情感分析的方法大概分为四类:情感词典法、机器学习方法、深度学习方法、基于预训练模型微调
接下来通过方法简介、整体思路、模型的评价指标、建模过程、结果展示与分析对以上几种方法进行介绍:
-
情感词典法: 利用人为标注或者评级过的情感字典,通过将文本进行分词,利用分词后的数据匹配字典中的值,然后直接加权或者利用词性进行加权即得到整句话的情感得分,最后根据专家经验或者数据分布,选取正、负的临界值作为模型的阈值。
-
机器学习方法: 机器学习方法的思想是,将情感分析任务当作一个分类任务,通过将短文本转化为固定维度的向量,利用当前基于不同思想的分类器对其进行训练,通过对比测试集结果来观察不同的机器学习分类器之间的差异。
-
深度学习方法: 深度学习是近年来较为热门的领域,其基于神经网络,利用网络的自适应学习率不断调节损失函数的值,大大减少了人工调参的复杂度,并且由于目前计算机算力水平的大幅度提升,利用GPU加速运算使得在短时间内即可得到较好的效果。比较主流的深度学习做情感分析的方法是利用长短期记忆模型来捕获句子之前的前后联系,得到相比于机器学习更好的效果,而本文从多层感知机、BP神经网络、卷积神经网络、长短期记忆神经网络以及自注意力机制模型来进行对比实验从而探索各种深度学习模型在情感分析领域的优缺点。
-
基于预训练模型微调: finetune是当前各类NLP任务的首选,由于2018年BERT模型刷新了各项NLP任务的最优,使得预训练模型成为目前的研究热点,最近基于自回归的XLNet又刷新了NLP任务的sota,可以看到未来的研究热点还是会集中在预训练模型。本文利用预训练好的BERT模型在情感分析领域做迁移训练,观察其效果,并对比最新的XLNet,研究两种预训练模型的优缺点。
情感词典法的优点:优点是建模方法简单,运算速度快,灵活多变,针对不同场景有可调的参数结构和方式。
情感词典法的缺点:缺点是构建词典需要耗费大量人力物力,深入挖掘行业信息,迁移能力弱,即针对不同领域需要构建不同的行业情感词典,另外其模型的效果以及各类别的准确率、召回率均比较低,对于含有不同情感类别的句子分类效果很差。
机器学习的优点:优点是相比于情感词典法,机器学习利用词向量进行建模,挖掘其特征,利用特征建模,效果较好,模型较小,并且场景容易做不同行业之间的迁移。
机器学习的缺点:模型所需调节的参数较多,并且很多参数需要人工不断尝试,(类似kaggle,得到top1的调参基本都是玄学问题)。
深度学习方法的优点:相比于机器学习,其模型效果更好,泛化能力更好,场景迁移能力较强,泛化能力好。
深度学习方法的缺点:对于数据数量以及质量的要求较高,如果数据量太少,容易引发过拟合,数据质量不好模型很难收敛,并且其相比于其他方法,比较耗时。
BERT的优缺点:
XLNet的优缺点:
本文从数据的预处理到后续建模都将进行详细的介绍,大体分为数据的预处理(文本正则化、停用词过滤等)、样本集划分、数据的向量化表示、模型训练与保存、模型的测试指标,实验思路以及具体的代码介绍将在建模过程中详细介绍
Details:
对于机器学习和深度学习中,采用8:2的比例随机抽取清洗后的数据当作训练集与验证集,并且为了同时对比它们以至于后续的预训练微调的模型效果,通过将训练集和验证集保存为json格式文件,后续直接调用json文件当作训练集和验证集即可。而对于将文本数据转化为向量表示,在机器学习和深度学习中本文对比了利用中文维基百科基于Word2Vec训练的词向量以及去年腾讯开源的900W词向量的模型效果,在finetune中使用BERT和XLNet预训练模型进行微调对比。
本文选取准确率(Accuracy)、平均召回率(Avg_Recall)、平均精确率(Avg_Precision)、F1值(F1_Score)作为模型的评价指标
以上各个指标通常是分类任务中评价指标的首选,下面利用混淆矩阵对以上各类指标进行简单介绍,如下所示:
| 标注类别\预测类别 | 正向(P) | 负向(N) |
|---|---|---|
| 正向(P) | TP | FN |
| 负向(N) | FP | TN |
| 标注类别\预测类别 | 正向(P) | 中向(Z) | 负向(N) |
|---|---|---|---|
| 正向(P) | TP | FZ | FN |
| 中向(Z) | FP | TZ | FN |
| 负向(N) | FP | FZ | TN |
其中:
Accuracy = (TP+TZ+TN)/(TP+TZ+TN+2FP+2FZ+2FN)
Avg_Recall = (TP/(TP+FZ+FN) + TZ/(FP+TZ+FN) + TN/(FP+FZ+TN))/3
Avg_Pecision = (TP/(TP+2FP) + TZ/(TZ+2FZ) + TN/(TN+2FN))/3
F1_Score = 2·Avg_Pecision·Avg_Recall/(Avg_Pecision+Avg_Recall)
- 情感词典
实验步骤分为两方面:
1.直接利用boson情感词典(也可以替换data中的数据,找到网上其他的字典或者自行构建的情感词典,格式保持跟data.txt中的一致即可),查看boson情感词典的正负中的召回率。
通过对比结果看出单纯的boson情感词典效果很差,而采用了情感副词以及添加否定词的boson情感词典方法的效果大大优于单纯的情感词典方法,但其结果仍然不乐观,基本recall也就在30~50%之间(略高于随机选择),但是其对于强正向和强负向区分能力较高,但是对于包含多个情感词的句子没什么分辨能力。
