dataframe-generator is a simple Python module for generating test CSV datasets from PySpark schemas.
pip install dataframe-generator
The module has a simple CLI, which can be started with the following command:
python -m dataframe_generator
Note that only Python 3 is supported by this module.
As the first step you need to provide the schema of the dataset in the form of StructType definition, e.g.:
first_schema = StructType([
StructField('name', StringType(), False),
StructField('age', IntegerType(), False),
StructField('birth_day', DateType(), True),
StructField('address', StringType(), True)
])
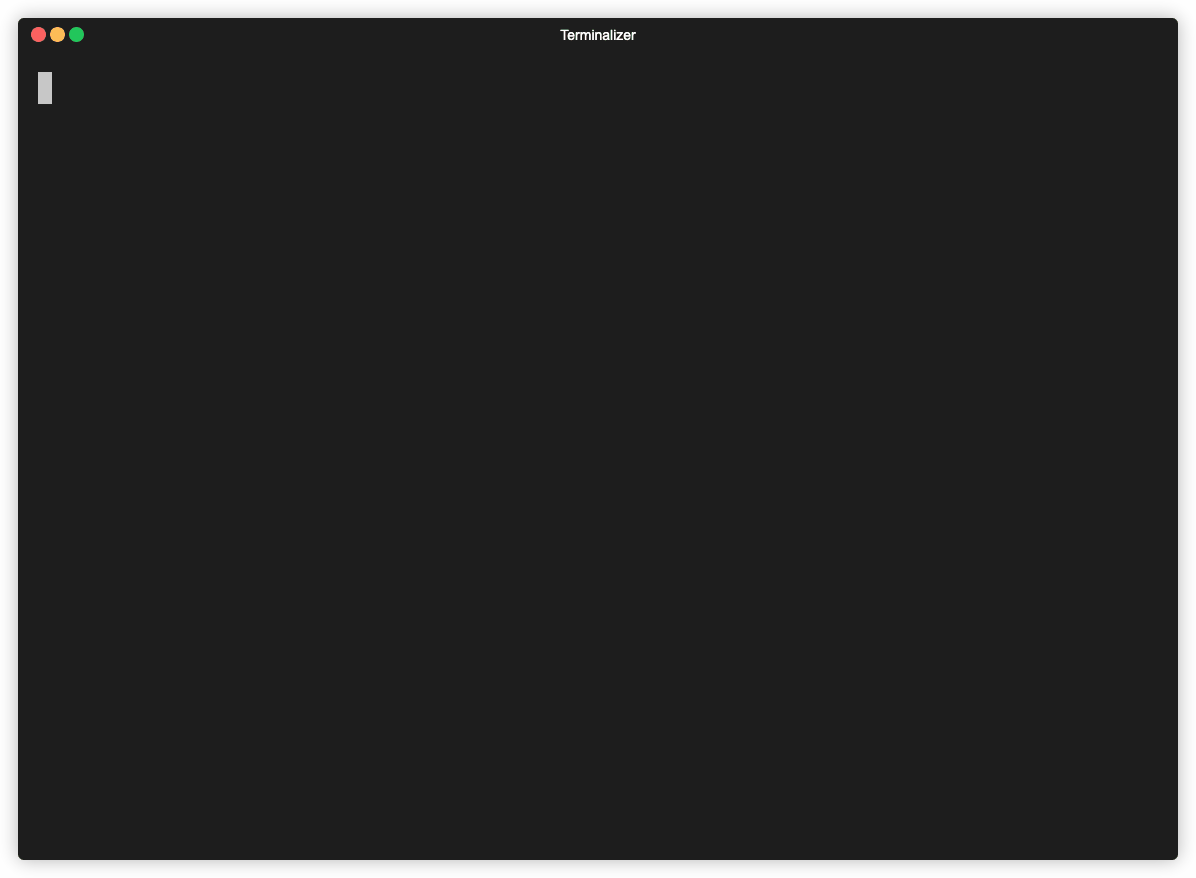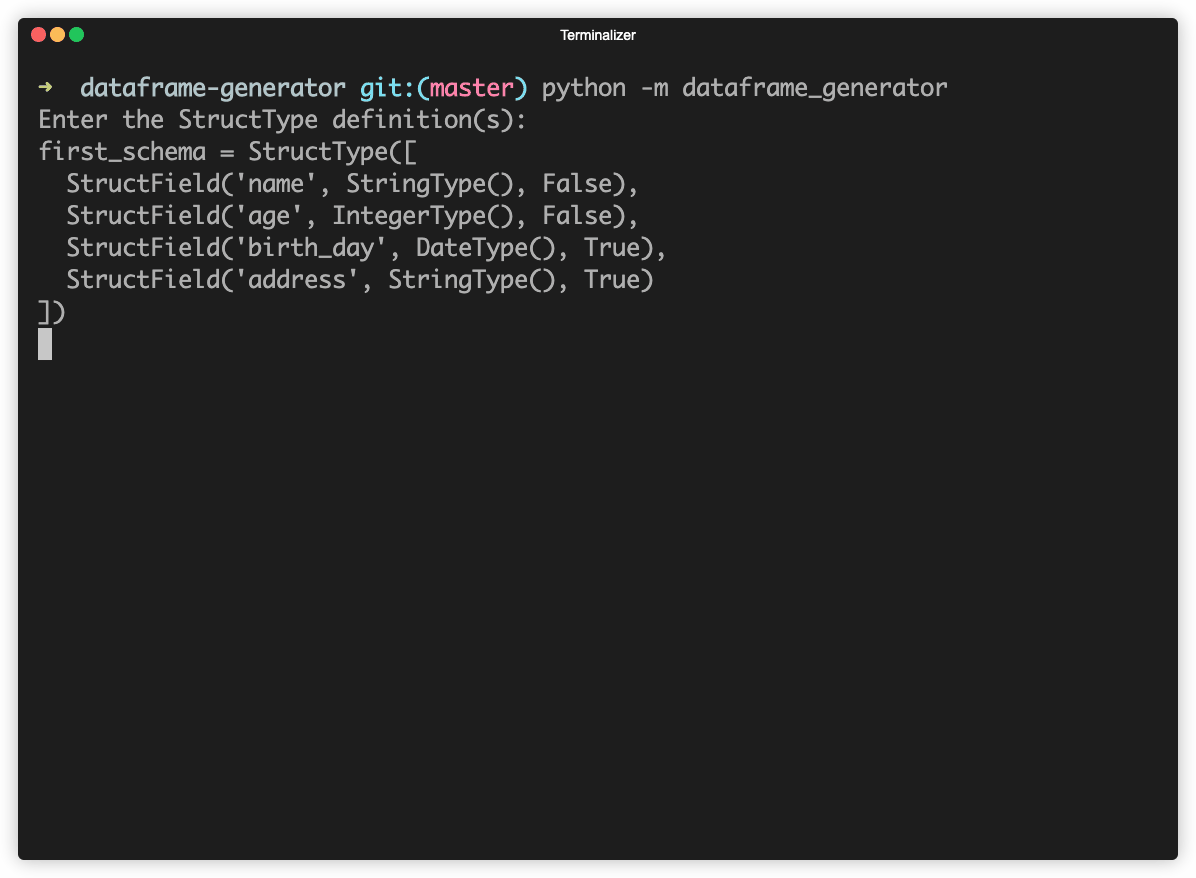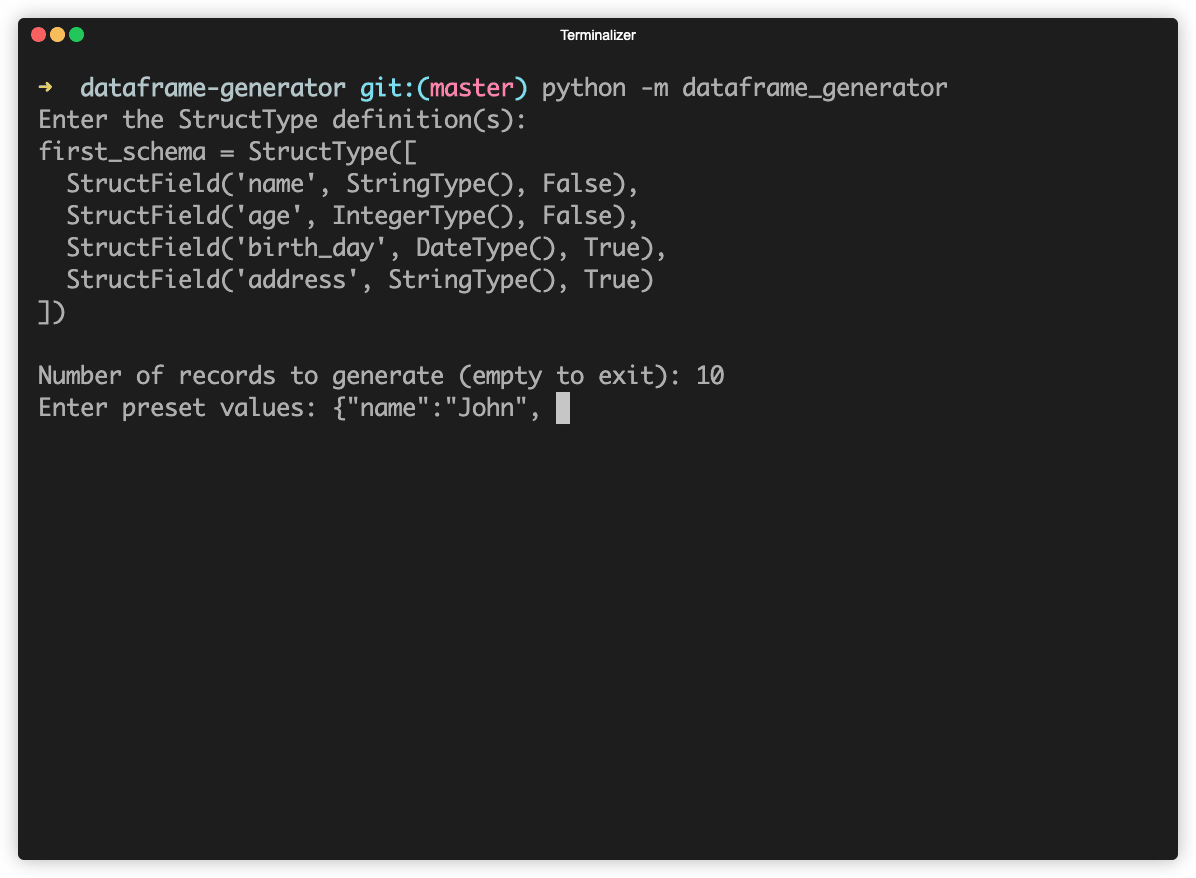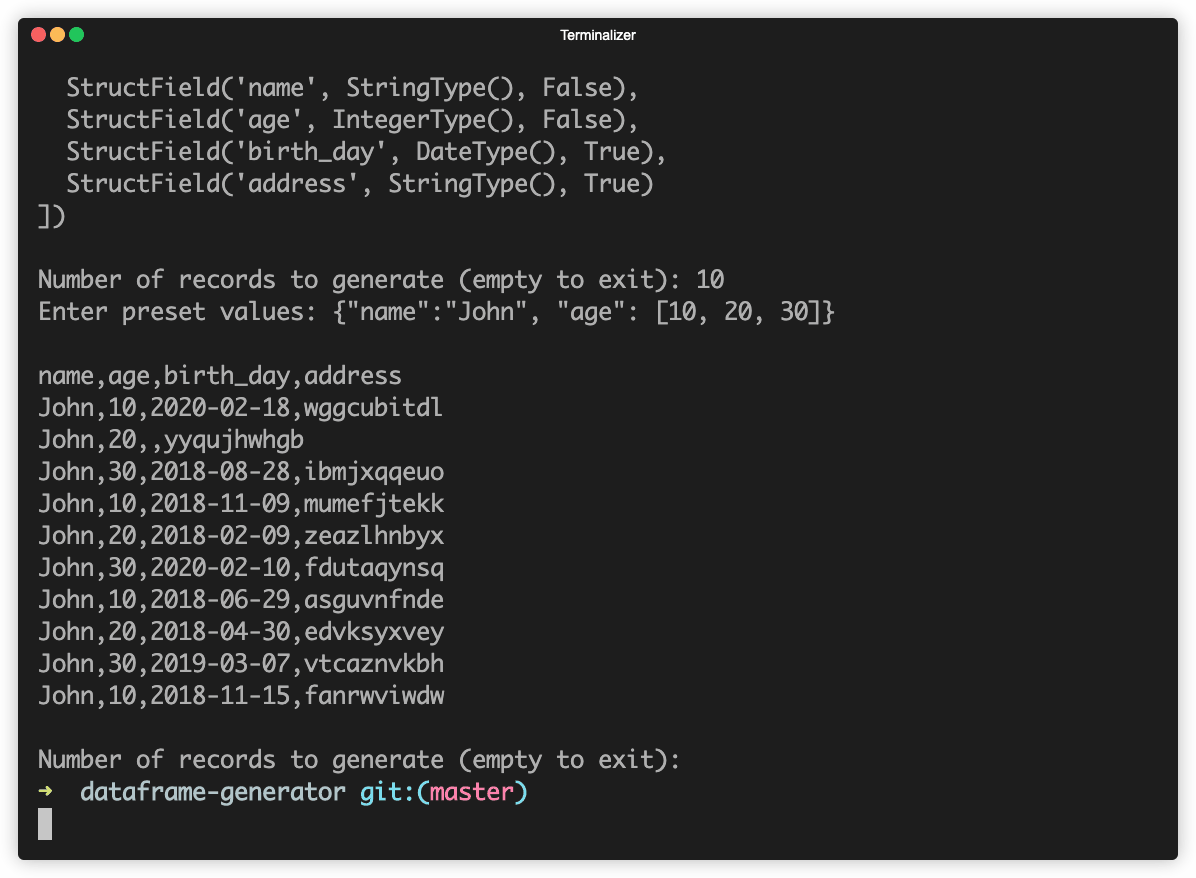
