{kind=link}
Nasdaq丹麦公司交易信息爬虫
I need you to go to: " http://www.nasdaqomxnordic.com/aktier ", check off large cap (so you only include small- and mid-cap) and open each company site and open the link "Fact sheet (in English)", which I have also attached for you to see.
From this factsheet I need the following newest information collected into excel (see attached excel sheet under "Nøgletal"):
"Name of the company"
"Market cap" on the first page under Key Stats
"Ebit (newest year)" on the first page under Financials
"Last Price" on the second page
"Cash and cash equivalents (newest year)", "current debt" and "long term debt" on the second page under Financial Position
"The summation of the most recent Earnings Per Share" on the second page under Quarterly Results
-
You should navigate to the
nasdapdenmarkfolder, have Chrome newest version installed and of course scrapy installed with selenium. -
This is an example start script
scrapy crawl spider -o output.csv -t csv -a market=nordic;cph -a segment=large;mid -a other=obs;lp -a sector=energy;mat -
argument splited by semicolon, you can use default value like this (
scrapy crawl spider -o output.csv -t csv -a market=nordic;cph -a segment=large;mid -a other=obs;lp), this will use default value forsectorargument. -
This is where the arguments come from
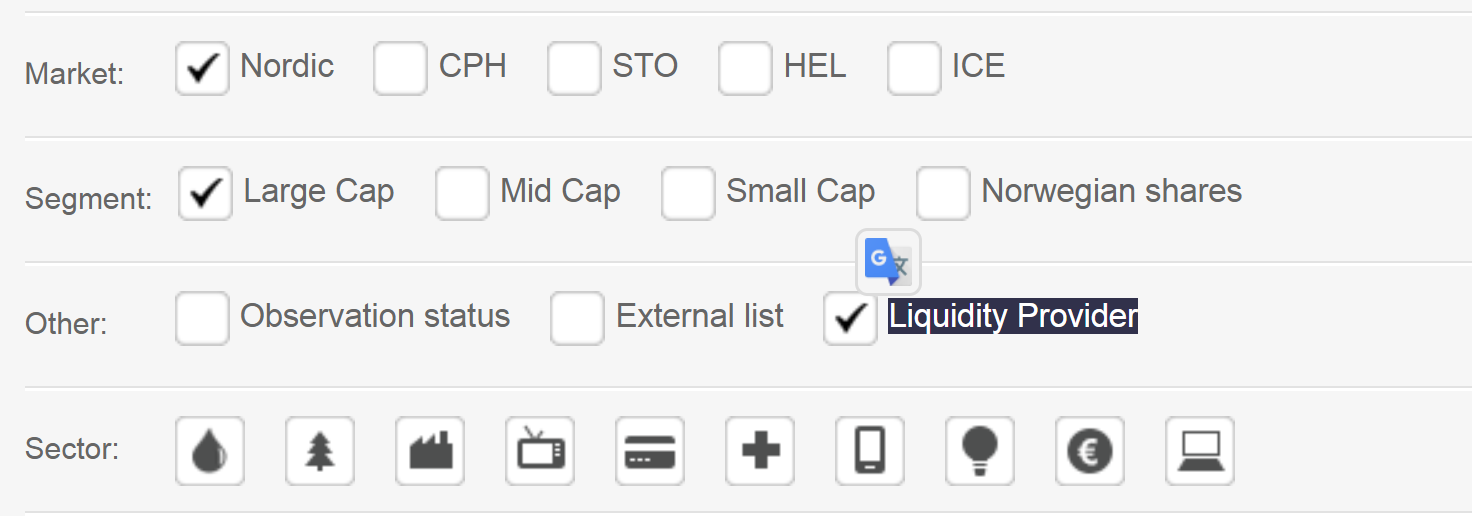
-
This is a table of all available arguments
market
value this argument refers to nordic Market: Nordic cph Market: CPH sto Market: STO hel Market: HEL ice Market: ICE segment
value this argument refers to large Large Cap mid Mid Cap small Small Cap nws Norwegian shares other
value this argument refers to obs Observation status extlist External list lp Liquidity Provider sector
value this argument refers to energy Energy and Oil mat Material industry Industry goods Consumer-Goods services Consumer-Services health healthy-care telecom telecommunication utility Utility finance Finance tech Technology