- 机器学习
在机器学习方法中本文使用以下几种类型的分类器
- 逻辑回归
- 随机梯度下降
- 朴素贝叶斯
- 支持向量机
- 随机森林
- XGBoost
代码实现过程:
首先运行ml_classify.py文件中
if __name__ == "__main__":
# get_tencent_word_embedding()
# import random
# random.seed(1)
# get_sentiment_model()
# _test_save_model_validate()
# test_x = '新买的手机的信号还可以,没有预期的期望高,不过对于我来说也还可以了'
# real_predict(test_x)
get_variable_model_test()使用其中的get_variable_model_test()函数,先debug到下方json.jump处,此处是用来将我们存在excel中的文本数据进行清理得到正则化后的数据,并将其进行词向量表示,本文中选取了两种形式,即利用中文维基百科训练的Word2Vec词向量(这里仅用了腾讯开源的词向量,但当初我也试验了中文维基百科的词向量,腾讯的建模效果要好很多,网上很多开源的训练好的词向量,就是把词向量替换即可,较为容易),以及腾讯开源的900W的词向量(之所以没有用BERT进行微调是因为这个是去年9月份写的,那会儿BERT还没出来,后续深度学习中我们会应用BERT句向量)
def get_variable_model_test():
get regular train and test data
pos_list, neutral_list, neg_list = get_data()
train_X, y = build_vecs_tencent(pos_list, neutral_list, neg_list)
train_x, test_x, train_y, test_y = train_test_split(train_X, y, test_size = 0.3)
train_x = train_x.tolist()
test_x = test_x.tolist()
train_y = train_y.tolist()
test_y = test_y.tolist()
json.dump([train_x, test_x, train_y, test_y],open('train_x.json', 'w'))
而主要的建模过程如下所示,其中利用的get_Word2Vec(8824330)函数是我针对腾讯900W词向量自己写的一个简单的迭代读取的脚本,在Tencent_word_Embedding中大家可以自行尝试观察腾讯的200维词向量的余弦相似度。
def get_tencent_word_embedding():
# get tencent word embedding dict for convert phrase
start = time.time()
tencent_word_matrix = {}
data = load_data()
for uuid, txt in tqdm(data.items()):
cut_txt = jieba.cut(txt[0], cut_all = False)
for seg in cut_txt:
if seg != '' and seg not in tencent_word_matrix:
tencent_word_matrix[seg] = 0
# break
for i in get_Word2Vec(8824330):
if i[0] in tencent_word_matrix:
try:
if len(i[1::]) == 200 and i[1::] != 0:
tencent_word_matrix[i[0]] = i[1::]
except Exception as e:
print ('Error type', e,i)
with open('tencent_word_embedding_dict.json', 'w') as json_file:
json.dump(tencent_word_matrix, json_file)
json_file.close()
end = time.time()
# time almost equal 600s
print ('JSON File has been done: ', end - start)使用上述迭代读取的方式对腾讯词向量进行建模,并将其转换为json脚本,上面的json是为了保证我们的训练集是采用同一批数据
def get_sentiment_model():
start = time.time()
# stop_word = get_stop_word()
# use tencent word embedding
pos_list, neutral_list, neg_list = get_data()
train_X, y = build_vecs_tencent(pos_list, neutral_list, neg_list)
