Software Knowledge Repository
Until now, the analysis has used files to store information about the observed system. This had the disadvantage that when different analyses wanted to read and modify the information simultaneously, information might get lost or was overwritten. To solve this issue, we needed a knowledge repository which was able to handle concurrent access and different variants of the system models. This article presents a solution created during the 2017 master project at Kiel University which uses Neo4j databases to serialize and query the information.
The Palladio Component Model which we will reference to as PCM in this article is a meta model for modelling component based software systems. It allows the modelling of different domains of a software system with different submodels. You can get more detailed information about it from its developer's website or this technical report. The different PCM submodels are:
- Repository model, which includes different components of a software system, their roles, interfaces between them and the signatures of interface methods.
- System model, which puts different components and their roles in concrete contexts. For example a component for placing orders in a webstore could be used in the context of private orders placed by average customers and also in the context of business orders placed by companies.
- Resource environment model, which includes different resource containers representing the available hardware components.
- Allocation model, which represents the actual allocation of these hardware components.
- Usage model, which represents use cases of the entire software system.
The PCM was implemented using the Eclipse Modeling Framework (EMF) and all model components are available as EObjects in the source code of iObserve.
Neo4j is a graph database, which means that instead of tables like a relational database it uses labeled graphs to store data. You can find more detailed information and tutorials on the developer's website. Basically, a Neo4j graph consists of nodes and directed edges which are called relationships in the context of Neo4j. Both can have multiple properties attached to them. Properties are key value pairs. Additionally, nodes can also have multiple labels attached to them. A label can be used to mark a certain role or a type (e.g. "Person" for modelling human beings). Relationships always have to have a self defined type, which specifies the kind of the relationship (e.g. "KNOWS" for relationships between two persons). A Neo4j graph database is stored in a single folder on your file system.
In this project, we used Neo4j 3.2.0 embedded in our Java application as described here. You can find the following line in the build.gradle file in the analysis root directory to import the Neo4j dependency:
compile 'org.neo4j:neo4j:3.2.0'If you continue working with Neo4j in this project, I recommend to also use the Neo4j desktop application which allows you to inspect the data in your database with an easy to use web interface. This also provides a nice visualization of your graphs. The following figure shows the graph of a repository model in the web interface's visualization.
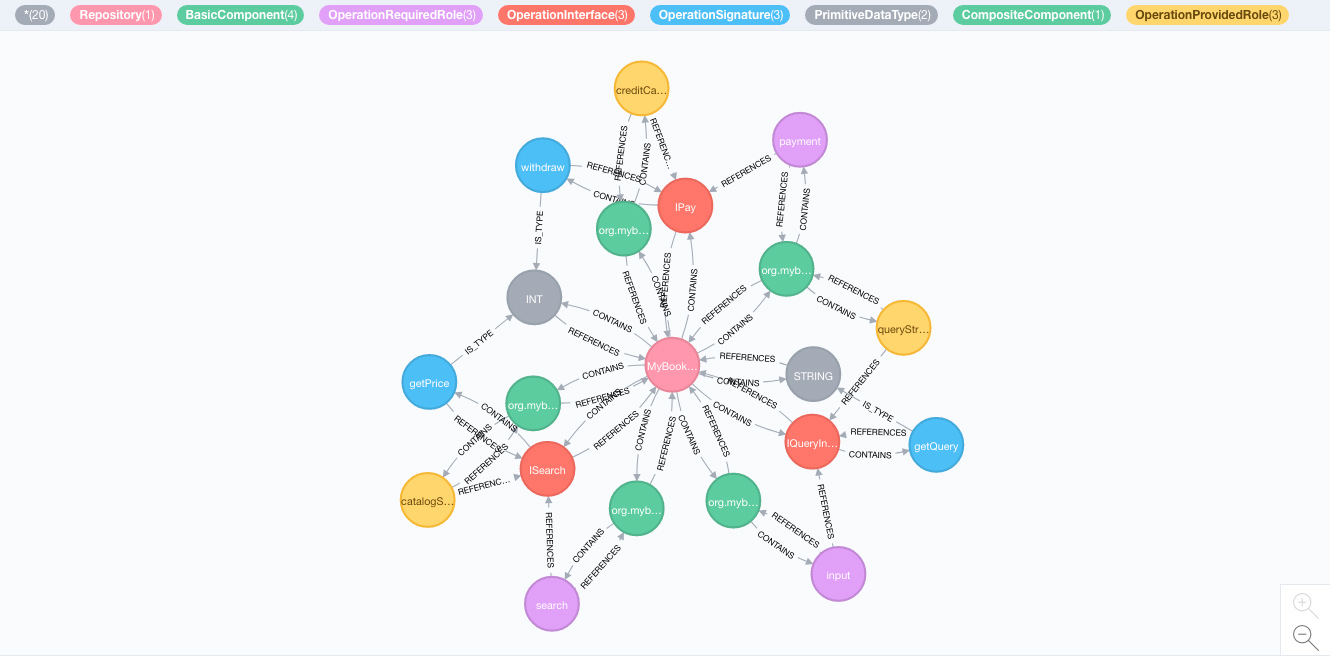 To use it, simply install the application, chose your database directory, click start, open http://127.0.0.1:7474/ in your browser and log in. The default username and password to log in into the web interface are both "neo4j". If you choose to use the web interface you will also have to take a look at Cypher, which is the query language for Neo4j graphs. For first steps
To use it, simply install the application, chose your database directory, click start, open http://127.0.0.1:7474/ in your browser and log in. The default username and password to log in into the web interface are both "neo4j". If you choose to use the web interface you will also have to take a look at Cypher, which is the query language for Neo4j graphs. For first steps
