Data Analysis FAQ
CxAnalytix outputs data related to vulnerabilities as they are detected and remediated over time. This means it is technically time-series data. Time series data, as a basic definition, is periodically recording values that change over time. Each recorded value can be referred to as a "sample".
This generally causes some confusion as most people are accustomed to analyzing business data that essentially only records the current state of the business (e.g. "Give me a A/R report showing me a list of customers that have outstanding balances, grouping the past-due amounts in 30/60/90 day buckets.") Most of this data is organized in a relational form that is selected by understanding the relational linkage between multiple entities. The pre-requisite for extracting meaning from data organized relationally would be to understand which entities are related.
The CxAnalytix data is generally "flat" output (with a few exceptions); this means there is no knowledge required to understand the relationship between entities. Each record (or "sample") has all values required for the context of the record without needing to understand any relationships between entities. The technique for deriving meaning from the data is to understand the filtering criteria needed to reduce the data set to show only the data needed for analysis. Often this filtering is performed as a pipeline starting with the widest filtering criteria sending data through progressively narrower filtering criteria.
Performing analysis on vulnerability data requires a bit of knowledge about the circumstances by which data arrives. Most time series data is collected from sensors that are emitting samples on a somewhat predictable periodic basis; vulnerability data is not collected in the same manner.
The first thing to understand is that scans are not necessarily performed with a predictable cadence. Why is this?
- Scanning code on commit to a repository would require commits to a repository; developers don't always work on code in a particular repository, and they certainly do not have a regular pattern for committing code.
- Scheduled scans may fail or be delayed by lack of scanning resources.
- Ad-hoc scans may be interleaved between scans scheduled on a regular cadence.
- Code that is not under active development may not get scanned regularly.
There are several variables that affect how vulnerabilities can change over time. The most obvious one is that vulnerabilities appear and disappear based on code changes over time. If this were the only factor that caused changes in detected vulnerabilities, analysis would be easy. Consider:
- Upgrades to the SAST software can increase the coverage of languages, frameworks, APIs, and even coding techniques. Vulnerability count trends may reflect the level of scan accuracy that product changes introduce in the upgrade.
- Tuning of the Preset, Exclusions, and/or CxQL query can change what is detected in a scan.
- The submitted code can be changed to affect the scan results.
- In some integration scenarios, it is possible for developers to submit code to exclude files containing vulnerable code. The issue will appear to have been remediated due to a change in the build process that is not detected by static code analysis.
- Similarly, it is possible to inadvertently submit code that should not be scanned thus increasing the number of results.
- Errors in the management of the code may cause vulnerabilities that were previously fixed to reappear.
- Incremental scan results will likely differ significantly from full scan results.
To set expecations, it is important to note that code can change over time that is vulnerable to the same detected vulnerability. Humans may look at two sets of code and understand that it is the same code, but it is not a simple task to perform the same evaluation algorithmically. Identifying complete uniqueness of a particular vulnerability requires virtually no code changes over time. When developing software, however, it is often the case that the entirety of the code does not change every time it is scanned. The methods desribed here will provide a way to generate a unique identifier that is "unique enough" to trace the lifecycle of a specific vulnerability.
This would require the use of the SAST Vulnerability Details record set. The samples in this record set contain the flattened path of each vulnerability and would therefore need to be filtered to reduce the number of samples for analysis. Filtering the samples where NodeId is 1 is usually sufficient to reduce the records for this type of analysis.
Most approaches make the wrong assumption that SimilarityId can be used to identify each vulnerability across scans. This does not work due to:
- Vulnerability paths for files that are copied to different paths will have the same
SimilarityId. - Vulnerability paths for files that are scanned in multiple projects will have the same
SimilarityId. - Code that is copy/pasted multiple times in the same file may have the same
SimilarityId. - Different vulnerabilities with the same start and end node in the data flow path will have the same
SimilarityId.
Identifying a specific vulnerability across scans depends on what is needed for your particular analysis. This may seem counterintuitive, but this is because it depends on how the SAST system is being used and what the analysis is trying to achieve. Generating a compound identifier using multiple data components will allow the vulnerability to be tracked in multiple scans.
