ws22 23_chemicals
- Information is published in scientific paper or patents
- The information is not machine-understandable (“hidden” in PDF documents)
- Data is not FAIR (Findability, Accessibility, Interoperability, and Reuse)
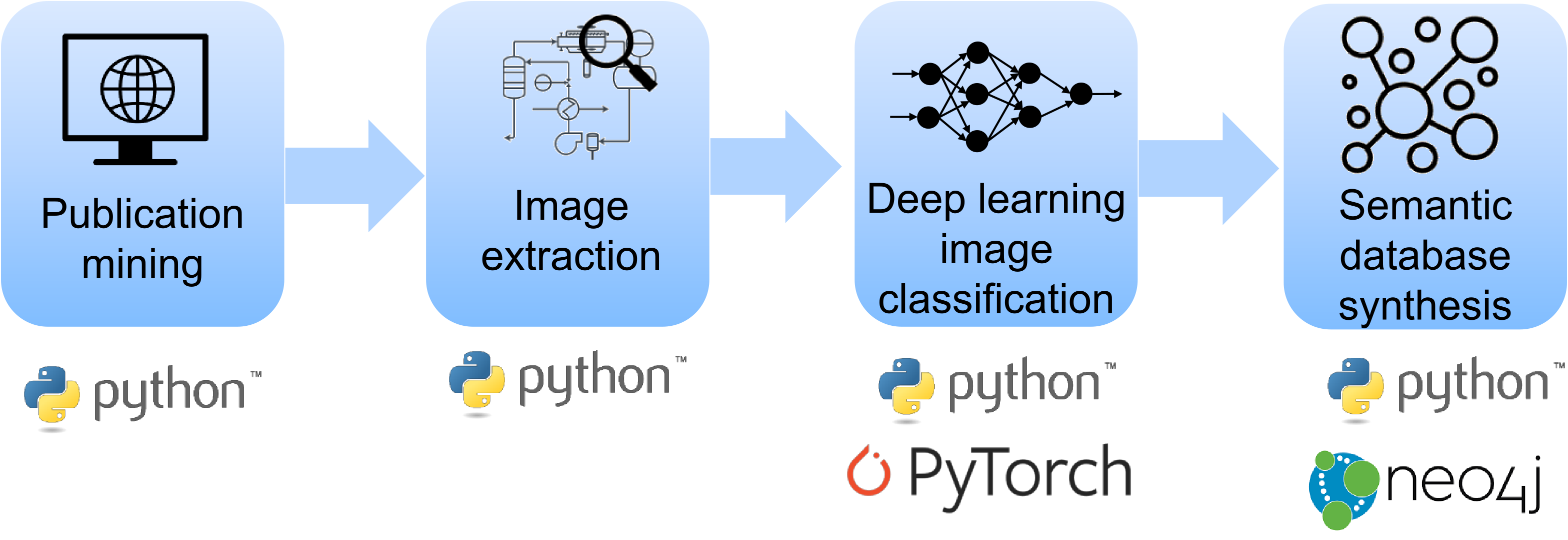
- We aim to extract and structure the “hidden” information from scientific literature and patents
- We focus on figures (images) in patents and publications