forked from zivong/jekyll-theme-hydure
-
Notifications
You must be signed in to change notification settings - Fork 37
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
1 changed file
with
127 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,127 @@ | ||
| --- | ||
| layout: post | ||
| title: AI Music & Voice | ||
| author: [Richard Kuo] | ||
| category: [Lecture] | ||
| tags: [jekyll, ai] | ||
| --- | ||
|
|
||
| This introduction includes Music Seperationm, Deep Singer, Voice Conversion, Voice Cloning, etc. | ||
|
|
||
| --- | ||
| ## Music Seperation | ||
| ### Spleeter | ||
| **Paper:** [Spleeter: A FAST AND STATE-OF-THE ART MUSIC SOURCE | ||
| SEPARATION TOOL WITH PRE-TRAINED MODELS](https://archives.ismir.net/ismir2019/latebreaking/000036.pdf)<br> | ||
| **Code:** [deezer/spleeter](https://github.com/deezer/spleeter)<br> | ||
|
|
||
| --- | ||
| ### Wave-U-Net | ||
| **Paper:** [Wave-U-Net: A Multi-Scale Neural Network for End-to-End Audio Source Separation](https://arxiv.org/abs/1806.03185)<br> | ||
| **Code:** [f90/Wave-U-Net](https://github.com/f90/Wave-U-Net)<br> | ||
|
|
||
|  | ||
|
|
||
| --- | ||
| ### Hyper Wave-U-Net | ||
| **Paper:** [Improving singing voice separation with the Wave-U-Net using Minimum Hyperspherical Energy](https://arxiv.org/abs/1910.10071)<br> | ||
| **Code:** [jperezlapillo/hyper-wave-u-net](https://github.com/jperezlapillo/hyper-wave-u-net)<br> | ||
| **MHE regularisation:**<br> | ||
|  | ||
|
|
||
| --- | ||
| ### Demucs | ||
| **Paper:** [Music Source Separation in the Waveform Domain](https://arxiv.org/abs/1911.13254)<br> | ||
| **Code:** [facebookresearch/demucs](https://github.com/facebookresearch/demucs)<br> | ||
|
|
||
| 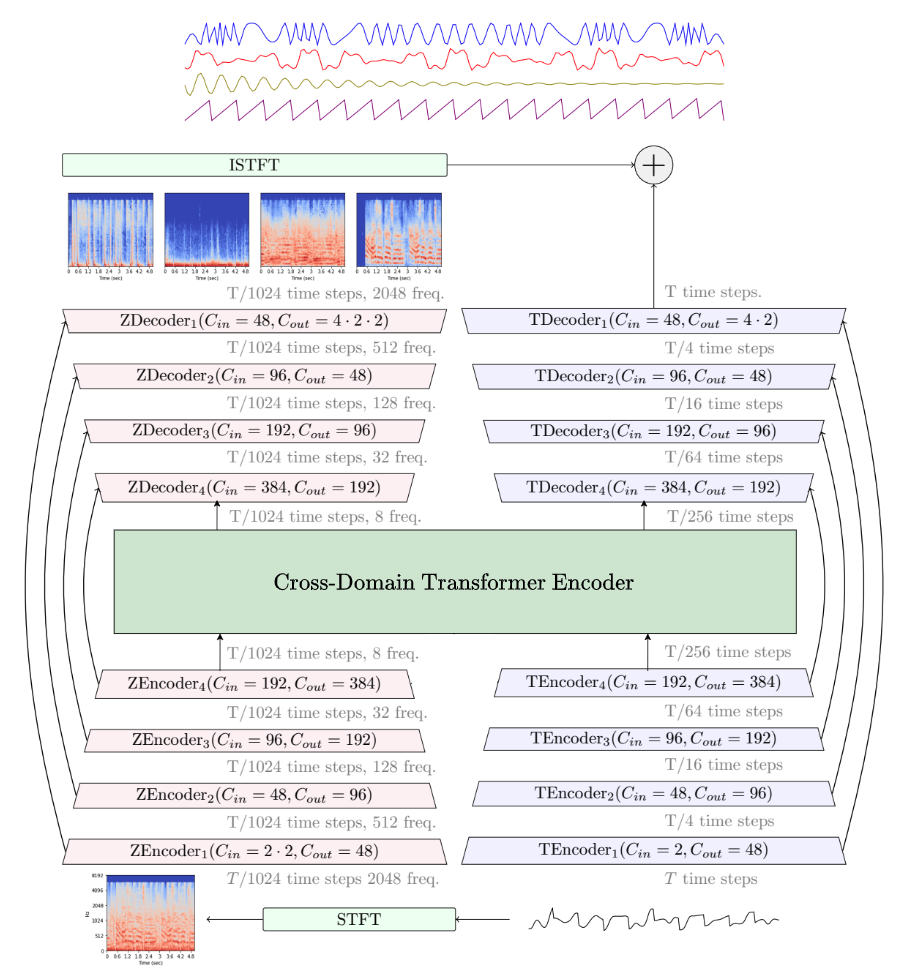 | ||
|
|
||
| --- | ||
| ## Deep Singer | ||
|
|
||
| ### [OpenAI Jukebox](https://jukebox.openai.com/) | ||
| **Blog:** [Jukebox](https://openai.com/blog/jukebox/)<br> | ||
| model modified from **VQ-VAE-2** | ||
