





Code for the paper:
"Behind the Face: Unveiling the Effects of Background Subtraction on VAE and GAN Model Efficacy"
This study focuses on removing the background from datasets of faces
to gauge the effect on the training and performance of facial generative models.
We are also interested in the effect on the interpretability of the latent spaces of the models.
(Paper available here).
The repository contains:
- The
faceai-bgimpactpackage:- Data processing scripts to create the FFHQ-Blur and FFHQ-Grey datasets
- A unified Deep Learning framework for training and evaluating Generative AI models
- Models enabling latent space exploration with PCA
- A set of scripts to train, evaluate and generate images and videos from the models
- A set of pre-trained models(*)
- A web application to take control of the pre-trained models(*)
(*) = not included in the Pypi package.
The package was published to PyPi, and can be installed using
pip install faceai-bgimpact
To install locally, clone the repository and run poetry install from the root folder instead.
Note: If running on a GPU-enabled machine, pip may try to install the GPU-version of torch. Since CUDA is very heavy and takes a long time to install, this is not recommended, unless you intend on training models. You may install Torch (CPU) ahead of time, like we're doing in the Web-app's backend Dockerfile. But in general you shouldn't need to install the package if you're not planning on training, since you can use the Web-app to interact with models, and the Web-app is Dockerized.
We uploaded the created datasets to Kaggle. To download them, please set up your Kaggle API token, then run:
faceai-bgimpact download-all-ffhq
You can also choose to generate the Grey and Blur datasets yourself. To do so, first download the raw dataset using:
faceai-bgimpact download-all-ffhq --raw
Then, you can generate the masks using:
faceai-bgimpact create-masks
And finally, generate the grey and blur datasets using:
faceai-bgimpact create-blur-and-grey
The datasets are available on Kaggle at the following links:
The package allows you to train and evaluate the following models:
- Variational Auto-encoder
- DCGAN
- StyleGAN
using these example commands:
-
faceai-bgimpact train --model VAE --dataset ffhq_raw- (Train a VAE on the raw FFHQ dataset from scratch)
-
faceai-bgimpact train --model StyleGAN --dataset ffhq_grey --checkpoint-epoch 80- (Resume training a StyleGAN on the greyed-out FFHQ dataset from epoch 80)
We implemented the models from scratch, using PyTorch. Here is a list of the main inspirations we used, if any:
- StyleGAN:
- There is no official PyTorch implementation of StyleGAN 1. Most of the code was implemented by hand from reading the StyleGAN paper and the ProGAN paper, although, some building blocks were taken from other repositories, below.
- hukkelas/progan-pytorch: Inspiration for the progressive-growing structure, no actual code was used.
- aladdinpersson/Machine-Learning-Collection: We used this repository for the most granular building blocks, like the weight-scaled Conv2d layer, the pixelwise normalization layer, and the minibatch standard deviation layer.
- NVlabs/stylegan2: Official StyleGAN2 implementation. StyleGAN2 has a very different architecture from StyleGAN1, but we used the R1 loss function from this repository. StyleGAN normally uses WGAN-GP regularization, but we had convergence issues. Using R1 regularization instead of WGAN-GP solved the issue.
- VAE:
- The VAE was implemented from scratch, using the VAE paper as a reference.
- PCA:
- The latent space exploration using PCA was all implemented from scratch.
We also introduced a unified framework for the models. In practice we have an AbstractModel class, which is inherited by the VAE, DCGAN and StyleGAN classes. It enforces a common structure for the models, allowing the scripts to be nearly model-agnostic.
We also put in place rigorous code standards, using pre-commit hooks (black, flake8, prettier) to enforce code formatting, and linting, as well as automated tests using PyTest, and a code review process using pull requests. We used poetry for package management.
To run the pre-commit hooks, you should install the hooks using
pre-commit install, and thenpre-commit run(orpre-commit run --all-filesto run on all files).
To run the tests, you should install PyTest using
pip install pytest, and then runpytest -v(orpoetry run pytest -vif you are using ).
The package also includes a set of scripts to train, evaluate and generate images and videos from the models.
The train script is an entry point to train a model. It includes these command-line arguments:
--model: Required. Specifies the type of model to train with options "DCGAN", "StyleGAN", "VAE".--dataset: Required. Selects the dataset to use with options "ffhq_raw", "ffhq_blur", "ffhq_grey".--latent-dim: Optional. Defines the dimension of the latent space for generative models.--config-path: Optional. Path to a custom JSON configuration file for model training.--lr: Optional. Learning rate for DCGAN model training.--dlr: Optional. Discriminator learning rate for StyleGAN training.--glr: Optional. Generator learning rate for StyleGAN training.--mlr: Optional. W-Mapping learning rate for StyleGAN training.--loss: Optional. Specifies the loss function to use with defaults to "r1"; choices are "wgan", "wgan-gp", "r1".--batch-size: Optional. Defines the batch size during training.--num-epochs: Optional. Sets the number of epochs for training the model.--save-interval: Optional. Epoch interval to wait before saving models and generated images.--image-interval: Optional. Iteration interval to wait before saving generated images.--list: Optional. Lists all available checkpoints if set.--checkpoint-path: Optional. Path to a specific checkpoint file to resume training, takes precedence over--checkpoint-epoch.
