Jenkins
Jenkins is an automation server. Although commonly thought of as a CI/CD (continuous integration/continuous deployment) solution, Jenkins can automate nearly any task.
For the UN SDG National Reporting Initiative, Jenkins is used to automatically build and deploy the API to production, as well as run certain periodic tasks such as backing up the database.
Please see the section on AWS Setup if you're having trouble with AWS permissions when running jobs.
This section provides a quick overview of Jenkins jobs (i.e. defined automated tasks) that currently run.
This job backs up Jenkins itself by packing existing configurations and a list of plugins into an archive (gzipped tarball), then uploading the archive to the configured Amazon S3 bucket.
These archives are meant to be used in case the Jenkins server needs to be restored, which should be handled via the Ansible playbook written for this task.
This job periodically keeps the production server clock in sync to prevent some minor - but annoying - complications.
This job listens for changes to the master branch of the Github repository of the API. When a commit is detected:
- The latest code is retrieved from Github.
- The appropriate configurations (i.e.
.env) are downloaded. - Listed dependencies are installed (
yarn install) - The resulting application is archived and uploaded to Amazon S3.
After the job is finished, it will automatically trigger sdg-nri-api-deploy-production, which is detailed below.
In case you've made a change to the API that is not tracked by the repository, such as updating the configuration, you may need to kick off the build process manually.
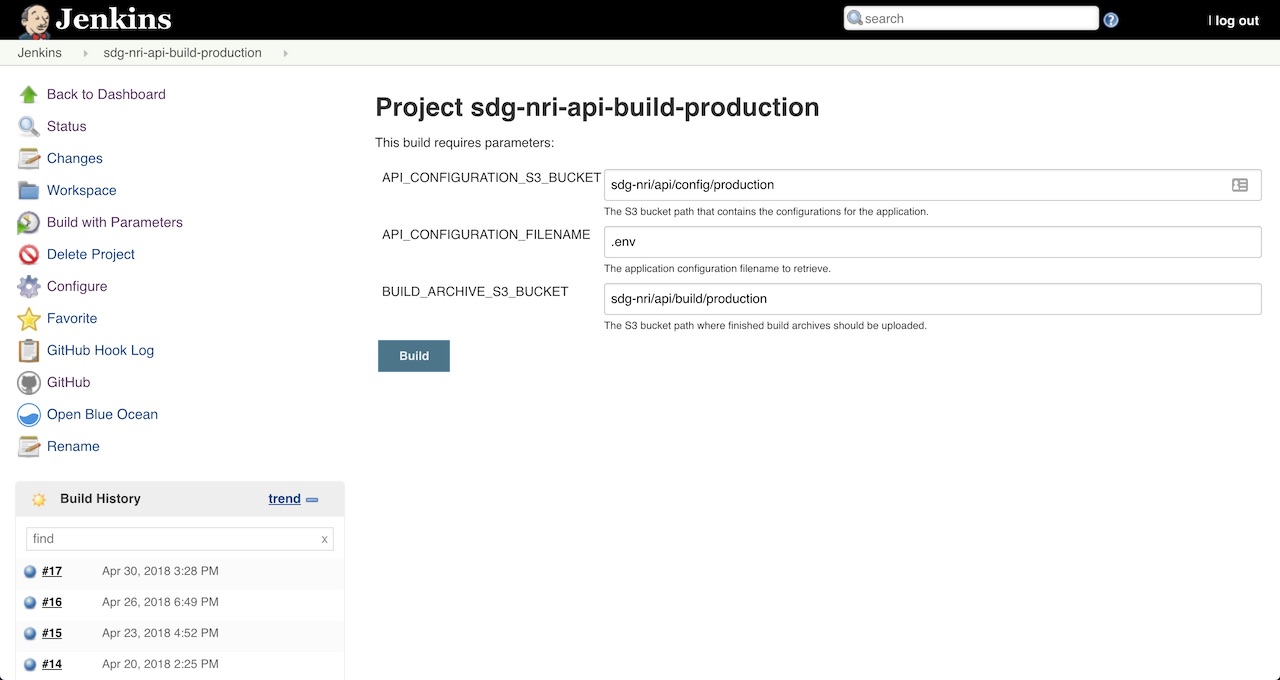
Select sdg-nri-api-build-production from the main Jenkins dashboard. From the job management screen, select Build with Parameters from the left-hand side. This should bring up a list of parameters you may edit, but all of the parameters for this build job should have working defaults. Select the Build button to start a new build.
This job retrieves the configured API build from Amazon S3 and deploys it to the configured production server.
- Connects to production server via SSH.
- Downloads the configured build archive.
- Unpacks the build to the proper deployment location.
- Runs schema migrations to keep schema up-to-date.
- Refreshes the necessary servers.
- Cleans up the downloaded build archive.
If you need to manually start a production deployment, the process is similar to manually starting a build as detailed above. The primary caveat when selecting Build with Parameters for deployments is that you will have to provide the Amazon S3 path and filename of the build archive to deploy (normally, when this job is run from the sdg-nri-api-build-production job, the necessary parameters are automatically passed in).

This job periodically backs up the project database to Amazon S3 by uploading an archived SQL dump. These backups are meant to provide backups in situations where the Amazon RDS snapshots may not be an option.