match (n) return nwill return you all nodes and the relationships between them, while
match (n) detach delete nwill delete all nodes and relationships from the graph.
For getting a basic understanding of the knowledge repository and how it is working, we will introduce the basic components in this section. The goal of this implementation is to store Palladio models in a Neo4j graph database. So on the one hand we have the Neo4j graph database, which is represented as an object of type Graph in the code and which we will simply reference to as a graph in the following. On the other hand, we have a class called ModelProvider, which provides operations to create, read, update or delete Palladio models in a certain graph. A model provider always belongs to exactly one graph, whereas a graph can be modified by an arbitrary number of model providers.
Depending on the context in which you are using the knowledge repository, for example in a filter in the pipe-and-filter architecture of the iObserve analysis, you might already have a graph or even a model provider (including a graph) passed to the stage you are developing. In other cases, you will have to create new model provider and a new graph by yourself, or initialize a graph from a given Neo4j database directory on the file system. An example class where a graph and a model provider are initialized can be found here. The following sections will describe the ways to create and use both, a graph and a model provider.
If you don't already have a graph, there is a class called GraphLoader which will make it easy for you to get a graph from an existing Neo4j database directory on your hard drive, to create a new, empty graph in a directory on your hard drive, or to initialize a new graph with a Palladio model you might have.
As you already know, a Neo4j graph database is stored in a single folder on your file system. This implementation stores each of the 5 Palladio models in its own graph database, i.e. in its own folder. Additionally, different variants of each model are supported, which are stored in different graph databases, i.e. in different folders. To keep all these different models and their versions ordered, the graph loader uses the following file system structure. An arbitrary root directory is passed via the constructor of the graph loader.
GraphLoader graphLoader = new GraphLoader(new File("./basedir"));In this base directory, the graph loader will create subfolders for the different model types: basedir/repositorymodel, basedir/systemmodel, basedir/resourceenvironmentmodel and basedir/usagemodel. In such a subfolder, the different versions of the particular model are stored in folders named by the model type and the version, for example basedir/repositorymodel/repositorymodel_v1, basedir/repositorymodel/repositorymodel_v2 and so on. Note that these subfolders are not created all at once initially, but only when they are needed, i.e. when you call the appropriate method of the graph loader.
If you want to create a brand new database or if you already have a database in one of the described folders you can load the graph with the get...ModelGraph method. Let's assume that you want to get a repository model graph:
Graph repositoryModelGraph = graphLoader.getRepositoryModelGraph();If there already are database variant folders in the /basedir/repositorymodel/ directory, this method will return the graph from the folder with the highest version number. If there are no variant folders in the basedir/repositorymodel directory yet, this method will create a new database variant folder and return its empty graph.
