forked from opea-project/GenAIComps
-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
add telemetry doc (opea-project#536)
Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com>
- Loading branch information
1 parent
fb43647
commit e0a3767
Showing
1 changed file
with
121 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,121 @@ | ||
| # Telemetry for OPEA | ||
|
|
||
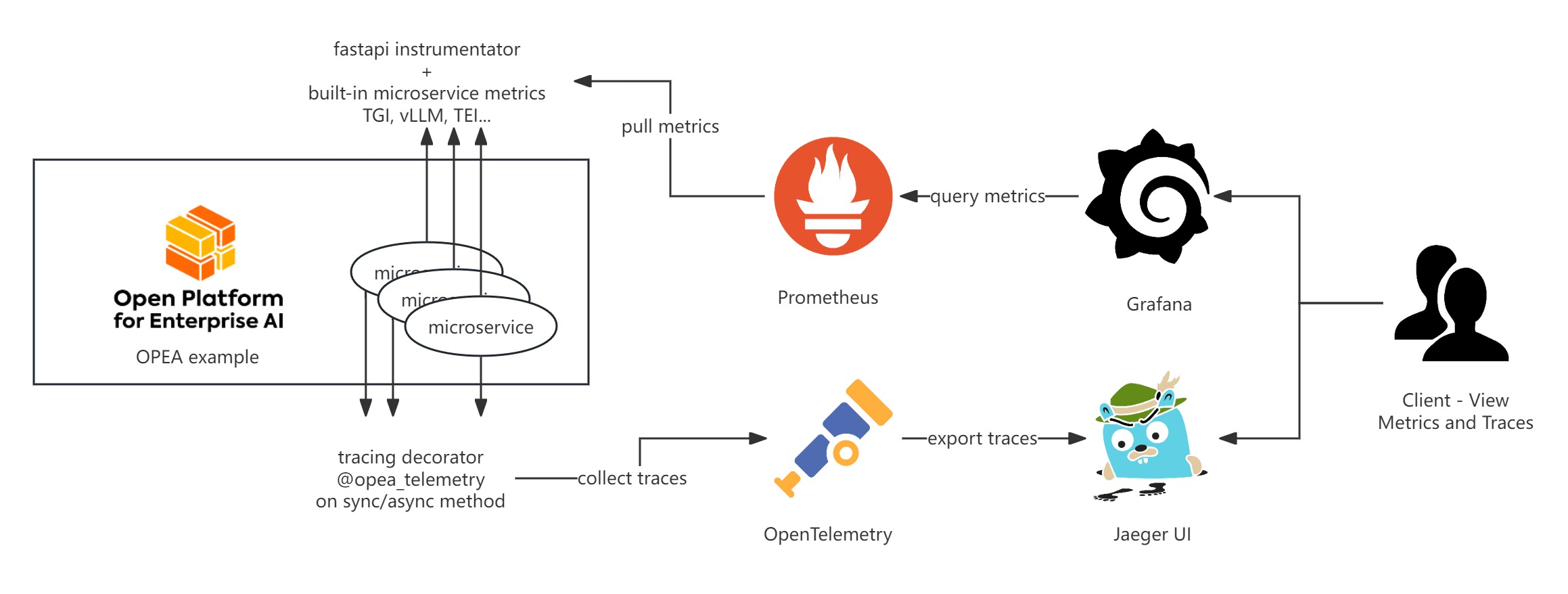
| OPEA Comps currently provides telemetry functionalities for metrics and tracing using Prometheus, Grafana, and Jaeger. Here’s a basic introduction to these tools: | ||
|
|
||
|  | ||
|
|
||
| ## Metrics | ||
|
|
||
| OPEA microservice metrics are exported in Prometheus format and are divided into two categories: general metrics and specific metrics. | ||
|
|
||
| General metrics, such as `http_requests_total `, `http_request_size_bytes`, are exposed by every microservice endpoint using the [prometheus-fastapi-instrumentator](https://github.com/trallnag/prometheus-fastapi-instrumentator). | ||
|
|
||
| Specific metrics are the built-in metrics exposed under `/metrics` by each specific microservices such as TGI, vLLM, TEI and others. Both types of the metrics adhere to the Prometheus format. | ||
|
|
||
| ### General Metrics | ||
|
|
||
| To access the general metrics of each microservice, you can use `curl` as follows: | ||
|
|
||
| ```bash | ||
| curl localhost:{port of your service}/metrics | ||
| ``` | ||
|
|
||
| Then you will see Prometheus format metrics printed out as follows: | ||
|
|
||
| ```yaml | ||
| HELP http_requests_total Total number of requests by method, status and handler. | ||
| # TYPE http_requests_total counter | ||
| http_requests_total{handler="/metrics",method="GET",status="2xx"} 3.0 | ||
| http_requests_total{handler="/v1/chatqna",method="POST",status="2xx"} 2.0 | ||
| ... | ||
| # HELP http_request_size_bytes Content length of incoming requests by handler. Only value of header is respected. Otherwise ignored. No percentile calculated. | ||
| # TYPE http_request_size_bytes summary | ||
| http_request_size_bytes_count{handler="/metrics"} 3.0 | ||
| http_request_size_bytes_sum{handler="/metrics"} 0.0 | ||
| http_request_size_bytes_count{handler="/v1/chatqna"} 2.0 | ||
| http_request_size_bytes_sum{handler="/v1/chatqna"} 128.0 | ||
| ... | ||
| ``` | ||
|
|
||
| ### Specific Metrics | ||
|
|
||
| To access the metrics exposed by each specific microservice, ensure that you check the specific port and your port mapping to reach the `/metrics` endpoint correctly. | ||
|
|
||
| For example, you can `curl localhost:6006/metrics` to retrieve the TEI embedding metrics, and the output should look like follows: | ||
|
|
||
| ```yaml | ||
| # TYPE te_embed_count counter | ||
| te_embed_count 7 | ||
|
|
||
| # TYPE te_request_success counter | ||
| te_request_success{method="batch"} 2 | ||
|
|
||
| # TYPE te_request_count counter | ||
| te_request_count{method="single"} 2 | ||
| te_request_count{method="batch"} 2 | ||
|