To understand which components to select for the compound identifier, some explanation of the data elements is required.
Scans are executed under the context of a SAST project. It is possible that each project represents a unique code repository or multiple branches of a single code repository. ProjectId is a unique value for the concatenation of TeamName and ProjectName as a path. For example, "/CxServer/US/FinancialServices/ShoppingCart_master" has a team name of "/CxServer/US/FinancialServices" and a project name of "ShoppingCart_master".
The SAST server treats vulnerabilities with the same SimilarityId as a single vulnerability across all projects in the same team. Setting a vulnerability with the status of Not Exploitable in one project, for example, would result in the vulnerability being marked as Not Exploitable if the same file (or a copy of it) were scanned in another project on the same team.
Since vulnerabilities may have the same start and end node, a SimilarityId value may appear under multiple vulnerability categories (or even multiple times per category). The category roughly corresponds to the QueryName. Often, the use of QueryName as a component in a compound identifier would be sufficient for classification since most queries won't report results for the same QueryName that appear in a different QueryGroup with the same SimilarityId. This is usually the case given the result path is limited to a single language in all nodes of the data flow path.
It is possible, however, to have language agnostic results (such as TruffleHog) that give the same result for the same QueryName under each QueryGroup. Using both the QueryGroup and QueryName as part of the compound identifier would increase the identification accuracy.
One caveat is that QueryGroup is mainly a composition of QueryLanguage and the default QuerySeverity. Consider:
- The
QuerySeverityvalue can be adjusted via CxAudit. TheQueryGroupvalue will not change to reflect the adjustedQuerySeverityvalue. - The
ResultSeverityvalue defaults to theQuerySeverityvalue but can be adjusted on a per-result basis by users of the system. This is often done to reflect vulnerability remediation priority.
Using fields that have meanings that can change may produce some unexpected analysis results.
If you have multiple SAST instances and are aggregating the data into a single store, add InstanceId as part of the unique identifier.
This identifier will track the vulnerability across scans. It will potentially result in duplicate vulnerabilities in projects under the same team when counting total vulnerabilities.
For greater accuracy in tracking, consider adding the following fields:
QueryGroup-
QueryLanguage+QuerySeverity -
QueryLanguage+ResultSeverity
Using TeamName in place of ProjectId will effectively allow vulnerabilities to be assessed once for all projects on the team. There are some potential drawbacks:
- The same code in unrelated projects may be counted as one vulnerability for all projects in the team.
- Projects can be moved to different teams. Moving a project to a new team will change the timeline for the vulnerability given historical samples will reflect the team name at the time the sample was recorded.
- It may not be possible to determine when a vulnerability was resolved since it will require all projects in the team that report the vulnerability to perform a scan that no longer contains the vulnerability.
Why is the count of unique vulnerabilities different than the count of vulnerabilities found in the Scan Summary record?
This is usually due to a duplicate SimilarityId for multiple reported data flow paths causing fingerprinted vulnerabilities to coalesce into a single vulnerability. Vulnerabilities with the same SimilarityId are treated as the same vulnerability in SAST, even if each reported vulnerability flows through different code or exists in different files. This is mostly observed when triage changes for a vulnerability propagate across all projects on a team.
There are many reasons why duplicate SimilairtyId values will be generated. Copy/paste code, while not common in most code, can generate duplicate SimilarityId data flows. The duplicate data flows often occur when:
- The source and sink nodes for multiple distinct paths are the same.
- The source and sink nodes contain code that is the same.