If you already have a Palladio model and want to store it in a graph, you can also use the initialize...Modelgraph method which will store the model in the graph and return the graph including the model:
Repository repository = ...;
Graph repositoryModelGraph = graphLoader.initializeRepositoryModelGraph(repository);Note that in this case an existing model in the graph's folder will be overwritten.
As you should have a graph by now, you can finally take a look at the most important component of this implementation, the model provider. You can always create a new object of type ModelProvider with its constructor. The following code creates a new model provider for the repository component of the PCM:
ModelProvider<Repository> modelProvider = new ModelProvider<>(repositoryModelGraph);Note that you have to specify the type of the PCM component and the graph where you want to store it to or read it from. The Repository component is the root of the PCM repository model, so it contains everything what is contained in this model. However, you might just be interested in certain parts of a model and don't want to always read the whole thing. For example, instead of reading the whole repository model, you maybe just want to read a certain operation interface. No Problem, just create a suitable model provider:
ModelProvider<OperationInterface> modelProvider = new ModelProvider<>(repositoryModelGraph);Once you have a model provider, you can access the model with the provider's interface methods. For example you could read an operation interface by its id:
OperationInterface readInter = modelProvider.readOnlyComponentById(OperationInterface.class, <id>);Note that the readOnly... methods are meant for read-only access. That means, they will not lock the graph for other model providers. A common workflow is to read a component from the graph, modify it, and then update it in the graph. Even though each individual operation on the graph, i.e. the Neo4j graph database, is transactional, there is still a chance of lost updates if two model providers read the same component from the database, modify the read component separately, and write the modified components back. Then the second model provider would overwrite the changes of the first one. Therefore a model provider's read... methods (without "only") will lock the graph for other providers until a writing method (one of create/update/delete) has been called. Take care which version you use, because using a read... method instead of a readOnly... method for read-only purposes will cause a deadlock if you try to access the same graph with a different model provider afterwards.
These were the most important parts of this project and their functionality. For more information on the different methods or classes refer to the Javadoc or take a look at the source code. The general implementation concepts are described in the next section and might be helpful if you choose to look at the source code.
This section describes the concepts behind the different components of the knowledge repository.
To represent PCM models in the graph the following mapping was defined:
- An EObject is represented as a node, its EAttributes are represented as properties of the node and its concrete type (e.g. Repository, OperationInterface, ...) is represented as a label.
- An EReference is represented as a relationship, the name of the EReference and its position (in a list of references) are stored as properties and additionally the RelationshipType stores if it is a containment (CONTAINS), a reference (REFERENCES) or a reference to a datatype (IS_TYPE).
In the PCM there are only two types of references between two EObjects: Containments and simple references. Even though datatypes are referenced with simple references in the PCM, I choose to use IS_TYPE as a third relationship type here to enable partial access. To access a certain subcomponent in a model, the component itself and all its containments have to be accessed. Datatypes are usually containments of the root component of a model. However, as the knowledge repository supports partial access, the root component shall not always be accessed. For this reason the IS_TYPE relationships enable us to access datatypes easily without having to access the root component.
This class contains the logic to create, read, update or delete EObjects in the graph database. The key feature of this class is that it is generic, i.e. all types and subtypes of PCM components are generally treated the same way. The class provides a number of public methods to interact with a graph but generally there are just a few private core methods which are used by all public methods. They are:
- createNodes, which takes a PCM component (an EObject), creates a node for it and recursively creates nodes and relationships between them in the graph for all containments of the component. If a referenced component is no containment but is representing a datatype in the PCM model, it is handled the same way. A referenced component which is neither a containment nor a datatype is also stored as a node but its references are not stored anymore. This is what we call a proxy node, because usually you would call the create method with the root component of a PCM model and all components which are neither containments nor datatypes are proxy components from different models. Additionally all nodes get a URI depending on its position from the root component, which is used for proxy nodes and in the updateNodes method. The recursion stops if a node which already exists in the graph is reached.