# model = load_Word2Vec_Model()
# train_X, y = build_vecs(pos_list, neutral_list, neg_list, stop_word, model)
# show the data distribute...it costs too long...
# plt_with_tsne(train_X, pos_list, neg_list, neutral_list)
train_ratio = 0.2
# standardization , tencent word embedding has been done.
# train_X = scale(train_X)
# plot the PCA spectrum
# reduce or not is no necessary
# reduce_x = plot_pca(train_X)
# reduce_train_x, reduce_test_x, reduce_train_y, reduce_test_y = prepare_train_data(reduce_x, y, train_ratio)
train_x, test_x, train_y, test_y = prepare_train_data(train_X, y, train_ratio)
# use RandomForest to classify accuracy equal
RandomForest_Model(train_x, test_x, train_y, test_y)
# use SGD of logistic to classify accuracy equal 0.53
sgd_model(train_x, test_x, train_y, test_y)
# sgd_model(reduce_train_x, reduce_test_x, reduce_train_y, reduce_test_y)
# use RBF svm to classify accuracy equal 0.50
svm_model(train_x, test_x, train_y, test_y)
# svm_model(reduce_train_x, reduce_test_x, reduce_train_y, reduce_test_y)
# use naive bayes to classify accuracy equal 0.51
naive_model(train_x, test_x, train_y, test_y)
# use logistic to classify accuracy equal 0.57
logistic_model(train_x, test_x, train_y, test_y)
xgb_model(train_x, test_x, train_y, test_y)
Snow_naive_bayes()
end = time.time()
print ('Total Time :', end - start)可以通过修改注释来对单个模型进行分别训练,如stop_word = get_stop_word()是选择建模过程中是否去除停用词
这里logistic、randomforest、sgd、svm、naive_bayes、Xgb一共六种主流的分类器进行对比测试,另外Snow_naive_bayes(data_dir)中使用了目前比较流行的中文NLP包,SnowNLP库中的情感分析模块进行对比测试,其建模核心也是基于朴素贝叶斯的思想。
每个分类模型中的plot_confusion_matrix(cnf_matrix, classes=class_names, title='Logistic Confusion matrix')是用来生成其混淆矩阵,即得到上方我们统计各类评价指标所用的confusion matrix
另外def _test_save_model_validate():函数是用来对excel中的数据进行测试,需要自行修改def get_new_test_list():函数中的路径、数据cell的位置,也可以直接用csv或者json自己写训练数据的读取形式,之后loading_save_model(model, test_x, test_y, classifyname):函数中可以自行选择想要对比验证的模型类型,svm = joblib.load('RBF_SVM_modify_train_data_model.pkl')中加载其保存路径即可。
- 深度学习
由于目前神经网络、深度学习大热,故此文本主要介绍这部分的内容。
在深度学习中,做分类任务主要有几大类,首先是最原始的多层感知机,即常说的BP神经网络,其构造简单,最后通过全连接层来实现分类任务。
RNN系列的LSTM,利用门结构来对上一时刻的信息进行取舍来构建文本之间的联系,通过判断句子前后的联系来进行建模,对于时间序列数据有着得天独厚的优势,而文本输入本就是符合时间递进关系,可以理解为一个马尔可夫过程,因此,对于文本情感分析中,在神经网络中最常用的是LSTM、GRU、Bi-LSTM等LSTM的变种系列