Consider this code sample that produces 3 SQL Injection vulnerabilties:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Threading.Tasks;
using Microsoft.AspNetCore.Mvc;
using Microsoft.AspNetCore.Mvc.RazorPages;
using System.Data.SqlClient;
using System.IO;
using System.Text;
namespace webapp.Pages
{
public class IndexModel : PageModel
{
private String getField(String[] fields, int index)
{
return Request.Form[fields[index]];
}
public void OnPost()
{
String[] fieldNames = {"A", "B", "C"};
int curField = 0;
SqlConnection con = new SqlConnection();
String response = String.Empty;
String dbData = null;
dbData = new SQLCommand($"SELECT * FROM SomeTable WHERE SomeColumn = '{getField(fieldNames, curField)}'", con).ExecuteScalar();
if (dbData != null)
response += $"Field A: {dbData}<P>";
curField++;
dbData = new SQLCommand($"SELECT * FROM SomeTable WHERE SomeColumn = '{getField(fieldNames, curField)}'", con).ExecuteScalar();
if (dbData != null)
response += $"Field B: {dbData}<P>";
curField++;
dbData = new SQLCommand($"SELECT * FROM SomeTable WHERE SomeColumn = '{getField(fieldNames, curField)}'", con).ExecuteScalar();
if (dbData != null)
response += $"Field C: {dbData}<P>";
Response.Body.Write(new ReadOnlySpan<byte>(Encoding.UTF8.GetBytes (response.ToArray ()) ) );
}
}
}
The SQL Injection vulnerabilties have the same source line and a unique sink line, but the SimilarityId is the same for all vulnerabilities. This means that a triage change for only one vulnerabilitiy will apply it to all vulnerabilities with the same SimilarityId, as shown in the animation below:
Reviewing the XML report confirms the SimilarityId is the same for all SQL Injection data flow paths:
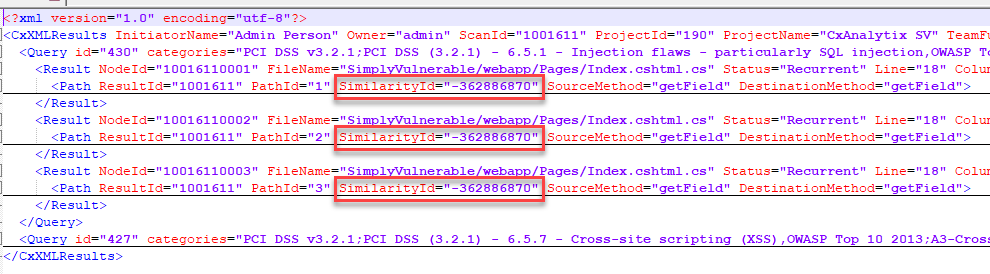
Fingerprinting vulnerabilities as "unique" as disussed in the previous FAQ section will coalesce vulnerabilities with duplicate SimilarityId into a single vulnerability in some cases. The reason for this is that the fields used to compose the vulnerability fingerprint will be the same for each vulnerability. In the example code above, the first node in each result path has the same values for NodeLine and NodeFileName. If those values were used as the segments in identifying the fingerprint, the vulnerabilities would calculate the same fingerprint.
From a code semantics perspective, the the fingerprinting method used to identify vulnerabilities may be unique enough. If the code involved in the vulnerability is so similar that it generates data flows that are nearly identical, isn't it the same vulnerability?
A code fix for only one data flow would leave the remaining data flows still vulnerable; this would mean the vulnerability is not completely remediated. If attempting to measure SLA compliance with the state of an open vulnerability, a complete fix is usually the desired outcome. The vulnerabilities in the example demonstrate that fixing one vulnerability would leave the others open and in need to remediation, which is usually going to be considered to be the correct state of a partial fix.
If you're interested in obtaining only deltas of vulnerability counts between scans to track changes, uniquely identifying vulnerabilities is likely not required.
When performing total calculations, it is often the case that the totals are grouped by severity. The QuerySeverity and ResultSeverity can be used for this grouping.
-
ResultSeverityis a value that can be changed during result triage. It defaults to theQuerySeverityvalue, but may be changed by a user. The project state view in the Checkmarx web client calculates totals using the result severity. -
QuerySeverityis the default severity of the query that can be changed by CxAudit query overrides.
The SAST UI totals will not count vulnerabilities marked as Not Exploitable, so filtering the Not Exploitable vulnerabilities from the counts would be require to get a match of the SAST UI.
The 'Status' field in the SAST Vulnerability Details record will have the value New to indicate the vulnerability has been detected for the first time in a scan for the project.
'Status' with the value of Recurrent means that this vulnerability has been reported previously for one or more scans in the same project. The vulnerability could be new to the most recent scan under some conditions:
- The vulnerability was previously remediated and then re-introduced into the code.