- readNodes, which takes a starting node and recursively reads all its contained nodes and possible datatype nodes from the graph. For each node that is read, an EObject of the particular type is created with the appropriate EMF factory method. For proxy nodes, the proxy URI of the created EObject it explicitly set to the URI stored in the node. However, the automatic proxy resolving as it is provided by the EMF does not work yet. This mechanism would automatically replace proxy Objects by their real counterparts when they were accessed directly. However, this whole mechanism is based on the storage of models in files as it is the default EMF serialization strategy and will not work with the Neo4j database. The recursion ends if a node is reached for which already an EObject has been initialized.
- updateNodes, which takes a component (an EObject) and the corresponding node and updates the node to match the possibly modified component. This method recursively traverses through all containments or datatypes of a component. For each new recursion call, the node matching the next component is found from the nodes referenced from the current recursion's node with the URI every node got in the createNodeMethod. If no matching node could be found, a new one is created with the createNodeMethod. Nodes that represent components which were removed are removed as well.
- deleteComponentNodes, which takes a starting node and recursively traverses through all containments and deletes them.
- deleteComponentAndDatatypeNodes, which takes a starting node and recursively traverses through all containments and datatypes and deletes them. Additionally nodes which are not referenced from anywhere else are deleted. Deleting the datatype nodes is a more complex task which was realized with the three helper methods markAccessibleNodes, markDeletableNodes, deleteMarkedNodes because datatypes often reference to each other which results in circles.
Graph is a container class, which includes the Neo4j GraphDatabaseService object on one hand and its storage path in the file system on the other hand. Additionally, a shutdown hook for the GraphDatabaseService is registered to make sure that the database is always shut down correctly when the virtual machine exits.
This class is responsible for loading graphs, initializing graphs with given models or creating new versions of a graph. The basis for these methods is a predefined structure on the file system as described in the previous section. The core methods of the class are the private methods
- cloneNewModelGraphVersion, which takes the name of the model type directory, finds the highest current variant number in that directory and copies the subdirectory with the highest variant number to a new one with incremented variant number. Finally, it instantiates and returns a graph from the new directory.
- getModelgraphVersion, which takes the name of the model type directory, finds the highest current variant number in that directory and finally instantiates and returns a graph from the subdirectory with the highest variant number.
This class implements a locking mechanism for graphs to make sure that only one model provider at a time is allowed to modify a certain graph. It uses a static map of graphs to model providers to store which model provider currently has the lock of a certain graph. It is called from the model provider's methods and provides the two static methods
- getLock, which takes a model provider, gets its graph and suspends if there is already another model provider registered for that graph in the map. Otherwise the passed model provider is put to the map and the method exits.
- releaseLock, which takes a model provider, gets its graph, removes it from the map if it was the one holding the lock and notifies a model provider suspended on the given graph.
All tests for the model provider so far are developed using JUnit 4 and are working with small models to reduce unnecessary overhead. A common approach for many test cases is to write a model in to the graph database, then read it from the database and check if the written model equals the read model.
To check whether two EObjects are structurally equal, the EMF provides the static method org.eclipse.emf.ecore.util.EcoreUtil.equals(EObject o1, EObject o2). This method internally uses a class called EqualityHelper to compare the objects. However, this class was not perfect for this use case as a result of the following reasons:
- As described above, the EMF proxy resolving mechanism is not working with the knowledge repository yet, which resulted in problems when proxy objects were compared.
- Two lists of references of an EObject were compared entry by entry. For this reason they were only considered equal if they were in the same order. However, in the PCM there are unordered lists in some components. Debugging showed that these lists are of the type CDOObjectImpl$CDOStoreUnorderedEList and that even though the database stores the order of a list no matter if its ordered or not, these lists could not be guaranteed to have the same order in the written and in the read model.
To solve these issues a class called Neo4jEqulalityHelper was implemented which overwrites the original EqualityHelper and adapts to these problems:
- The equals method for EObjects was overwritten and adapted in a way that for proxy nodes only the attributes have to be equal.
- The equals method for Lists of EObjects was overwritten and adapted in a way that instead of comparing lists entry by entry, lists are now considered equal if for every entry in list 1 there is an equal entry in list 2.
To test the model provider with all different PCM models, an example model was created programmatically. It represents a bookstore application where users can search for books by entering search queries. These search queries are then processed, optimized and used to find a matching book in the store's catalog. The application also enables the user to pay for the book if they wants to buy it. A class called TestModelBuilder was used in the test cases to build a new model for every test case.