After that just specify the number of desired rows and the potential preset values. Example output:
name,age,birth_day,address
swmpdtafzg,-2140202707,,vnisqzetus
paguzsigqx,1406646118,2018-11-04,ohjxckqdnq
lvnpgnsamp,-2033958134,2018-07-24,rpheidzvgs
vxmzvddepr,353494172,2019-12-23,icyqejjwsa
ylgcktzxcb,1829894295,2019-02-25,ykrnsqjjdl
vfkvsstziy,45380949,2018-03-13,bcajepkfde
csuudyqemr,-1148638844,2019-09-01,
spoaxntbop,76052710,2018-02-16,gxzfbynvtt
lvoxqmklyi,-1445530354,2019-09-21,fkpgxijbdc
ylfcxfscpi,651593707,2019-04-18,atnkksxfgh
For more details see examples below.
ByteType()ShortType()IntegerType()LongType()DecimalType(x, y)StringType()DateType()TimestampType()

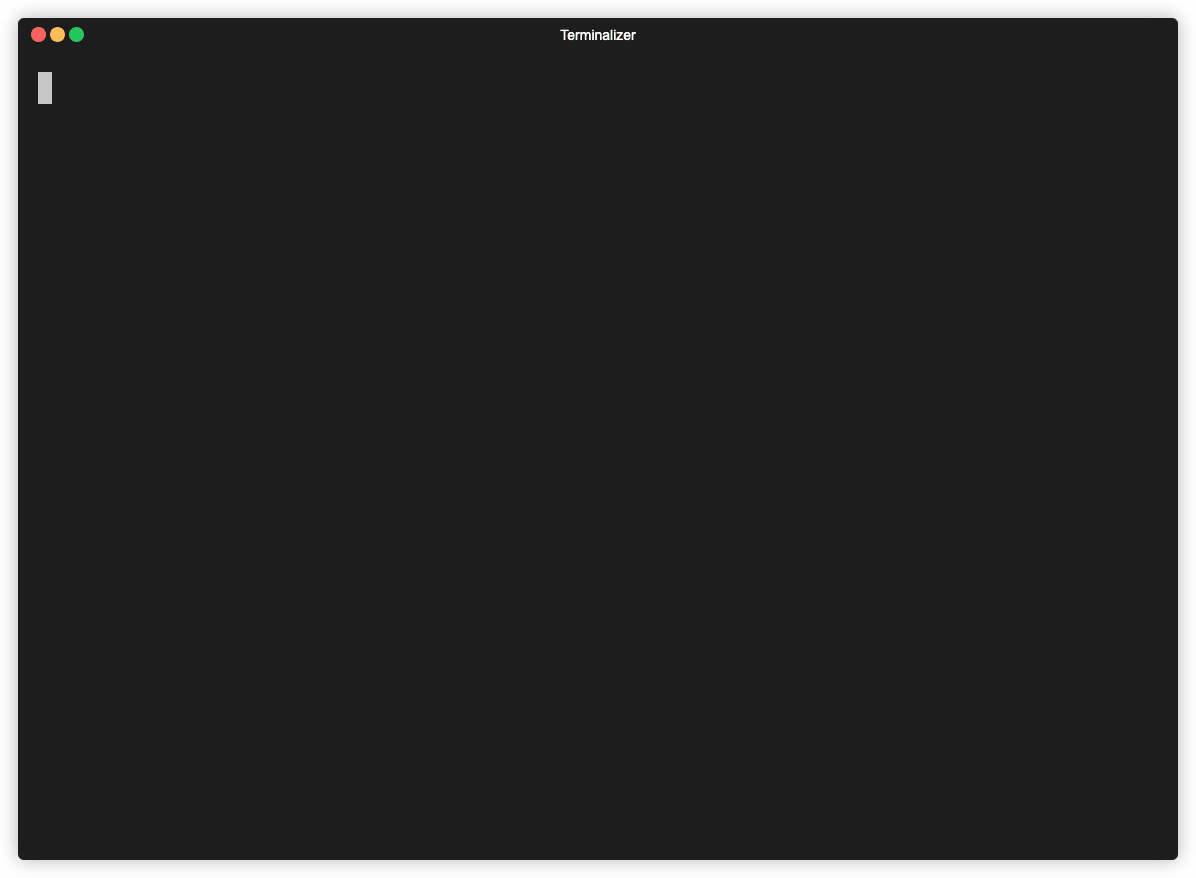