{kind=link}
This repository hosts data and code for our research paper Large-Scale Classification of IPv4-IPv6 Siblings with Nonlinear Clock Skew presented at TMA'17. You can obtain a preprint from arXiv, and slides, data, talk recording and more from our website
News:
- 2017-07: We have developed a tool that allows sibling classification based on passive observations only and on few datapoints (5-6 TCP Timestamp packets). It is contained under the folder passive_detection.
- 2017-06: Linux Kernel 4.10 will introduce randomized timestamps. Our TMA slides discuss this and its implications.
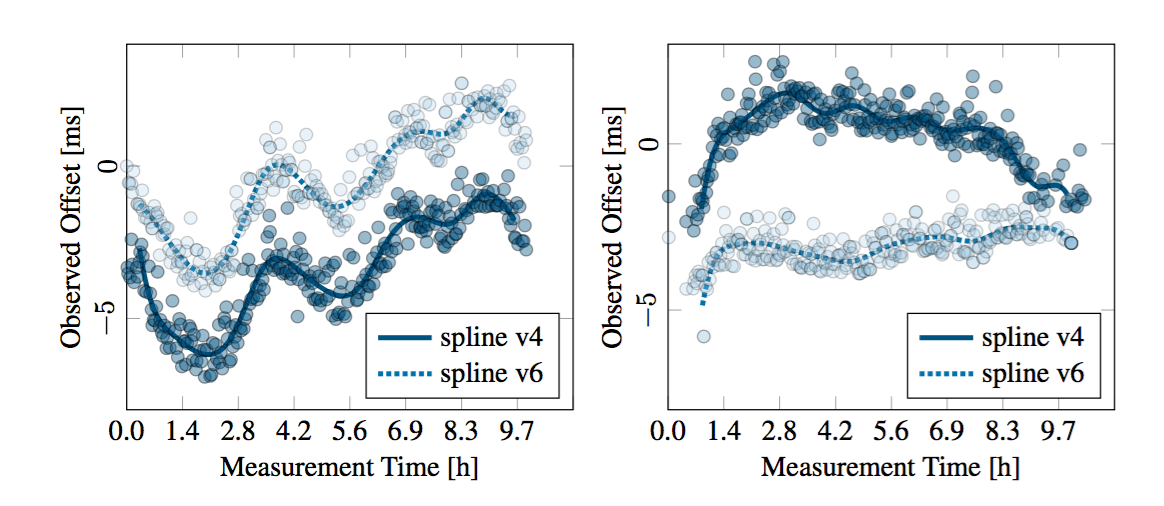
This code can, based on a set of associated A/AAAA DNS records, conduct TCP timestamp measurements and measure the clock skew of remote hosts. Based on this clock skew, it can discern whether a set of IPv4/IPv6 addresses is hosted on the same machine (siblings) or not (non-siblings). Our code also works on nonlinear clock skew using spline fitting:
The ground truth host list is included in this repository. The full ground truth and large scale datasets (including raw measurements) are hosted on our servers due to their size. By using it you agree to our Acceptable Use Policy (see below).
The full dataset is long-term and version-proof hosted by the TUM Library.
It is structured as follows:
gt-$datefolders contain different measurement runs against our ground truthgt{1..7}folders contain evaluations against various ground truth measurements runs -- these folders are accessed byalgo-evalcontains files used for the evaluation of our hand-tuned algorithmlscontains hitlist, measurements, and evaluation of our large-scale measurements
All files above 10M are compressed using .xz. Common file types are:
- .pcap -- raw pcap capture of our measurement run
- .pcap.opts -- extracted TCP options per host from .pcap
- .pcap.ts -- extracted TCP timestamps per host from .pcap
- .decisionlog.log -- meta-data log when creating sibling decisions
- .siblingresult.csv -- output of sibling decision process
Other common files are target lists (hosts.csv), mixed non-sibling lists (__nonsibling), tikz figures (.tikz), and various other log or processing files.
- Resolve DNS files for A/AAAA records (we used massdns)
- Parse DNS answers into sibling candidates, using
dns-to-siblingcands.lua - Optional: scan sibling candidates for open ports and TCP options (we used zmap)
- Optional: parse zmap output and create hitlists for measurement using
zmap-filter-siblings.lua - Optional: If remaining sibling candidates are too many for one run, split them using
siblingcands-split.lua(chunk size definable, we used 10k) - Run the timestamp measurement
measure_ts.py. It takes IP addresses or sibling candidate lists as input and creates a pcap file with the relevant packets. - Now extract the timestamps from the pcap file. For performance reasons, this is done in C++, and requires compilation by typing
make. Then runextract_tsand pipe its output to a .csv file. Confer section Details for a comparison of TS extraction options. - Now call
sibling_decision.py, which takes the sibling/non-sibling decision based on the timestamps. - Under
source/evalreside 3 jupyter notebooks:siblings_mlis the generic notebook to train and test algorithmsalgo-eval_used_versionis a notebook specific to fine-grained evaluation of the hand-tuned algorithmls_evalis a notebook to apply various algorithms to the large-scale dataset
We are eager to expand our sibling ground truth, if you host dual-stacked IPv4/IPv6 addresses and are ok with occasional research scans, please kindly submit this data to us!
Also, code and functionality improvements are highly welcome!
Quirin Scheitle , Oliver Gasser , Minoo Rouhi , and Georg Carle
You may only access the data to conduct research in the context of Sibling analysis. For further research, please contact us regarding authorization.
Several options proved unable to process large (15GB) pcap files in reasonable (<15min) time:
- tshark used up 24G of RAM and crashed, terribly slow on smaller files. Internet says it does elaborate flow tracking which we do not need
- scapy was terribly slow, a pure read loop would take ~30 minutes for just 1GB
- pyshark was faster, ~5 minutes for 1GB
- Ridiculous: tcpdump to text, then parsing from python takes roughly 60 seconds per file. However, the regex is complex and error-prone (multi-line!), and producing large unstructured text files from a nice binary format hurts
- The C++ solution parses 1GB in 50 seconds :)