright, database right or trade marks in the website; I further warrant that (i) nothing contained in this website infringes the copyright or other intellectual property rights of any third party; (ii) no claims have been made in respect of any part of the website; (iii) I am not aware of anything unlawful on the website; and I promise to notify the Library if I become aware that a claim is subsequently made in respect of any content on the website.
I / We agree: * Yes
Date
Would you allow the archived web site to be used in any future publicity for the Web Archive? *
Yes No
Personal details you provide on this form are protected by UK data protection law. Please view our Privacy Statement.
Contact information:
Example Collection Scoping document:
**LDP06 Focussed Crawl of the NHS Reforms collection **
Scoping Document
**Document history **
| | | | | |
| --- | --- | --- | --- | --- |
| Version | Date | Person | Role | Change details |
| 1.4 | 14/02/13 | Nicola hnson | | Incorporating comments from RG, RM and HHY |
| 1.3 | 08/02/13 | Richard Gibby | | Minor amendments. Comment on section 5.3 re UK Scope; question on section 8 |
| 1.2 | 04/02/13 | Richard Masters | | Comments on sections 5.1 and 5.3 |
| 1.1 | 01/02/13 | Helen Hockx-yu | | Edit section 9; general minor edits |
| 1.0 | 28/01/13 | Nicola hnson | Author | Timescales and access requirements added. |
| 0.1 | 24/01/13 | Nicola hnson | Author | Initial draft |
TABLE OF CONTENTS
-
Background
-
NHS Reforms Background
-
Objectives
-
Selectors
-
Collection Scope
-
Key sites and initial seed lists
-
Communications
-
Time scales
-
Tools and workflows
-
Access Requirements
-
Stakeholders
1. Background
**INTRODUCTION **
This document aims to establish the scope of a thematic website collection initiated as part of the LDP06 UK Domain Crawl Pilot project. The proposed collection has been given the working title "NHS Reforms".
Legal Deposit legislation is expected in the UK on 6th April 2013. The LDP06 project aims to complete preparation activities to enable crawls of the UK domain. As well as broad, domain scale archiving, these also include curated, focussed crawls on specially chosen topics. The question of selective collection development subsequent to the legislation needs to be addressed. The proposed NHS Reforms collection will serve as a test bed for establishing collection development policies, selection activities, stakeholder relations, workflows etc for future thematic collections post Legal Deposit.
**UK WEB ARCHIVE **
LDLs such as BL, NLW and NLS have been selectively archiving UK websites since the early 2000's. Curatorial input ensures that valuable resources are selected in line with the Library's content and collection development strategies. LDLs prioritise the selection of websites which reflect the diversity of lives, interests and activities throughout the UK. The objective is to preserve those web resources which are expected to be of interest to future researchers. Additional criteria that inform the selection process include whether content is only published on the web, whether a website is at risk of being lost, and whether selection would result in a more comprehensive collection.
**COLLECTION BACKGROUND **
In 2012 the BL Web Archiving Team canvassed curators and subject specialists on their preferred topic for a website collection on an important and newsworthy event in March / April 2013 for the LDP06 project. The topic of NHS Reforms was suggested by Jennie Grimshaw, Lead Curator for Social Policy & Official Publications and was voted as the first choice for a focussed web crawl by three other curators in the BL and subsequently accepted by other LDLs.
The Reforms brought in by the current government will mean one of the biggest restructures in the history of the NHS potentially creating a massive impact on health care provision in the UK. There is already a large amount of online debate about the subject, material which the web archiving team is keen to capture for posterity. Of immediate priority are the websites of the c. 150 Primary Care Trusts as from the 31st March 2013 the PCTs will no longer be obliged to keep their websites online with the potential loss of large amounts of crucial documentary material. The interesting part of this collection will be the reactions to the changes on Blogs, twitter feeds, social networking etc. The reforms are already proving controversial and we aim to capture the polarised nature of the debate.
** 2). NHS REFORMS BACKGROUND**
The NHS Reforms have come about as the Government believes that health service provision needs to become more cost efficient. Costs in the NHS are rising at a much higher rate than inflation due to factors such as the ageing population, costs of new drugs and treatments and lifestyle factors such as obesity.
The central element of the NHS reforms is the Health and Social Care Act 2012 which makes provisions for a number of changes to the NHS, while social care funding reform is also being mooted. As the changes happen both the PCTs and the regional bodies known as strategic health authorities are to be phased out.
Currently NHS spending is controlled primarily by local health managers working for NHS primary care trusts whereas the Act gives more responsibility to GPs and other clinicians for budget control. The private sector and social enterprises are also encouraged to get more involved in decision making.
The cost of the programme has been estimated at £1.4 billion, the bulk of which will come in the next two years as more than 20,000 redundancies are made of management and administration staff.
