A simple working facial recognition program.
1. Install the dependencies
2. Download the pretrained models here: https://drive.google.com/file/d/0Bx4sNrhhaBr3TDRMMUN3aGtHZzg/view?usp=sharing
Then extract those files into models
3. Run main.py
Python3 (3.5 ++ is recommended)
opencv3
numpy
tensorflow ( 1.1.0-rc or 1.2.0 is recommended )
`python3 main.py` to run the program
`python3 main.py --mode "input"` to add new user. Start turning left, right, up, down after inputting the new name. Turn slowly to avoid blurred images
To achieve best accuracy, please try to mimick what I did here in this gif while inputting new subject:

--mode "input" to add new user into the data set
Project: Facial Recogition
This is a simple minified version of a bigger project I was working on this summer.
Facial Recognition Architecture: Facenet Inception Resnet V1
Pretrained model is provided in Davidsandberg repo
More information on the model: https://arxiv.org/abs/1602.07261
Face detection method: MTCNN
More info on MTCNN Face Detection: https://kpzhang93.github.io/MTCNN_face_detection_alignment/
Both of these models are run simultaneouslyx
Tensorflow: The infamous Google's Deep Learning Framework
OpenCV: Image processing (VideoCapture, resizing,..)
To keep this repo as simple as possible, I will probably have this "plug-in" in a seperate repo:
Given the constrain of the facenet model's accuracy, there are many ways you can improve accuracy in real world application. One of my suggestion would be to create a tracker for each detected face on screen, then run recognition on each of them in real time. Then, decide who is in each tracker after some number of frames (3 - 10 frames, depending on how fast your machine is). Keep doing the same thing until the tracker disappears or loses track. Your result can look somewhat like this:
{"Unknown" :3, "PersonA": 1, "PersonB": 20} ---> This tracker is tracking PersonB
This will definitely improve your program liability, because the result will most likely be leaning toward the right subject in the picture after some number of frames, instead of just deciding right away after 1 frame like you normally would. One benefit of this approach is that the longer the person stays in front of the camera, the more accurate and confident the result is, as confidence points get incremented over time. Also, you can do some multi-threading/processing tricks to improve performance.
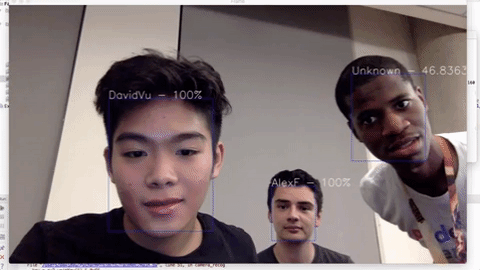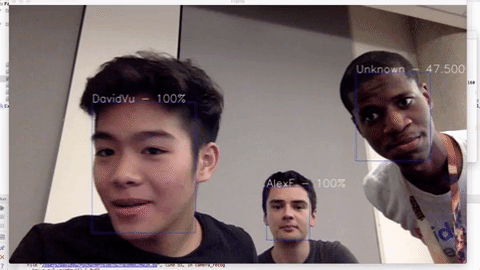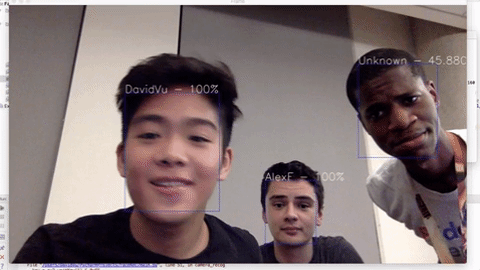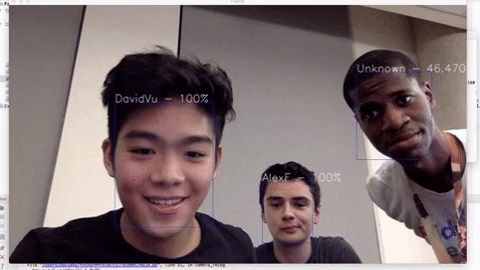
Live demo: https://www.youtube.com/watch?v=6CeCheBN0Mg
@Author: David Vu
- Pretrained models from: https://github.com/davidsandberg/facenet