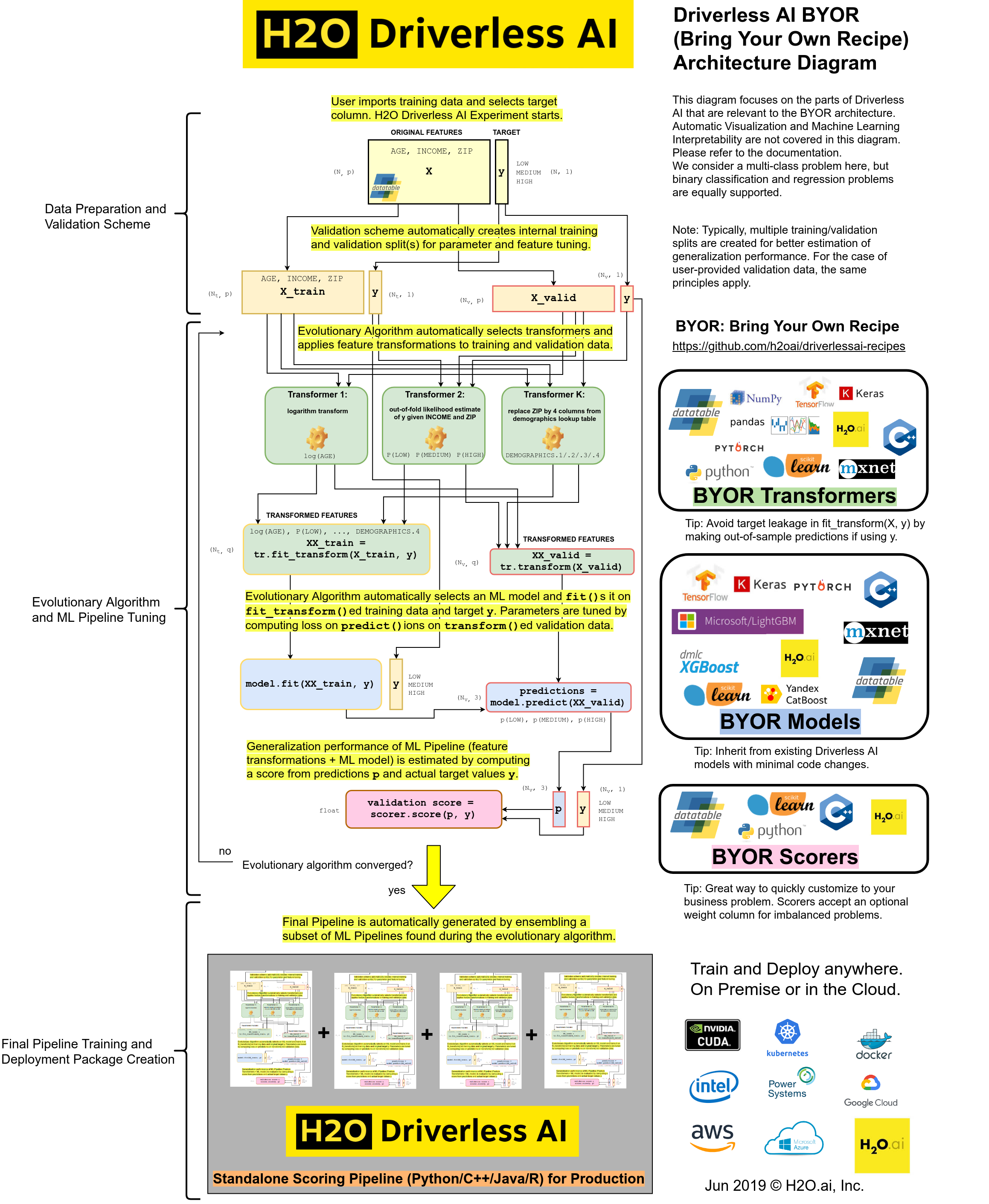
H2O Driverless AI is Automatic Machine Learning for the Enterprise. Driverless AI automates feature engineering, model building, visualization and interpretability.
- Learn more about Driverless AI from the H2O.ai website
- Take the test drive
- Go to the Driverless AI community Slack channel and ask your BYOR related questions in #general
BYOR stands for Bring Your Own Recipe and is a key feature of Driverless AI. It allows domain scientists to solve their problems faster and with more precision.
