🎉 We are thrilled to announce the v1.0.0 CleanRL Release. Along with our CleanRL paper's recent publication in Journal of Machine Learning Research, our v1.0.0 release includes reworked documentation, new algorithm variants, support for google's new ML framework JAX, hyperparameter tuning utilities, and more. CleanRL has come a long way making high-quality deep reinforcement learning implementations easy to understand and reproducible. This release is a major milestone for the project and we are excited to share it with you. Over 90 PRs were merged to make this release possible. We would like to thank all the contributors who made this release possible.
Reworked documentation
One of the biggest change of the v1 release is the added documentation at docs.cleanrl.dev. Having great documentation is important for building a reliable and reproducible project. We have reworked the documentation to make it easier to understand and use. For each implemented algorithm, we have documented as much as we can to promote transparency:
- Short description of the algorithm and references
- A list of implemented variant
- The usage information
- The explanation of the logged metrics
- The documentation of implementation details
- Experimental results
Here is a list of the algorithm variants and their documentation:
We also improved the contribution guide to make it easier for new contributors to get started. We are still working on improving the documentation. If you have any suggestions, please let us know in the GitHub Issues.
New algorithm variants, support for JAX
We now support JAX-based learning algorithm variants, which are usually faster than the torch equivalent! Here are the docs of the new JAX-based DQN, TD3, and DDPG implementations:
dqn_atari_jax.py@kinalmehta in vwxyzjn/cleanrl#222- about 25% faster than
dqn_atari.py.
- about 25% faster than
td3_continuous_action_jax.pyby @joaogui1 in vwxyzjn/cleanrl#225- about 2.5-4x faster than
td3_continuous_action.py.
- about 2.5-4x faster than
ddpg_continuous_action_jax.pyby @vwxyzjn in vwxyzjn/cleanrl#187- about 2.5-4x faster than
ddpg_continuous_action.py.
- about 2.5-4x faster than
ppo_atari_envpool_xla_jax.pyby @vwxyzjn in vwxyzjn/cleanrl#227- about 3x faster than openai/baselines' PPO.
For example, below are the benchmark of DDPG + JAX (see docs here for further detail):

Other new algorithm variants include multi-GPU PPO, PPO prototype that works with Isaac Gym, multi-agent Atari PPO, and refactored PPG and PPO-RND implementations:
ppo_atari_multigpu.puby @vwxyzjn in vwxyzjn/cleanrl#178- about 34% faster than
ppo_atari.pywhich usesSyncVectorEnv.
- about 34% faster than
ppo_continuous_action_isaacgym.pyby @vwxyzjn in vwxyzjn/cleanrl#233- achieves 4000+ score and 30M steps on IsaacGymEnvs'
Antin 4 mins.
- achieves 4000+ score and 30M steps on IsaacGymEnvs'
ppo_pettingzoo_ma_atari.pyby @vwxyzjn in vwxyzjn/cleanrl#188- achieves ~4000 episodic length (not episodic return) in Pong, creating competitive self play agents.
ppg_procgen.pyby @Dipamc77 in vwxyzjn/cleanrl#186- matches openai/baselines' PPO performance in StarPilot (easy), BossFight (easy), and BigFish (easy).
ppo_rnd_envpoolpy.pyby @yooceii in vwxyzjn/cleanrl#151- achieves ~7100 in
MontezumaRevengeNoFrameSkip-v4.
- achieves ~7100 in
Tooling improvements
We love tools! The v1.0.0 release comes with a series of DevOps improvements, including pre-commit utilities, CI integration with GitHub to run end-to-end test cases. We also make available a new hyperparameter tuning tool and a new tool for running benchmark experiments.
DevOps
We added a pre-commit utility to help contributors to format their code, check for spelling, and removing unused variables and imports before submitting a pull request (see Contribution guide for more detail).