The create-video script is an entry point to create a video from images saved throughout the training process. It includes these command-line arguments:
--model: Required. Specifies the type of model to train with options "DCGAN", "StyleGAN", "VAE".--dataset: Required. Selects the dataset to use with options "ffhq_raw", "ffhq_blur", "ffhq_grey".frame-rate: Optional. Defines the frame rate of the video.skip-frames: Optional. Defines the number of images to skip between each frame of the video.
Example usage:
faceai-bgimpact create-video --model StyleGAN --dataset ffhq_grey
=> Output video On the left, the generated image for the current resolution and alpha, on the right, a real image at the same resolution and alpha.
We developped a web application from scratch to control the latent space of StyleGAN using Vue.JS and Flask-RESTx (Python). It is too resource-intensive to be hosted on a free server, so the best course of action is to host it locally.
The web-application is dockerized, so please install Docker first. Then, refer to this video (click image, or here) to install and run the application:
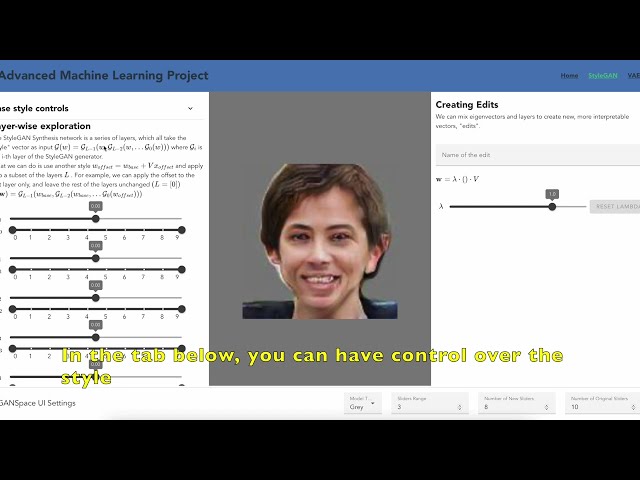
But the general steps are:
git clone https://github.com/thomktz/FaceAI-BGImpact.git
cd FaceAI-BGImpact/webapp
docker compose up --build
Then, in a browser, go to http://localhost:8082
When you're done, don't forget to remove the docker image and container, as they are 5GB in total.
The package is structured as following :
FaceAI-BGImpact
├── faceai_bgimpact
│ ├── configs # Configuration files for models
│ │ ├── default_dcgan_config.py
│ │ └── default_stylegan_config.py
│ │ └── default_vae_config.py
│ ├── data_processing # Scripts and notebooks for data preprocessing
│ │ ├── paths.py # Data paths
│ │ ├── download_raw_ffhq.py # Functions to download raw FFHQ dataset
│ │ ├── create_masks.py # Functions to create masks for FFHQ dataset
│ │ ├── create_blur_and_grey.py # Functions to create blurred and greyed-out FFHQ datasets
│ │ └── download_all_ffhq.py # Functions to download all FFHQ datasets
│ ├── models
│ │ ├── dcgan_ # DCGAN model implementation
│ │ │ ├── dcgan.py
│ │ │ ├── discriminator.py
│ │ │ └── generator.py
│ │ ├── stylegan_ # StyleGAN model implementation
│ │ │ ├── discriminator.py
│ │ │ ├── generator.py
│ │ │ ├── loss.py # Loss functions for StyleGAN
│ │ │ └── stylegan.py
| | ├── vae_ # VAE model implementation
| | | ├── decoder.py
│ │ │ ├── encoder.py
│ │ │ └── vae.py
│ │ ├── abstract_model.py # Abstract model class for common functionalities
│ │ ├── data_loader.py # Data loading utilities
│ │ └── utils.py
│ ├── scripts
│ │ ├── train.py # Script to train models
│ │ ├── create_video.py # Script to create videos from generated images
│ │ ├── generate_images.py
│ │ └── graph_fids.py
│ ├── main.py # Entry point for the package
│ └── Nirmala.ttf # Font file used in the project
├── tests/ # Pytests
├── webapp/ # Web application folder
├── report/ # LaTeX report
├── README.md
└── pyproject.toml # Poetry package management configuration file