Custom recipes are Python code snippets that can be uploaded into Driverless AI at runtime, like plugins. No need to restart Driverless AI. Custom recipes can be provided for transformers, models and scorers. During training of a supervised machine learning modeling pipeline (aka experiment), Driverless AI can then use these code snippets as building blocks, in combination with all built-in code pieces (or instead of). By providing your own custom recipes, you can gain control over the optimization choices that Driverless AI makes to best solve your machine learning problems.
-
Recipes are meant to be built by people you trust and each recipe should be code-reviewed before going to production.
-
Assume that a user with access to Driverless AI has access to the data inside that instance.
- Apart from securing access to the instance via private networks, various methods of authentication are possible. Local authentication provides the most control over which users have access to Driverless AI.
- Unless the
config.tomlsettingenable_dataset_downloading=falseis set, an authenticated user can download all imported datasets as .csv via direct APIs.
-
When recipes are enabled (
enable_custom_recipes=true, the default), be aware that:- The code for the recipes runs as the same native Linux user that runs the Driverless AI application.
- Recipes have explicit access to all data passing through the transformer/model/scorer API
- Recipes have implicit access to system resources such as disk, memory, CPUs, GPUs, network, etc.
- A H2O-3 Java process is started in the background, for use by all recipes using H2O-3. Anyone with access to the Driverless AI instance can browse the file system, see models and data through the H2O-3 interface.
- The code for the recipes runs as the same native Linux user that runs the Driverless AI application.
-
Best ways to control access to Driverless AI and custom recipes:
- Control access to the Driverless AI instance
- Use local authentication to specify exactly which users are allowed to access Driverless AI
- Run Driverless AI in a Docker container, as a certain user, with only certain ports exposed, and only certain mount points mapped
- To disable all recipes: Set
enable_custom_recipes=falsein the config.toml, or add the environment variableDRIVERLESS_AI_ENABLE_CUSTOM_RECIPES=0at startup of Driverless AI. This will disable all custom transformers, models and scorers. - To disable new recipes: To keep all previously uploaded recipes enabled and disable the upload of any new recipes, set
enable_custom_recipes_upload=falseorDRIVERLESS_AI_ENABLE_CUSTOM_RECIPES_UPLOAD=0at startup of Driverless AI.
- Driverless AI automatically performs basic acceptance tests for all custom recipes unless disabled
- More information in the FAQ
- Use fast and efficient data manipulation tools like
data.table,sklearn,numpyorpandasinstead of Python lists, for-loops etc. - Use disk sparingly, delete temporary files as soon as possible
- Use memory sparingly, delete objects when no longer needed
{kind=link}
Go to Recipes for Driverless 1.7.0
- HOW_TO_WRITE_A_RECIPE
- MODELS
- model_template.py [Template base class for a custom model recipe.]
- ALGORITHMS
- catboost.py [CatBoost gradient boosting by Yandex. Currently supports regression and binary classification.]
- daal_trees.py [Binary Classification and Regression for Decision Forest and Gradient Boosting based on Intel DAAL]
- extra_trees.py [Extremely Randomized Trees (ExtraTrees) model from sklearn]
- h2o-3-models.py [H2O-3 Distributed Scalable Machine Learning Models (DL/GLM/GBM/DRF/NB/AutoML)]
- h2o-glm-poisson.py [H2O-3 Distributed Scalable Machine Learning Models: Poisson GLM]
- knearestneighbour.py [K-Nearest Neighbor implementation by sklearn. For small data (< 200k rows).]
- libfm_fastfm.py [LibFM implementation of fastFM ]
- linear_svm.py [Linear Support Vector Machine (SVM) implementation by sklearn. For small data.]
- nusvm.py [Nu-SVM implementation by sklearn. For small data.]
- random_forest.py [Random Forest (RandomForest) model from sklearn]
- CUSTOM_LOSS
- lightgbm_with_custom_loss.py [Modified version of Driverless AI's internal LightGBM implementation with a custom objective function (used for tree split finding).]
- xgboost_with_custom_loss.py [Modified version of Driverless AI's internal XGBoost implementation with a custom objective function (used for tree split finding).]