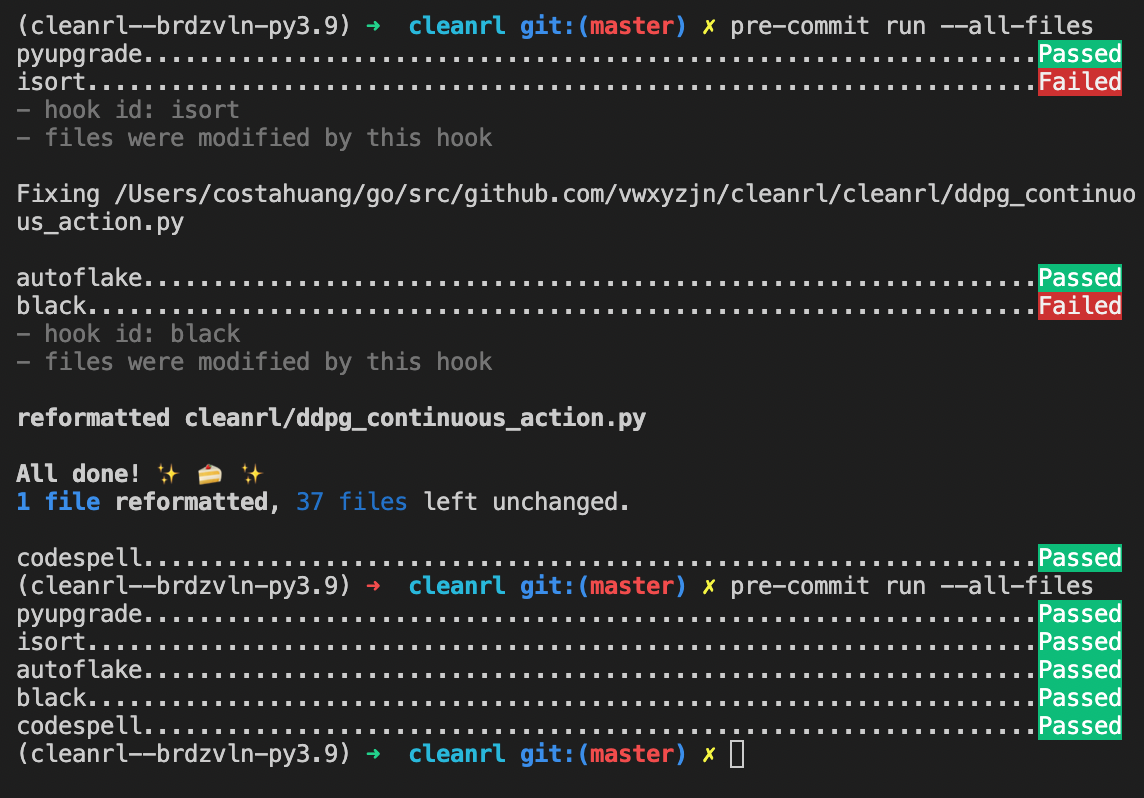
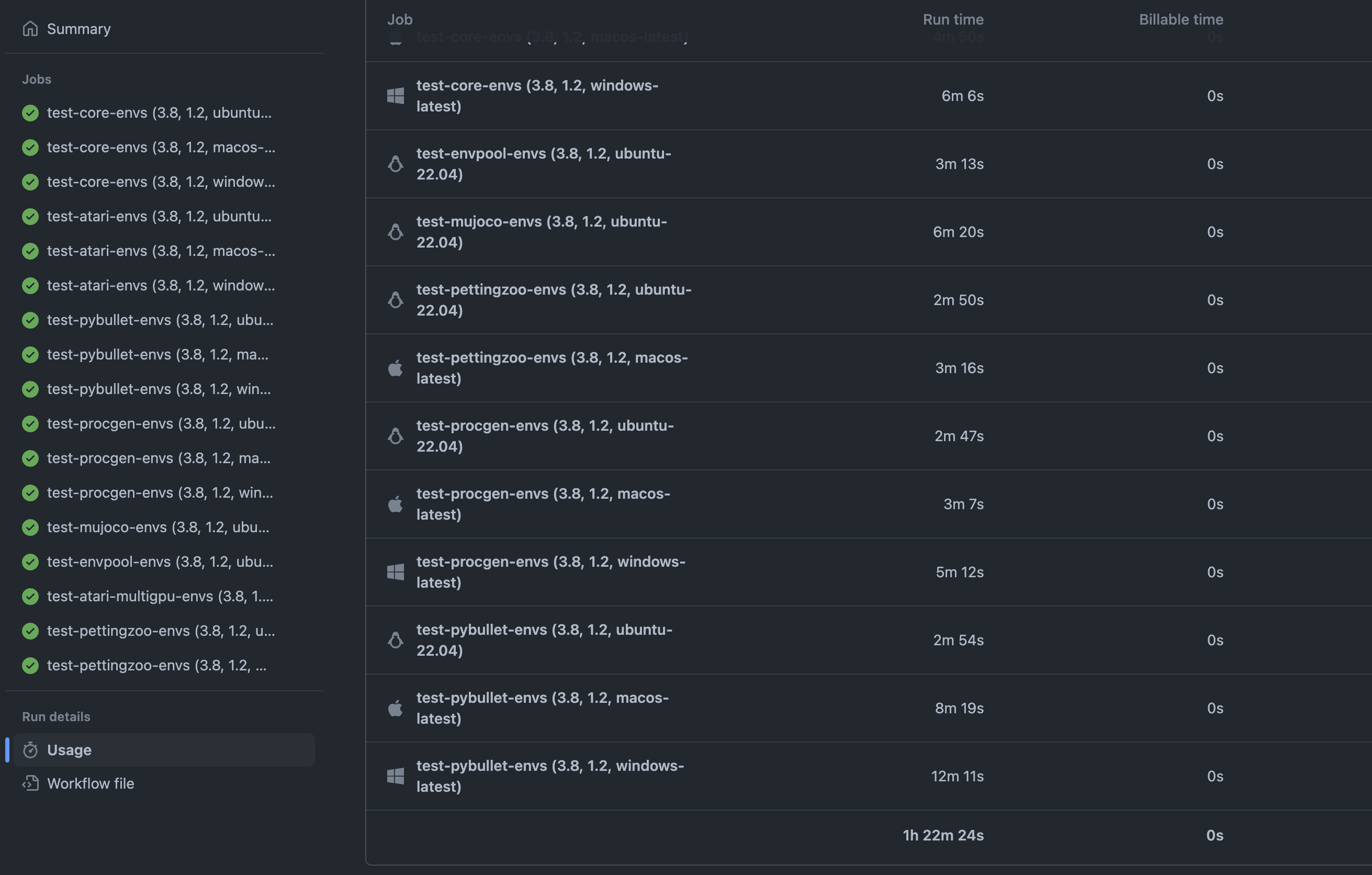
To ensure our single-file implementations can run without error, we also added CI/CD pipeline which now runs end-to-end test cases for all the algorithm variants. The pipeline also tests builds across different operating systems, such as Linux, macOS, and Windows (see here as an example). GitHub actions are free for open source projects, and we are very happy to have this tool to help us maintain the project.
Hyperparameter tuning utilities
We now have preliminary support for hyperparameter tuning via optuna (see docs), which is designed to help researchers to find a single set of hyperparameters that work well with a kind of games. The current API looks like below:
import optuna
from cleanrl_utils.tuner import Tuner
tuner = Tuner(
script="cleanrl/ppo.py",
metric="charts/episodic_return",
metric_last_n_average_window=50,
direction="maximize",
aggregation_type="average",
target_scores={
"CartPole-v1": [0, 500],
"Acrobot-v1": [-500, 0],
},
params_fn=lambda trial: {
"learning-rate": trial.suggest_loguniform("learning-rate", 0.0003, 0.003),
"num-minibatches": trial.suggest_categorical("num-minibatches", [1, 2, 4]),