|
||
| # TYPE te_embed_success counter | ||
| te_embed_success 7 | ||
|
|
||
| # TYPE te_queue_size gauge | ||
| te_queue_size 0 | ||
|
|
||
| # TYPE te_request_inference_duration histogram | ||
| te_request_inference_duration_bucket{le="0.000015000000000000002"} 0 | ||
| te_request_inference_duration_bucket{le="0.000022500000000000005"} 0 | ||
| te_request_inference_duration_bucket{le="0.00003375000000000001"} 0 | ||
| ``` | ||
|
|
||
| These metrics can be scraped by the Prometheus server into a time-series database and further visualized using Grafana. | ||
|
|
||
| Below are some default metrics endpoints for specific microservices: | ||
|
|
||
| | component | port | endpoint | metircs doc | | ||
| | ------------- | ----- | -------- | ------------------------------------------------------------------------------------------------------- | | ||
| | TGI | 80 | /metrics | [link](https://huggingface.co/docs/text-generation-inference/en/basic_tutorials/monitoring) | | ||
| | milvus | 9091 | /metrics | [link](https://milvus.io/docs/monitor.md) | | ||
| | vLLM | 18688 | /metrics | [link](https://docs.vllm.ai/en/v0.5.0/serving/metrics.html) | | ||
| | TEI embedding | 6006 | /metrics | [link](https://huggingface.github.io/text-embeddings-inference/#/Text%20Embeddings%20Inference/metrics) | | ||
| | TEI reranking | 8808 | /metrics | [link](https://huggingface.github.io/text-embeddings-inference/#/Text%20Embeddings%20Inference/metrics) | | ||
|
|
||
| ## Tracing | ||
|
|
||
| OPEA use OpenTelemetry to trace function call stacks. To trace a function, add the `@opea_telemetry` decorator to either an async or sync function. The call stacks and time span data will be exported by OpenTelemetry. You can use Jaeger UI to visualize this tracing data. | ||
|
|
||
| By default, tracing data is exported to `http://localhost:4318/v1/traces`. This endpoint can be customized by editing the `TELEMETRY_ENDPOINT` environment variable. | ||
|
|
||
| ```py | ||
| from comps import opea_telemetry | ||
|
|
||
|
|
||
| @opea_telemetry | ||
| async def your_async_func(): | ||
| pass | ||
|
|
||
|
|
||
| @opea_telemetry | ||
| def your_sync_func(): | ||
| pass | ||
| ``` | ||
|
|
||
| ## Visualization | ||
|
|
||
| ### Visualize metrics | ||
|
|
||
| Please refer to [OPEA grafana](https://github.com/opea-project/GenAIEval/tree/main/evals/benchmark/grafana) to get the details of Prometheus and Grafana server setup. The Grafana dashboard JSON files are also provided under [OPEA grafana](https://github.com/opea-project/GenAIEval/tree/main/evals/benchmark/grafana) to visualize the metrics. | ||
|
|
||
| ### Visualize tracing | ||
|
|
||
| Run the following command to start the Jaeger server. | ||
|
|
||
| ```bash | ||
| docker run -d --rm \ | ||
| -e COLLECTOR_ZIPKIN_HOST_PORT=:9411 \ | ||
| -p 16686:16686 \ | ||
| -p 4317:4317 \ | ||
| -p 4318:4318 \ | ||
| -p 9411:9411 \ | ||
| jaegertracing/all-in-one:latest | ||
| ``` | ||
|
|
||
| Access the dashboard UI at `localhost:16686`. |