- TIMESERIES
- exponential_smoothing.py [Linear Model on top of Exponential Weighted Moving Average Lags for Time-Series. Provide appropriate lags and past outcomes during batch scoring for best results.]
- fb_prophet.py [Prophet by Facebook for TimeSeries with an example of parameter mutation.]
- fb_prophet_parallel.py [Prophet by Facebook for TimeSeries with an example of parameter mutation.]
- historic_mean.py [Historic Mean for Time-Series problems. Predicts the mean of the target for each timegroup for regression problems.]
- RECIPES
- amazon.py [Recipe for Kaggle Competition: Amazon.com - Employee Access Challenge]
- REFERENCE
- SCORERS
- huber_loss.py [Huber Loss for Regression or Binary Classification. Robust loss, combination of quadratic loss and linear loss.]
- scorer_template.py [Template base class for a custom scorer recipe.]
- CLASSIFICATION
- precision.py [Precision:
TP / (TP + FP). Binary uses threshold of 0.5 (please adjust), multiclass uses argmax to assign labels.] - recall.py [Recall:
TP / (TP + FN). Binary uses threshold of 0.5 (please adjust), multiclass uses argmax to assign labels.] - BINARY
- average_mcc.py [Averaged Matthews Correlation Coefficient (averaged over several thresholds, for imbalanced problems). Example how to use Driverless AI's internal scorer.]
- brier_loss.py [Brier Loss]
- cost.py [Using hard-coded dollar amounts x for false positives and y for false negatives, calculate the cost of a model using:
x * FP + y * FN] - false_discovery_rate.py [False Discovery Rate:
FP / (FP + TP)for binary classification - only recommended if threshold is adjusted`] - false_negative_count.py [Optimizes for specific Confusion Matrix Values:
FN- only recommended if threshold is adjusted] - false_positive_count.py [Optimizes for specific Confusion Matrix Values:
FP- only recommended if threshold is adjusted] - marketing_campaign.py [Computes the mean profit per outbound marketing letter, given a fraction of the population addressed, and fixed cost and reward]
- profit.py [Uses domain information about user behavior to calculate the profit or loss of a model.]
- true_negative_count.py [Optimizes for specific Confusion Matrix Values:
TN- only recommended if threshold is adjusted] - true_positive_count.py [Optimizes for specific Confusion Matrix Values:
TP- only recommended if threshold is adjusted]
- MULTICLASS
- hamming_loss.py [Hamming Loss - Misclassification Rate (1 - Accuracy)]
- quadratic_weighted_kappa.py [Qudratic Weighted Kappa]
- precision.py [Precision:
- REGRESSION
- cosh_loss.py [Hyperbolic Cosine Loss]
- explained_variance.py [Explained Variance. Fraction of variance that is explained by the model.]
- largest_error.py [Largest error for regression problems. Highly sensitive to outliers.]
- log_mae.py [Log Mean Absolute Error for regression]
- mean_absolute_scaled_error.py [Mean Absolute Scaled Error for time-series regression]
- mean_squared_error.py [Mean Squared Error for regression]
- mean_squared_log_error.py [Mean Squared Log Error for regression]
- median_absolute_error.py [Median Absolute Error for regression]
- pearson_correlation.py [Pearson Correlation Coefficient for regression]
- top_decile.py [Median Absolute Error for predictions in the top decile]
- TRANSFORMERS
- how_to_debug_transformer.py [Example how to debug a transformer outside of Driverless AI (optional)]
- how_to_test_from_py_client.py [Testing a BYOR Transformer the PyClient - works on 1.7.0 & 1.7.1-17]
- transformer_template.py [Template base class for a custom transformer recipe.]
- AUGMENTATION
- germany_landers_holidays.py [Returns a flag for whether a date falls on a holiday for each of Germany's Bundeslaender]
- ipaddress_features.py [Parses IP addresses and networks and extracts its properties.]
- is_ramadan.py [Returns a flag for whether a date falls on Ramadan in Saudi Arabia]
- singapore_public_holidays.py [Flag for whether a date falls on a public holiday in Singapore.]
- uszipcode_features_database.py [Lightweight transformer to parse and augment US zipcodes with info from zipcode database.]