"update-epochs": trial.suggest_categorical("update-epochs", [1, 2, 4, 8]),
"num-steps": trial.suggest_categorical("num-steps", [5, 16, 32, 64, 128]),
"vf-coef": trial.suggest_uniform("vf-coef", 0, 5),
"max-grad-norm": trial.suggest_uniform("max-grad-norm", 0, 5),
"total-timesteps": 100000,
"num-envs": 16,
},
pruner=optuna.pruners.MedianPruner(n_startup_trials=5),
sampler=optuna.samplers.TPESampler(),
)
tuner.tune(
num_trials=100,
num_seeds=3,
)Benchmarking utilities
We also added a new tool for running benchmark experiments. The tool is designed to help researchers to quickly run benchmark experiments across different algorithms environments with some random seeds. The tool lives in the cleanrl_utils.benchmark module, and the users can run commands such as:
OMP_NUM_THREADS=1 xvfb-run -a python -m cleanrl_utils.benchmark \
--env-ids CartPole-v1 Acrobot-v1 MountainCar-v0 \
--command "poetry run python cleanrl/ppo.py --cuda False --track --capture-video" \
--num-seeds 3 \
--workers 5which will run the ppo.py script with --cuda False --track --capture-video arguments across 3 random seeds for 3 environments. It uses multiprocessing to create a pool of 5 workers run the experiments in parallel.