The repository model contains the following components:
- queryInputComponent, which is for the input of a search query to the bookstore.
- queryProcessingComponent, which is for processing and optimizing the entered search query.
- catalogSearchComponent, which is for the search in the catalog with a given query.
- orderComponent, which includes the queryProcessingComponent the catalogSearchComponent.
-
paymentComponent, which is for the payment of a chosen book.
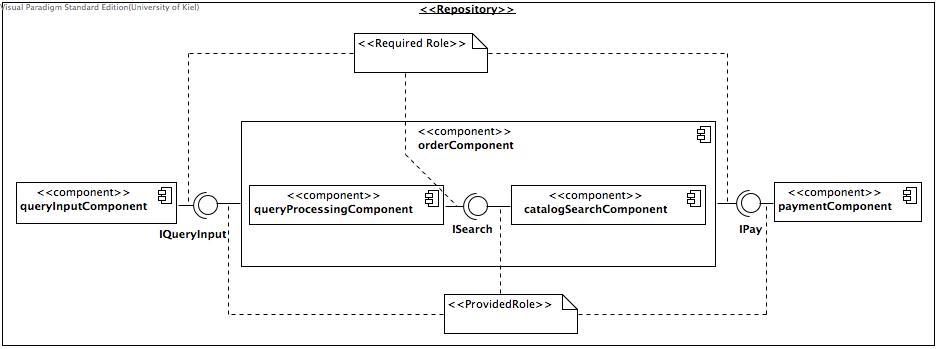 All components provide and require different roles. Each role provides or requires a certain interface and every interface contains its method signatures.
All components provide and require different roles. Each role provides or requires a certain interface and every interface contains its method signatures.
The system model contains the following assembly contexts:
- queryInputContext, which is the context in which the queryInputComponent is used.
- businessOrderContext, which is a context for using the orderComponent for business customers.
- privateOrderContext, which is a context for using the orderComponent for private customers.
-
paymentContext, which is the context for using the paymentComponent.
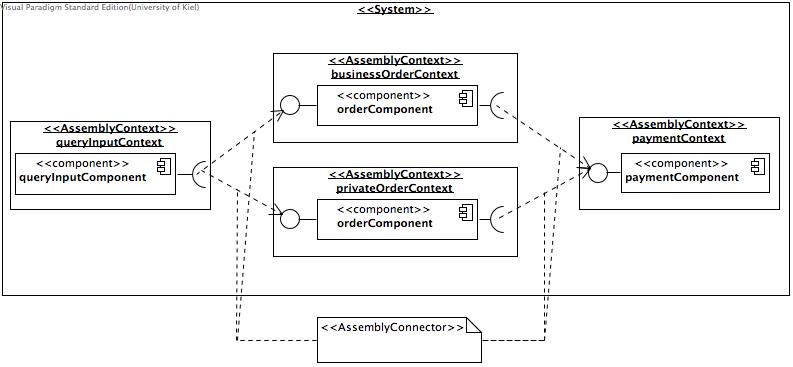 All contexts are connected with assembly connectors which also link the provided and required roles from the repository model to the connection.
All contexts are connected with assembly connectors which also link the provided and required roles from the repository model to the connection.
The resource environment model contains the following containers and linking resources:
- user0815's MacBook, which is a client's machine.
- user0816's ThinkPad, which is also a client's machine.
- orderServer, which is a server of the bookstore operator.
- paymentServer, which is another server of the bookstore operator.
-
lan-1, which is the network of the bookstore operator and links orderServer and paymentServer.
 All components also have their specifications attached to them.
All components also have their specifications attached to them.