- uszipcode_features_light.py [Lightweight transformer to parse and augment US zipcodes with info from zipcode database.]
- DATETIME
- datetime_diff_transformer.py [Difference in time between two datetime columns]
- datetime_encoder_transformer.py [Converts datetime column into an integer (milliseconds since 1970)]
- days_until_dec2020.py [Creates new feature for any date columns, by computing the difference in days between the date value and 31st Dec 2020]
- GENERIC
- count_missing_values_transformer.py [Count of missing values per row]
- missing_flag_transformer.py [Returns 1 if a value is missing, or 0 otherwise]
- specific_column_transformer.py [Example of a transformer that operates on the entire original frame, and hence on any column(s) desired.]
- GEOSPATIAL
- geodesic.py [Calculates the distance in miles between two latitude/longitude points in space]
- myhaversine.py [Computes miles between first two *_latitude and *_longitude named columns in the data set]
- IMAGE
- image_url_transformer.py [Convert a path to an image (JPG/JPEG/PNG) to a vector of class probabilities created by a pretrained ImageNet deeplearning model (Keras, TensorFlow).]
- NLP
- fuzzy_text_similarity_transformers.py [Row-by-row similarity between two text columns based on FuzzyWuzzy]
- text_embedding_similarity_transformers.py [Row-by-row similarity between two text columns based on pretrained Deep Learning embedding space]
- text_lang_detect_transformer.py [Detect the language for a text value using Google's 'langdetect' package]
- text_meta_transformers.py [Extract common meta features from text]
- text_sentiment_transformer.py [Extract sentiment from text using pretrained models from TextBlob]
- text_similarity_transformers.py [Row-by-row similarity between two text columns based on common N-grams, Jaccard similarity, Dice similarity and edit distance.]
- NUMERIC
- boxcox_transformer.py [Box-Cox Transform]
- count_negative_values_transformer.py [Count of negative values per row]
- count_positive_values_transformer.py [Count of positive values per row]
- exp_diff_transformer.py [Exponentiated difference of two numbers]
- log_transformer.py [Converts numbers to their Logarithm]
- product.py [Products together 3 or more numeric features]
- random_transformer.py [Creates random numbers]
- round_transformer.py [Rounds numbers to 1, 2 or 3 decimals]
- square_root_transformer.py [Converts numbers to the square root, preserving the sign of the original numbers]
- sum.py [Adds together 3 or more numeric features]
- yeojohnson_transformer.py [Yeo-Johnson Power Transformer]
- OUTLIERS
- h2o3-dl-anomaly.py [Anomaly score for each row based on reconstruction error of a H2O-3 deep learning autoencoder]
- quantile_winsorizer.py [Winsorizes (truncates) univariate outliers outside of a given quantile threshold]
- twosigma_winsorizer.py [Winsorizes (truncates) univariate outliers outside of two standard deviations from the mean.]
- STRING
- strlen_transformer.py [Returns the string length of categorical values]
- to_string_transformer.py [Converts numbers to strings]
- TARGETENCODING
- ExpandingMean.py [CatBoost-style target encoding. See https://youtu.be/d6UMEmeXB6o?t=818 for short explanation]
- leaky_mean_target_encoder.py [Example implementation of a out-of-fold target encoder (leaky, not recommended)]
- TIMESERIES
- auto_arima_forecast.py [Auto ARIMA transformer is a time series transformer that predicts target using ARIMA models]
- general_time_series_transformer.py [Demonstrates the API for custom time-series transformers.]
- normalized_macd.py [please add description]
- parallel_auto_arima_forecast.py [Parallel Auto ARIMA transformer is a time series transformer that predicts target using ARIMA models.In this implementation, Time Group Models are fitted in parallel]
- parallel_prophet_forecast.py [Parallel FB Prophet transformer is a time series transformer that predicts target using FBProphet models.In this implementation, Time Group Models are fitted in parallel]
- serial_prophet_forecast.py [Transformer that uses FB Prophet for time series prediction.Please see the parallel implementation for more information]
- time_encoder_transformer.py [please add description]
- trading_volatility.py [Calculates Historical Volatility for numeric features (makes assumptions on the data)]