What’s next?
It is an exciting time and new improvements are coming to CleanRL. We plan to add more JAX-based implementations, huggingface integration, some RLops prototypes, and support Gymnasium. CleanRL is a community-based project and we always welcome new contributors. If there is an algorithm or new feature you would like to contribute, feel free to chat with us on our discord channel or raise a GitHub issue.
More JAX implementations
More JAX-based implementation are coming. Antonin Raffin, the core maintainer of Stable-baselines3, SBX, and rl-baselines3-zoo, is contributing an optimized Soft Actor Critic implementation in JAX (vwxyzjn/cleanrl#300) and TD3+TQC, and DroQ (vwxyzjn/cleanrl#272. These are incredibly exciting new algorithms. For example, DroQ is extremely sample effcient and can obtain ~5000 return in HalfCheetah-v3 in just 100k steps (tracked sbx experiment).
Huggingface integration
Huggingface Hub 🤗 is a great platform for sharing and collaborating models. We are working on a new integration with Huggingface Hub to make it easier for researchers to share their RL models and benchmark them against other models (vwxyzjn/cleanrl#292). Stay tuned! In the future, we will have a simple snippet for loading models like below:
import random
from typing import Callable
import gym
import numpy as np
import torch
def evaluate(
model_path: str,
make_env: Callable,
env_id: str,
eval_episodes: int,
run_name: str,
Model: torch.nn.Module,
device: torch.device,
epsilon: float = 0.05,
capture_video: bool = True,
):
envs = gym.vector.SyncVectorEnv([make_env(env_id, 0, 0, capture_video, run_name)])
model = Model(envs).to(device)
model.load_state_dict(torch.load(model_path))
model.eval()
obs = envs.reset()
episodic_returns = []
while len(episodic_returns) < eval_episodes:
if random.random() < epsilon:
actions = np.array([envs.single_action_space.sample() for _ in range(envs.num_envs)])
else:
q_values = model(torch.Tensor(obs).to(device))
actions = torch.argmax(q_values, dim=1).cpu().numpy()
next_obs, _, _, infos = envs.step(actions)
for info in infos:
if "episode" in info.keys():
print(f"eval_episode={len(episodic_returns)}, episodic_return={info['episode']['r']}")
episodic_returns += [info["episode"]["r"]]
obs = next_obs
return episodic_returns
if __name__ == "__main__":
from huggingface_hub import hf_hub_download
from cleanrl.dqn import QNetwork, make_env
model_path = hf_hub_download(repo_id="cleanrl/CartPole-v1-dqn-seed1", filename="q_network.pth")
RLops
How do we know the effect of a new feature / bug fix? DRL is brittle and has a series of reproducibility issues — even bug fixes sometimes could introduce performance regression (e.g., see how a bug fix of contact force in MuJoCo results in worse performance for PPO). Therefore, it is essential to understand how the proposed changes impact the performance of the algorithms.