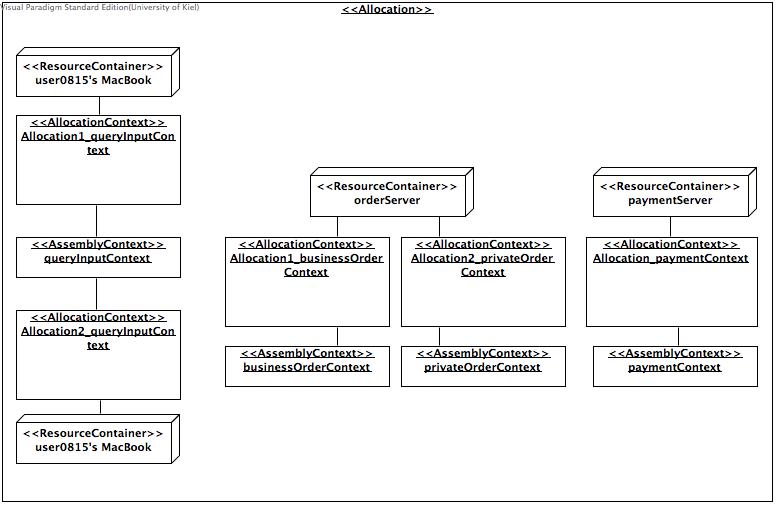
The allocation model contains the following allocation contexts which link a hardware component to an execution context:
- Allocation1_queryInputContext, which allocates user0815's MacBook for the queryInputContext.
- Allocation2_queryInputContext, which allocates user0816's ThinkPad for the queryInputContext.
- Allocation1_businessOrderContext, which allocates the orderServer for the businessOrderContext.
- Allocation2_privateOrderContext, which allocates the orderServer for the privateOrderContext.
-
Allocation_paymentContext, which allocaten the paymentServer for the paymentContext.
The usage model finally contains the following actions in a single scenario behavior (Buy a book) in a single usage scenario (Usage scenario of user group 0):
- startScenario, when the scenario starts.
- getQueryCall, getPriceCall, withdrawCall, which all three link the called method signature, the provided role and the previous and following actions.
-
stopScenario, when the scenario stops.
 Further specifications are attached to the usage scenario.
Further specifications are attached to the usage scenario.
So far, there is a test class for every model of the five PCM models. Each class contains test cases for all methods of a model provider's interface. However, so far only the readOnly... methods are tested. The synchronization with the ModelProviderSynchronzer class is not tested explicitly yet. If you have read the previous section about the bookstore models you will also notice that in some test cases the models are modified and updated in different ways (e.g. different payment methods, different allocations, ...) in the test cases.
This log was created during the implementation and documents the development process.
The goal is to gain a general idea of the technologies to be used. Inspect the Palladio metamodel and iObserve analysis, get familiar with Neo4J and set everything up. A small prototype (can be found here) was implemented to get familiar with Neo4J and to get a first impression of how models could be mapped to graphs. This prototype can be expanded in the future to test features in a small environment.
In this step the main focus is on
- serializing the different types of Palladio models in a Neo4J graph
- deserializing such a graph back to a model
For this reason a mapping from model to graph must be defined and implemented. The implementation takes place on this branch.
The API shall provide access to the Neo4J graph database and provide an alternative approach to the existing implementation which uses files to store the models and model provider classes to access them. Key features of the new API will be:
- CRUD Operations: The API shall provide basic CRUD operations.
- Basic versioning (variants): The database shall include the current version of the models as well as several modified version of this current models resulting from the analysis.
- Partial access: Instead of always having to read the complete model from the database, requesting single parts shall be possible.
All operations finally provided by the API have to be tested to make sure they work as intended and, for example, do not damage the models.
Goals:
- 1.6.
+ Implement partial create/read methods for repository model (reading without datatypes)- 8.6.
+ Implement read with datatypes- 15.6.
+ Implement delete
+ Test compatibility to other model types- 22.6.
+ Fix compatibility to other model types
+ Implement update (using delete and create)
+ Reimplement old providers with new api for compatibility - 29.6.
- use emf proxy mechanism for references to other models
+ writing: store uri relative to root in the graph
+ reading: create "proxy object" using the uri stored in the node
- with partial reading no Resource objects are created so emf proxy mechansim is not 100% applicable
+ Come up with a concept for model versioning- 6.7.
+ Create concept for the basic lock mechanism with read-only and read-and-edit methods we discussed
+ Implement versioning- 13.7.
+ Implement basic lock mechanism
+ New update method (no longer delete + create) which now also works correctly with partial updates- 20.7.
+ Learn for exams (17.7. + 21.7.)- 27.7.
+ Learn for exam (26.7.)- 3.8. until 30.9.
+ Write tests
+ Write wiki
+ Fix bugs