由于CV方面进行的如火如荼,基于已经成熟的图像分类算法,也有人尝试利用CNN进行文本分类,其思路和之前的LSTM等不同的是,LSTM是将文本拼接为一行,每一时刻送入一个词或者字符级别的Embedding,而CNN是将文本序列转化为图像的像素形式,即,对于固定维度的词或字符级别的向量,其维度即为图像的长,文本序列的长度为高。总结起来,RNN系列是横向拼接文本序列,CNN系列是纵向拼接文本序列。相比于RNN,CNN的优势在于利用卷积窗口,可以并行计算。
最后介绍一下2017年最火的注意力机制(Attention),其主要的特点是在于改进输入的方式,首先利用位置矩阵对于输入的向量进行位置编码的加权,使得其输入天然具有位置信息,另外其利用编码、解码(Seq2Seq)的思想,在编码输入向量为一个矩阵时,记录了其位置信息,使得解码过程中更关注于相对应位置的解码问题,注意力机制本就是为了完善Seq2Seq而诞生的,相比于RNN系列关注上一时刻的输入,它更关注全局所有变量的输入,而编码解码方式的引进代替传统的RNN结构,使得他可以并行计算,运行速度比RNN系列快不少。可能有人有疑问,RNN系列通过遗忘门和细胞状态也可以记录之前的信息,为什么Attention机制要优于RNN系列?虽然RNN通过其门的结构对于之前的信息进行捕捉,但由于文本序列一般输入较长,RNN系列更加关注距离他比较近的时刻的输入,最初的输入信息在迭代中几乎已经消失了,这也是RNN的弊端,Attention就是将这种捕捉之前的信息引入了全局中,并在解码中一一对应的解码,故此,也是注意力机制名称的来源。
本场景仅以MLP为例,其他场景只要修改为相应的函数即可,都同理:
MLP的模型训练的流程图图下所示,通过添加recall、precsion、f1等评价指标,可以在每个epoch观测模型的变化,业务场景,并且在模型结束后,画出其训练和验证时刻的loss曲线和Auc曲线,如果想看训练实时的train_auc,train_loss和val_auc以及val_loss,可以在模型训练中添加一行tensorboard的日志保存命令:
tensorboard = TensorBoard(log_dir='../train_graph/logs', write_graph=True)并使用log来画图,在保存log的地方用cmd输入tensorboard --logdir='你的log地址'即可。
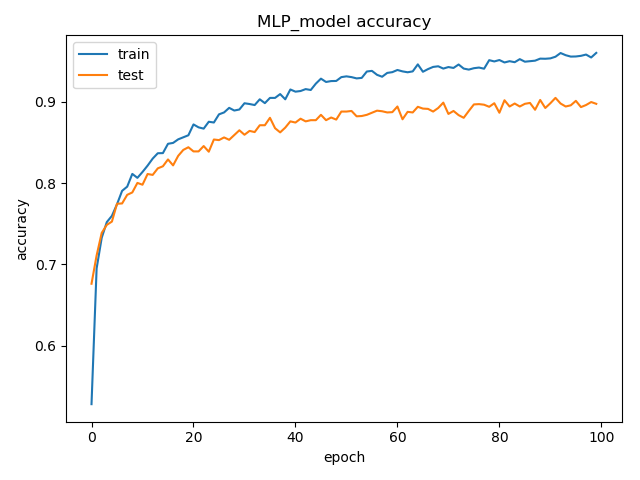
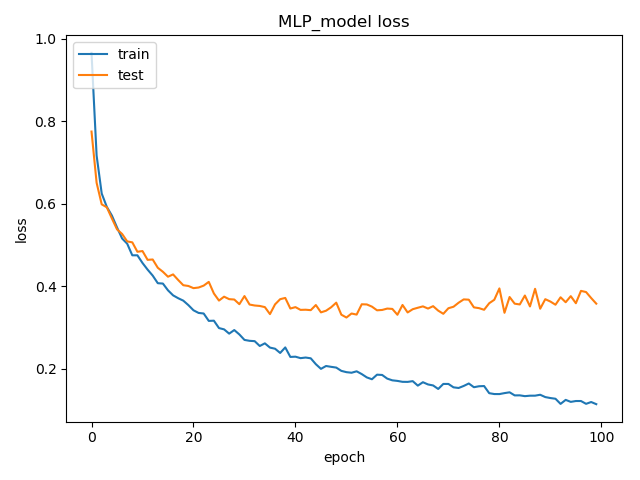
以上是整个模型的训练过程,模型调用过程也很方便,还是以MLP为例:
dir = './Sentiment_models/BP_model.h5'
model_transfer(dir)调用以上代码,自行调整模型路径,自行输入测试集,测试集输入需转化为200维向量表示。按照model_transfer其中说明即可加载模型
- 基于预训练微调
其中波森情感词典、机器学习各种分类模型、深度学习各类模型应用腾讯200维词向量的训练结果如图所示:
| Model_type | Accuracy | Avg(P) | Avg(R) | Avg(F1) |
|---|---|---|---|---|
| 波森情感词典 | 0.34 | 0.46 | 0.49 | 0.40 |
| 基于词性的波森情感词典 | 0.58 | 0.60 | 0.46 | 0.51 |
| Logistic回归 | 0.77 | 0.77 | 0.77 | 0.77 |
| 梯度下降法 | 0.75 | 0.78 | 0.77 | 0.76 |
| 朴素贝叶斯 | 0.62 | 0.64 | 0.62 | 0.62 |
| 支持向量机 | 0.76 | 0.76 | 0.76 | 0.76 |
| 随机森林 | 0.90 | 0.90 | 0.90 | 0.90 |
| XGBoost | 0.91 | 0.91 | 0.91 | 0.91 |
| 多层感知机 | 0.89 | 0.89 | 0.83 | 0.88 |
| 循环神经网络 | 0.91 | 0.90 | 0.89 | 0.90 |
| 卷积神经网络 | 0.88 | 0.87 | 0.83 | 0.85 |
| 自注意力机制 | 0.91 | 0.91 | 0.91 | 0.91 |
| BERT-Finetune | 0.93 | 0.93 | 0.93 | 0.93 |
虽然上述整体的效果比较好,但是因为我们数据量太少,对数据进行了复制,导致测试集跟训练集数据有重复,可能最终实际应用会大打折扣,但是根据我做工程的经验,用BERT的效果应该会维持在65~70左右,如果想要进一步提升模型的实际应用效果,需要进行针对性的tricks训练,比如,检查模型对于正、负、中哪一类的precison低,recall低,针对该类进行重新训练或者设置关键字以及词性位置等信息的规则方法,也可以提取BERT左右一层的句向量表示来用Attention进行训练。方法思路很多,具体问题,具体分析