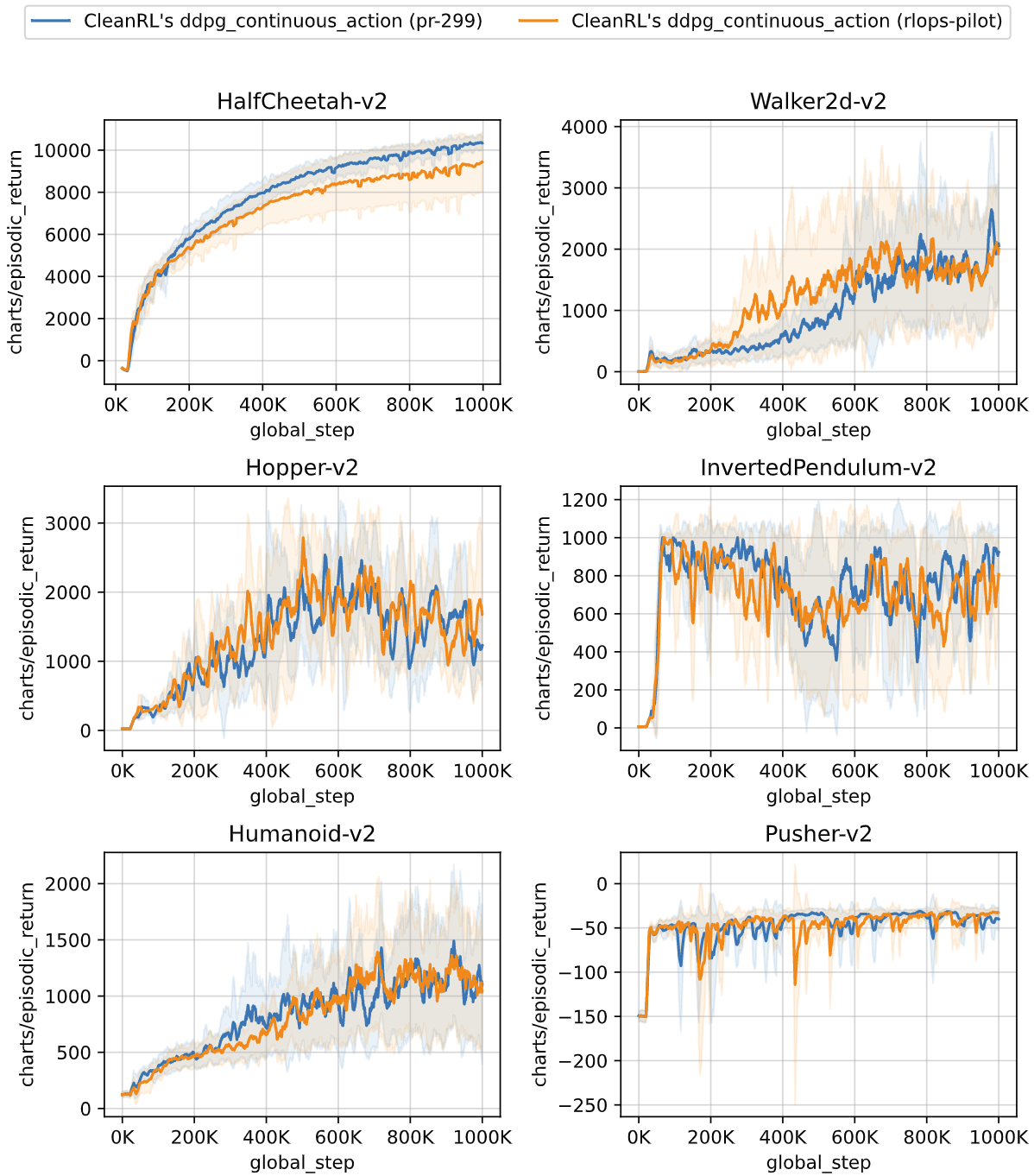
We are working a prototype tool that allows us to compare the performance of the library at different versions of the tracked experiment (vwxyzjn/cleanrl#307). With this tool, we can confidently merge new features / bug fixes without worrying about introducing catastrophic regression. The users can run commands such as:
python -m cleanrl_utils.rlops --exp-name ddpg_continuous_action \
--wandb-project-name cleanrl \
--wandb-entity openrlbenchmark \
--tags 'pr-299' 'rlops-pilot' \
--env-ids HalfCheetah-v2 Walker2d-v2 Hopper-v2 InvertedPendulum-v2 Humanoid-v2 Pusher-v2 \
--output-filename compare.png \
--scan-history \
--metric-last-n-average-window 100 \
--reportwhich generates the following image
Support for Gymnasium
Farama-Foundation/Gymnasium is the next generation of openai/gym that will continue to be maintained and introduce new features. Please see their announcement for further detail. We are migrating to gymnasium and the progress can be tracked in vwxyzjn/cleanrl#277.