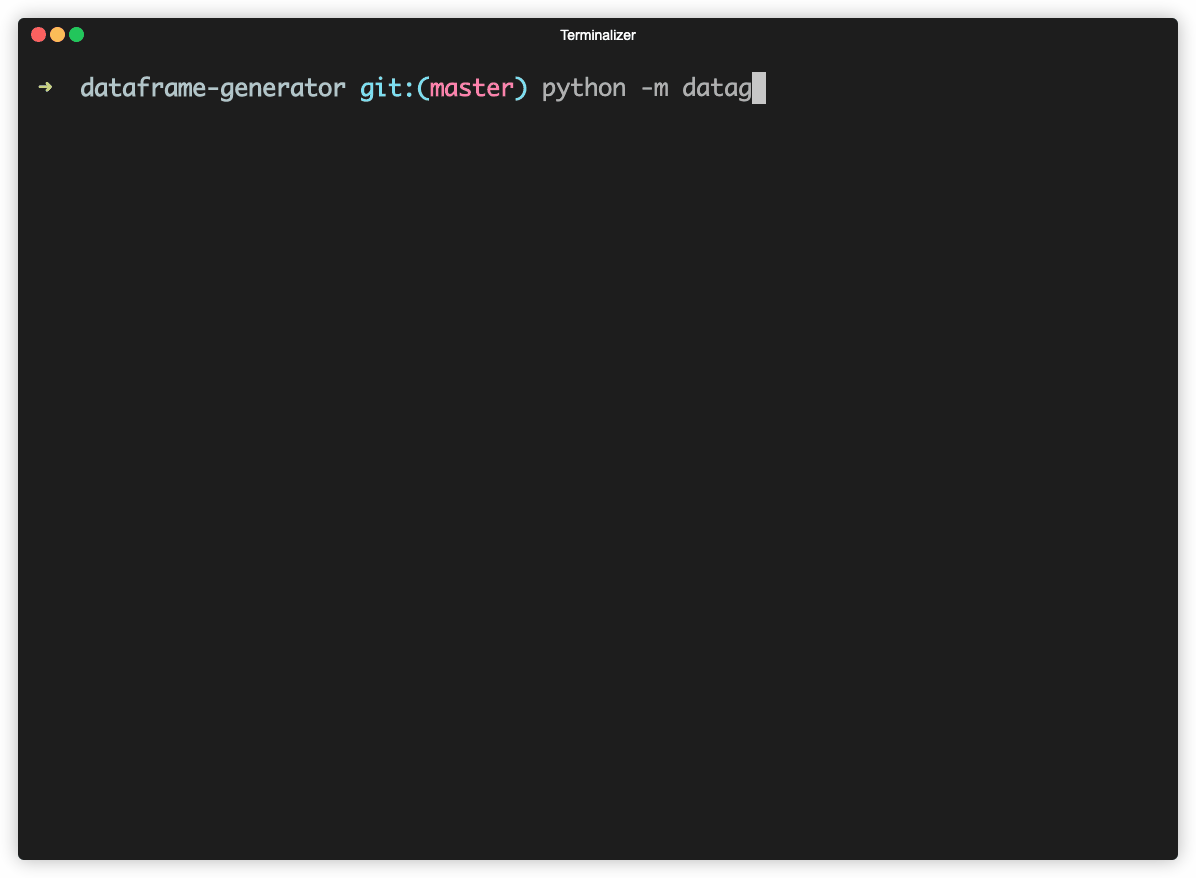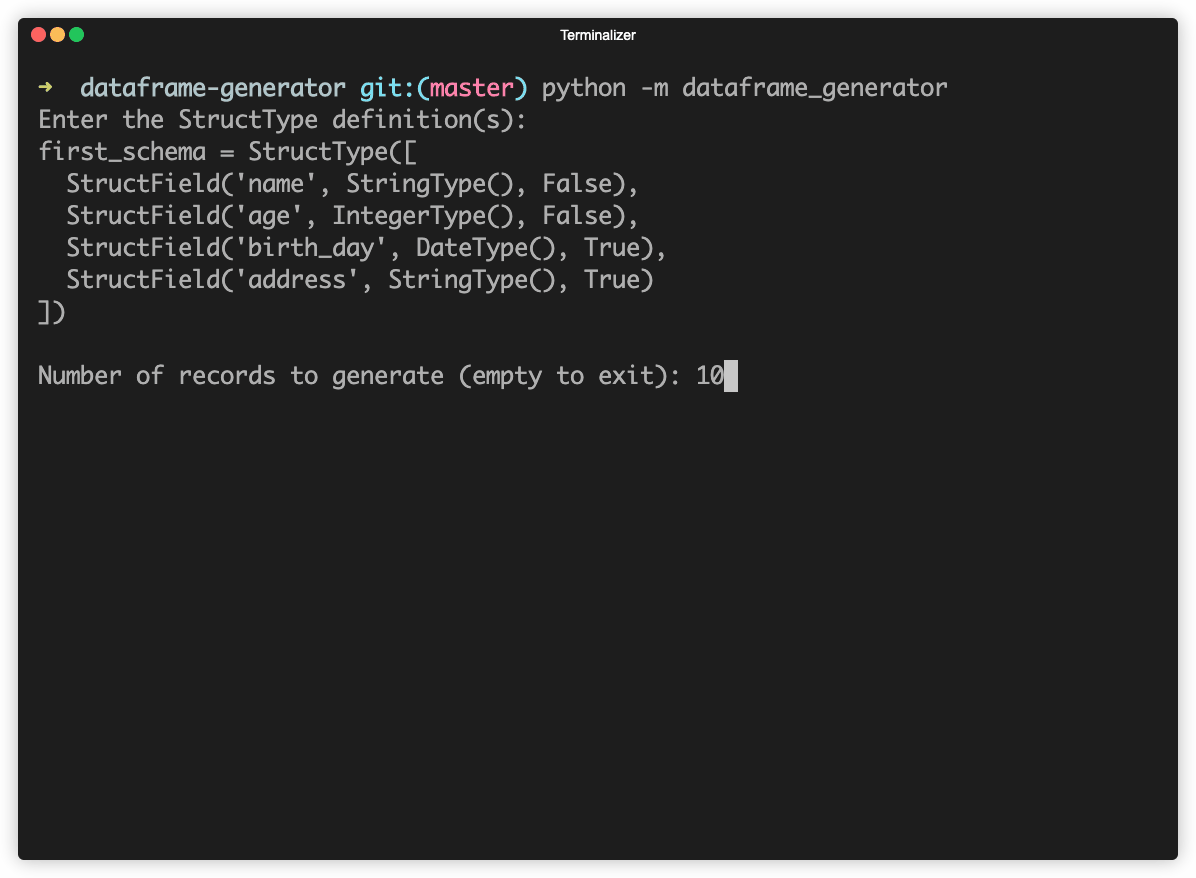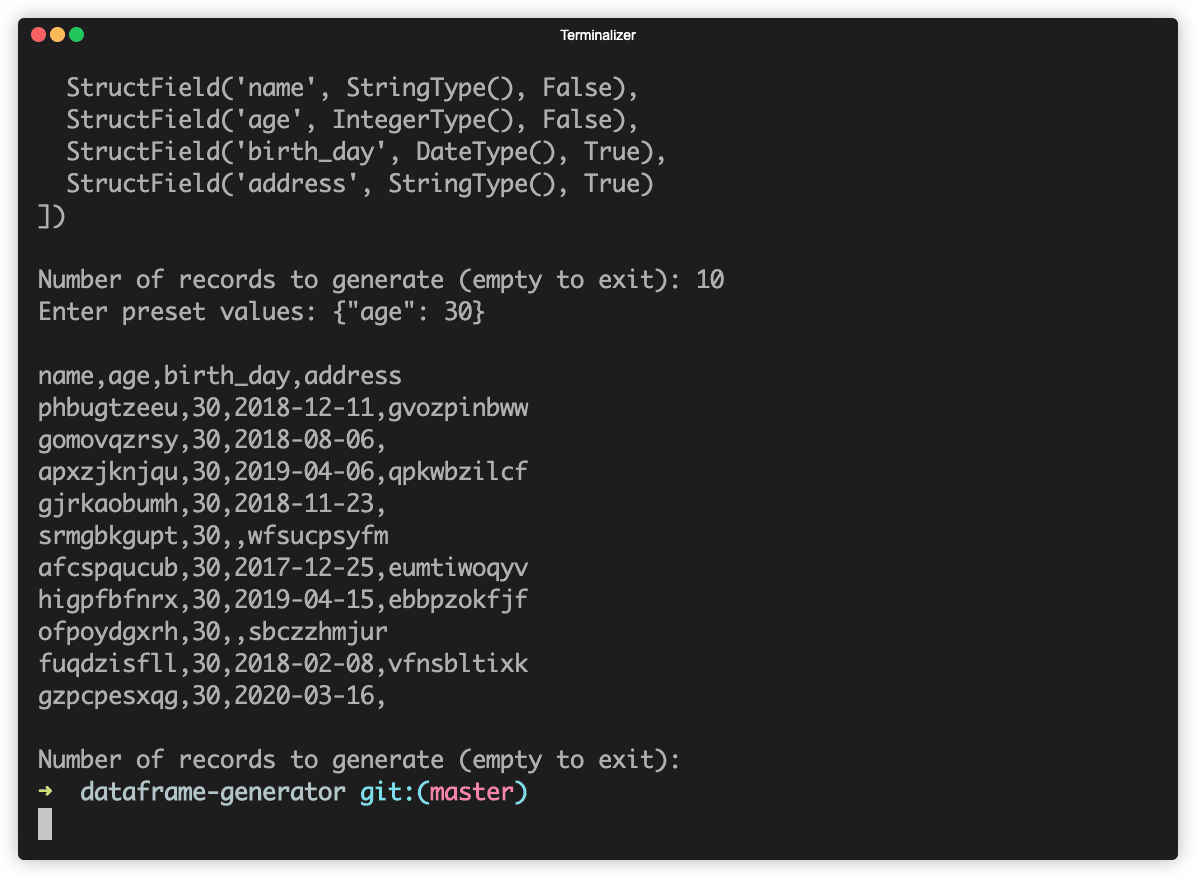
Let's generate a dataset where the age field is fixed to 30.
Let's generate a dataset where the name field is fixed but the age can be
10, 20 or 30.