3). Objectives
This scoping exercise will:
-
Establish the stakeholders involved in selecting content
-
Establish the collection parameters of the collection, numbers, sub-categories etc
-
Identify key sites and seed lists
-
Decide whether and what descriptive metadata need to be added
-
Initiate a communications plan
-
Determine project timescales
-
Set down a workflow for passing selections to the BL.
4). SELECTORS
As part of the scoping exercise the question of who is to select the content for the collection and who has overall responsibility for the collection must be addressed. The decision will take into account the results of the BL's recent Selective Web Archiving Consultation 2012-13. The consultation was designed to gain feedback on the relationship between the legal deposit crawl process and ongoing (permissioned-based) selective archiving activity. One of the questions the survey asked was who should have a voice in the selection of key events, and of items for regular crawls (sites which need to be crawled more regularly eg bbc.co.uk).
The potential selectors include:
• BL Curators
• BL Reference desk staff
• The other legal deposit libraries
• Research organisations with domain expertise and an interest, e.g. The Wellcome Library
• Users of the Archive (eg researchers)
• Members of the public
• Web Archivist
• Web Archiving Team
The consensus appears to be that a board made up BL Curators, the Legal Deposit Libraries and the Web Archiving Team should make the selections whereas as consultation exercise will be undertaken with a wider group. [Peter to elaborate]
5) Scope, Collection parameters, scope, numbers
The following guidelines form the selection parameters:
5.1) UK Scope
Websites should be UK in scope. UK websites are defined as those:
• with a .uk domain name,
• with a non .uk domain name but hosted in the UK,
• owned by UK organisations or individuals with a UK postal address,
5.2) Size of collection
- A special collection typically contains more than fifty and less than four hundred websites. The NHS Reforms collection aims to archive a minimum of 200 websites.
5.3) Content Scope
In thematic terms the scope of the collection will be comprised of sub-categories. The following topics will be included in the collection.
-
The websites of the Primary Care Trusts (PCTs) (c. 150). Seed list on Wiki at https://intranet.bl.uk:8443/confluence/display/WAG/Topic%28s%29+for+Focused+Crawl+in+2013
-
Professional Bodies, Royal Colleges
-
Unions
-
Private Sector Care providers
-
Health Care organisations
-
Patient's Groups
-
Political Parties, MPs
-
Central Government, the Department of Health, Regulatory Bodies
-
Local Councils
-
The Press/News
-
Opposing Groups/Commentators
-
Blogs, twitter feeds, social media that are created by individuals or organisations that fall within scope of territoriality.
-
Scholarly Institutions and Research Organisations.
6) Key sites initial seeds lists
-
The websites of the Primary Care Trusts (PCTs) (c. 150) seed list on Wiki at https://intranet.bl.uk:8443/confluence/display/WAG/Topic%28s%29+for+Focused+Crawl+in+2013
-
Key sites (101) on Wiki at ………
7) Communications
The project will include a communications plan with more detailed stakeholder analysis, defining the required communications mechanisms for the stakeholders so that all identified stakeholders are informed of the project's current status and future directions.
Communications will be led by the Web Archiving Engagement & Liaison Manager. [Peter to elaborate]
8) Timescales
The collection time scale will be constrained by the parameters of the LDP06 project. Crawling is likely to start as soon as the Regulations are in force on 6th April 2013 and the content is to be made available to users in the LDL Reading Rooms at the end of June. The fixed end date is necessitated as the generation of SIPS/METS files needs to take place as a single, discrete process upon the finalisation of the collection.
From the curatorial point of view it is recommended that the collection span several months to reflect the gradual evolving of the Reforms, therefore there is a potential conflict over the end date of the collection.
Options for maintaining the integrity of the collection while fulfilling the terms of the project are being investigated – for example, to launch the collection in June, serving the content from the Web Archiving's HDFS infrastructure while continuing to add content beyond this date, or to re-engineer the SIP generation process.
- Tool and workflows
The beta version of a new tool will be used to support the selection process: http://194.66.239.75/curate/user. Please note that the URL will change and the Tool will also be given a name when used for the project. The BL Web Archiving Team will continue with the development and improvement of the tool and curators will be encouraged to give feedback about the tool.
- Access Requirements
According to the proposed Legal Deposit Legislation, access to the content obtained via legal deposit web crawls will be restricted to single concurrent access on the LDL's premises. That is each Legal Deposit Library will only be able to give access to a particular 'Work' on one terminal at a time in the Reading Rooms.
Online access to content may be possible but will be decided at a later date.
- Key Stakeholders (British Library)
| **Name ** | Role |
|---|---|
| Helen Hockx-Yu | Head of Web Archiving |
| Andy Jackson | Web Archiving Technical Lead |
| Nicola hnson | Web Archivist |
| Richard Masters | Senior Technical Project Leader |
| Web Archiving Engagement & Liaison Mgr | |
| tbc | BL Curators |
| NLW (names to be confirmed) | |
| NLS (names to be confirmed) | |
| Other LDLs (names to be confirmed) | |
| Others… | |