- Preset changes removed a query from previous scans before being changed again to add the query back into the latest scans.
- Exclusion adjustments change the scope of scanned code and removed the vulnerable code from a prior scan before being adjusted again to add the code back into recent scans.
One method is to find the vulnerability where the Status field is New. This works if and only if a sample was recorded the first time the vulnerability was detected. There are various scenarios where this may not happen:
- The report for the scan could not be retrieved at the time CxAnalytix performed the crawl for scans.
- Data retention has been run and the first scan was purged prior to CxAnalytix crawling the scans.
A more general method may be to use the compound identifier for tracking vulnerabilities across scans and determine which scan is associated with the sample containing the earliest value in the ScanFinished field.
As of SAST 9.3 and CxAnalytix 1.3.1, the field FirstDetectionDate is part of the data output specification. Scans executed prior to 9.3 will not have a valid value for FirstDetectionDate.
This depends on how your organization defines the criteria for a "resolved vulnerability".
First, some variable definitions:
- Let VT be the vulnerability that is tracked across multiple scans using the chosen composite identifier.
- Let 𝕊 be the set of scans having the same
ProjectIdfield value where at least one scan reports VT. - Let the subset 𝕊found be the subset of scans where VT is reported such that 𝕊found = {𝕊 | VT is reported} and 𝕊found ⊆ 𝕊.
Finding the date VT first appeared means finding
scan Sfound ∈ 𝕊found
with the earliest value for ScanFinished.
Given the subset of scans where VT is not reported 𝕊fixed = {𝕊 | not reporting VT} we know that if 𝕊fixed == ∅ (empty set) that the vulnerability is still outstanding.
If the most recent scan Slatest ∈ 𝕊 is also in 𝕊fixed
(Slatest ∈ 𝕊fixed), then we can find the scan
Sfixed ∈ 𝕊fixed with the earliest ScanFinished date to find the date
the vulnerability was remediated.
Note that it is possible for VT to be re-introduced to the code; while it may be rare, the result is that there are potentially multiple resolution dates. If Slatest ∉ 𝕊fixed, it can be assumed that the vulnerability was re-introduced and is still outstanding.
The detection method presented above will technically work for all cases at the expense of the accuracy of dates related to appearance and resolution. Your organization can decide how they would like to approach analysis for this case. If there is a need to find a more exact date of resolution, more advanced logic is needed.
For a basic method of dealing with vulnerability reappearance, the ScanFinished date for Sfound may still be considered the date VT first appeared for most tracking purposes. It must still hold that Slatest ∈ 𝕊fixed to indicate the vulnerability has been resolved.
Using the scan Smost-recent-found ∈ 𝕊found where the ScanFinished value is the most recent is the date where the search for the latest fix date can begin.
Find the scan where VT was most recently fixed
Smost-recent-fixed ∈ 𝕊fixed
by selecting Smost-recent-fixed with a ScanFinished value greater than that of
the ScanFinished value of Smost-recent-found
and the earliest value for all scans
S ∈ 𝕊fixed.
The ScanFinished value for Smost-recent-fixed is the latest date on which
VT was resolved.
As the code changes from scan to scan, it is possible the fields used in creating a fingerprint for the vulnerability may also change. Changes in the fingerprint may lead to the assumption that the vulnerability is "closed" since the vulnerability no longer appears in the scan. A new vulnerability will then appear as "open" given the new fingerprint has appeared.
FirstDetectionDate is created based on the query and SimilarityId. A scan may have multiple vulnerabilities reported having the same SimilarityId, therefore these results have the same FirstDetectionDate.
Methods for tracking the lifecycle of the vulnerability may need to consider this information to avoid resetting SLA aging constantly as code changes. In many cases, however, the use of the fingerprint is sufficient given that code may not change often enough to perpetually reset SLAs.
The Project Information is a sample of the current state of a project. The fields indicate the state of the project at the time CxAnalytix performed the crawl scans on each project.
If a project has had no scans executed since the previous crawl, there is effectively no change that has been imposed on the project. If one or more scans are executed since the previous crawl, the a Project Information sample will be recorded.