Today we're launching the Farama Foundation, a new nonprofit dedicated to open source reinforcement learning, and we're beginning by maintaining and standardizing all the major open source reinforcement learning environments. Read more here: https://t.co/kQqFMQdVqn
— Farama Foundation (@FaramaFound) October 25, 2022
Also, the Farama foundation is working a project called Shimmy which offers conversion wrapper for deepmind/dm_env environments, such as dm_control and deepmind/lab. This is an exciting project that will allow us to support deepmind/dm_env in the future.
Contributions
CleanRL has benefited from the contributions of many awesome folks. I would like to cordially thank the core dev members @dosssman @yooceii @Dipamc @kinalmehta @bragajj for their efforts in helping maintain the CleanRL repository. I would also like to give a shout-out to our new contributors @cool-RR, @Howuhh, @jseppanen, @joaogui1, @ALPH2H, @ElliotMunro200, @WillDudley, and @sdpkjc.
We always welcome new contributors to the project. If you are interested in contributing to CleanRL (e.g., new features, bug fixes, new algorithms), please check out our reworked contributing guide.
New CleanRL Supported Publications
- Md Masudur Rahman and Yexiang Xue. "Bootstrap Advantage Estimation for Policy Optimization in Reinforcement Learning." In Proceedings of the IEEE International Conference on Machine Learning and Applications (ICMLA), 2022. https://arxiv.org/pdf/2210.07312.pdf
- Weng, Jiayi, Min Lin, Shengyi Huang, Bo Liu, Denys Makoviichuk, Viktor Makoviychuk, Zichen Liu et al. "Envpool: A highly parallel reinforcement learning environment execution engine." In Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track. https://openreview.net/forum?id=BubxnHpuMbG
- Huang, Shengyi, Rousslan Fernand Julien Dossa, Antonin Raffin, Anssi Kanervisto, and Weixun Wang. "The 37 Implementation Details of Proximal Policy Optimization." International Conference on Learning Representations 2022 Blog Post Track, https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/
- Huang, Shengyi, and Santiago Ontañón. "A closer look at invalid action masking in policy gradient algorithms." The International FLAIRS Conference Proceedings, 35. https://journals.flvc.org/FLAIRS/article/view/130584
- Schmidt, Dominik, and Thomas Schmied. "Fast and Data-Efficient Training of Rainbow: an Experimental Study on Atari." Deep Reinforcement Learning Workshop at the 35th Conference on Neural Information Processing Systems, https://arxiv.org/abs/2111.10247
New Features PR
- prototype jax with ddpg by @vwxyzjn in #187
- Isaac Gym Envs PPO updates by @vwxyzjn in #233
- JAX TD3 prototype by @joaogui1 in #225
- prototype jax with dqn by @kinalmehta in #222
- Poetry 1.2 by @vwxyzjn in #271
- Add rnd_ppo.py documentation and refactor by @yooceii in #151
- Hyperparameter optimization by @vwxyzjn in #228
- Update the hyperparameter optimization example script by @vwxyzjn in #268
- Export
requirements.txtautomatically by @vwxyzjn in #143 - Auto-upgrade syntax via
pyupgradeby @vwxyzjn in #158 - Introduce benchmark utilities by @vwxyzjn in #165
- Match PPG implementation by @Dipamc77 in #186
- See the documentation here: https://docs.cleanrl.dev/rl-algorithms/ppg/
- Proper multi-gpu support with PPO by @vwxyzjn in #178
- See the documentation here: https://docs.cleanrl.dev/rl-algorithms/ppo/#ppo_atari_multigpupy
- Support Pettingzoo Multi-agent Atari envs with PPO by @vwxyzjn in #188
- See the documentation here: https://docs.cleanrl.dev/rl-algorithms/ppo/#ppo_pettingzoo_ma_ataripy# Bug Fixes PR
Bug fix and refacotring PR
- Let
ppo_continuous_action.pyonly run 1M steps by @vwxyzjn in #161 - Change
ppo.py's default timesteps by @vwxyzjn in #164 - Enable video recording for
ppo_procgen.pyby @vwxyzjn in #166 - Refactor replay based scripts by @vwxyzjn in #173
- Td3 ddpg action bound fix by @dosssman in #211
- added gamma to reward normalization wrappers by @Howuhh in #209
- Seed envpool environment explicitly by @jseppanen in #238
- Fix PPO + Isaac Gym Benchmark Script by @vwxyzjn in #243
- Fix for noise sampling for the TD3 exploration by @dosssman in #260
Documentation PR
- Add a note on PPG's performance by @vwxyzjn in #199
- Clarify CleanRL is a non-modular library by @vwxyzjn in #200
- Fix documentation link by @vwxyzjn in #213
- JAX + DDPG docs fix by @vwxyzjn in #229
- Fix links in docs for
ppo_continuous_action_isaacgym.pyby @vwxyzjn in #242 - Fix docs (badge, TD3 + JAX, and DQN + JAX) by @vwxyzjn in #246
- Fix typos by @ALPH2H in #282
- Fix docs links in README.md by @vwxyzjn in #254
- chore: remove unused parameters in jax implementations by @kinalmehta in #264
- Add
ddpg_continuous_action.pydocs by @vwxyzjn in #137 - Fix DDPG docs' description by @vwxyzjn in #139
- Fix typo in DDPG docs by @vwxyzjn in #140
- Fix incorrect links in the DDPG docs by @vwxyzjn in #142
- DDPG documnetation tweaks; added Q loss equations and light explanation by @dosssman in #145
- Add
dqn_atari.pydocumentation by @vwxyzjn in #124 - Add documentation for
td3_continuous_action.pyby @vwxyzjn in #141 - SAC Documentation - Benchmarks - Minor code tweaks by @dosssman in #146
- Add docs for
c51.pyandc51_atari.pyby @vwxyzjn in #159 - Add docs for
dqn.pyby @vwxyzjn in #157 - Address stale documentation by @vwxyzjn in #169
- Documentation improvement - fix links and mkdocs by @vwxyzjn in #181
- Improve documentation and contribution guide by @vwxyzjn in #189
- Fix documentation links in README.md by @vwxyzjn in #192
- Fix the implemented varaints section in PPO by @vwxyzjn in #193
Misc PR
- Show correct exception cause by @cool-RR in #205
- Remove pettingzoo's pistonball example by @vwxyzjn in #214
- Leverage CI to speed up poetry lock by @vwxyzjn in #235
- Ubuntu runner for poetry lock by @vwxyzjn in #236
- Remove the github pages CI in favor of vercel by @vwxyzjn in #241
- Clarify LICENSE info by @vwxyzjn in #253
- Update published paper citation by @vwxyzjn in #284
- Refactor dqn word choice by @vwxyzjn in #257
- Add Pull Request template by @vwxyzjn in #122
- Amend license to give proper attribution by @vwxyzjn in #152
- Introduce better contribution guide by @vwxyzjn in #154
- Fix the default wandb project name in
ppo_atari_envpool.pyby @vwxyzjn in #160 - Removes unmaintained scripts by @vwxyzjn in #170
- Add PPO documentation by @vwxyzjn in #163
- Add docs header by @vwxyzjn in #174
- Update README.md by @ElliotMunro200 in #177
- Update issue_template.md by @vwxyzjn in #180
- Temporarily Remove PPO-RND by @vwxyzjn in #190 .
Contributors
- @ElliotMunro200 made their first contribution in #177
- @dipamc made their first contribution in #186
- @cool-RR made their first contribution in #205
- @Howuhh made their first contribution in #209
- @jseppanen made their first contribution in #238
- @joaogui1 made their first contribution in #225
- @kinalmehta made their first contribution in #222
- @ALPH2H made their first contribution in #282
- @WillDudley made their first contribution in #302
- @sdpkjc made their first contribution in #299
- @masud99r made their first contribution in #316
Full Changelog: v0.6.0...v1.0.0