| **Paper:** [Jukebox: A Generative Model for Music](https://arxiv.org/abs/2005.00341)<br> | ||
| **Colab:** [Interacting with Jukebox](https://colab.research.google.com/github/openai/jukebox/blob/master/jukebox/Interacting_with_Jukebox.ipynb)<br> | ||
|
|
||
| --- | ||
| ### DeepSinger | ||
| **Blog:** [Microsoft’s AI generates voices that sing in Chinese and English](https://venturebeat.com/2020/07/13/microsofts-ai-generates-voices-that-sing-in-chinese-and-english/)<br> | ||
| **Paper:** [DeepSinger: Singing Voice Synthesis with Data Mined From the Web](https://arxiv.org/abs/2007.04590)<br> | ||
| **Demo:** [DeepSinger: Singing Voice Synthesis with Data Mined From the Web](https://speechresearch.github.io/deepsinger/)<br> | ||
|
|
||
| 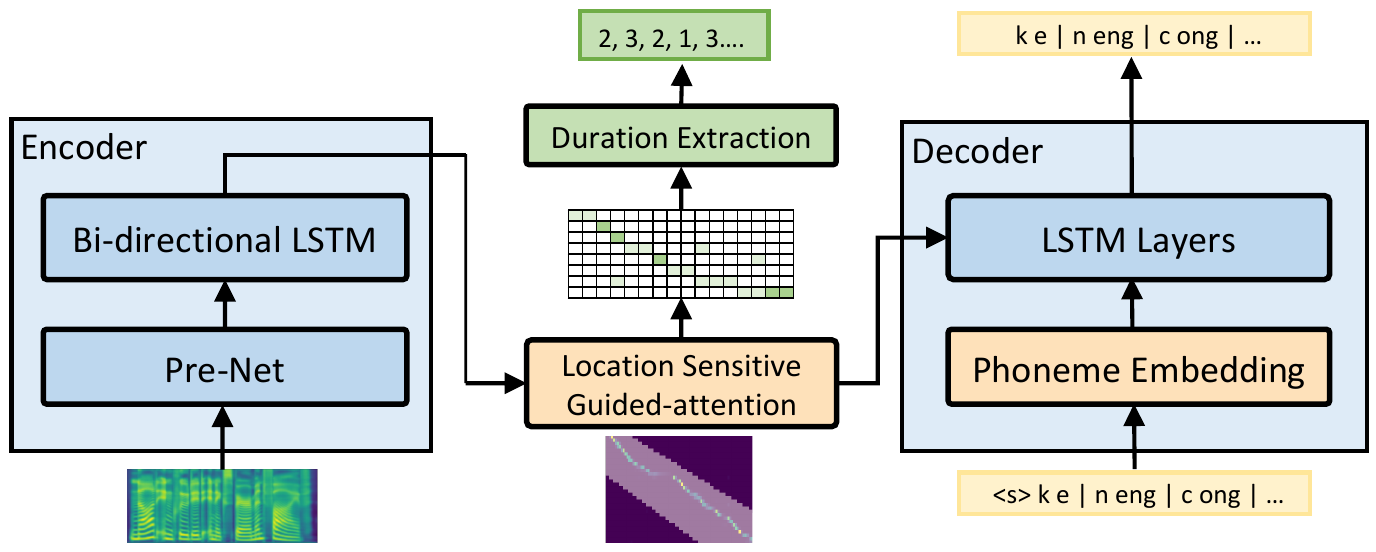 | ||
| <p align="center">The alignment model based on the architecture of automatic speech recognition</p> | ||
|
|
||
| 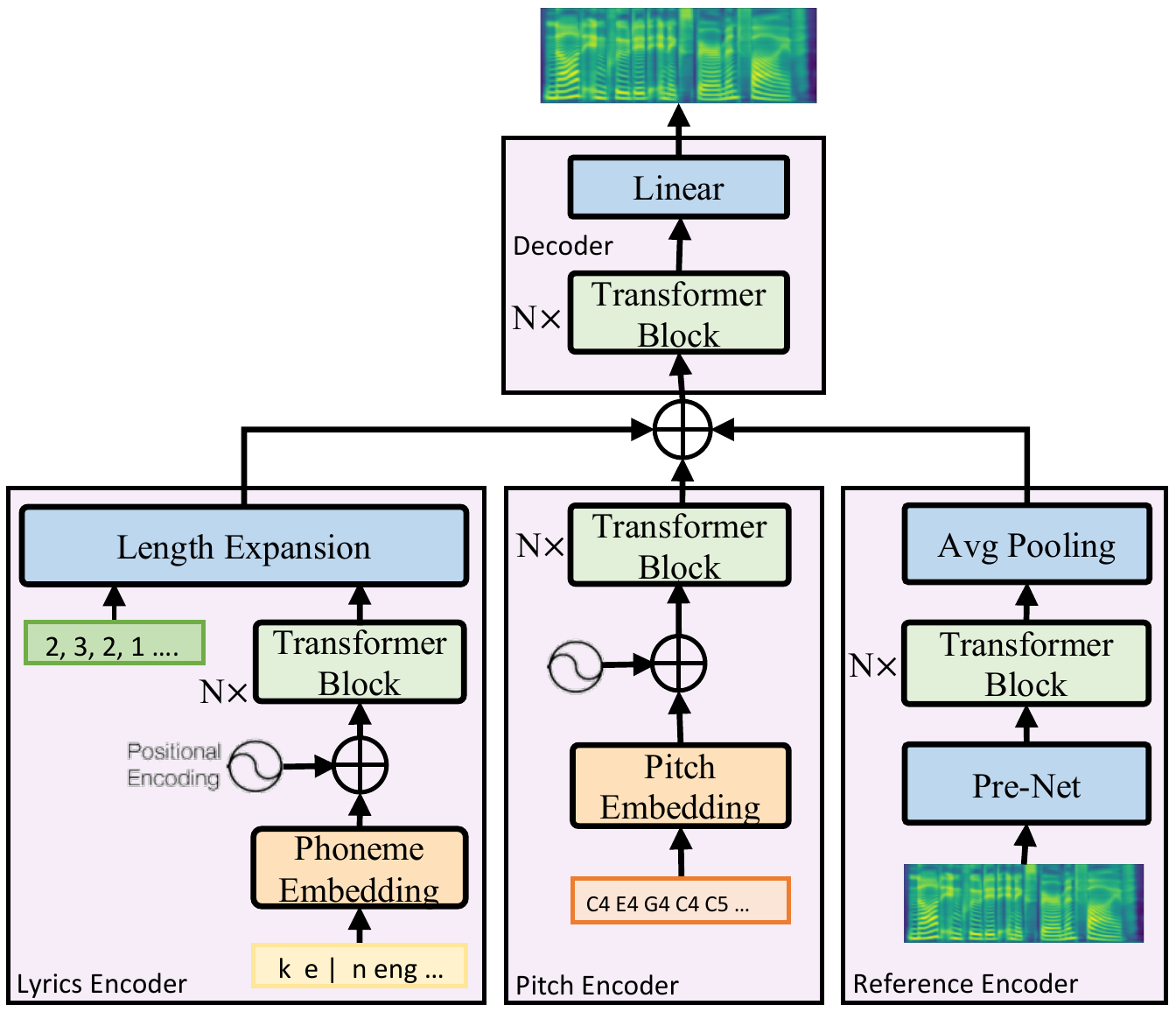 | ||
| <p align="center">The architecture of the singing model</p> | ||
|
|
||
| 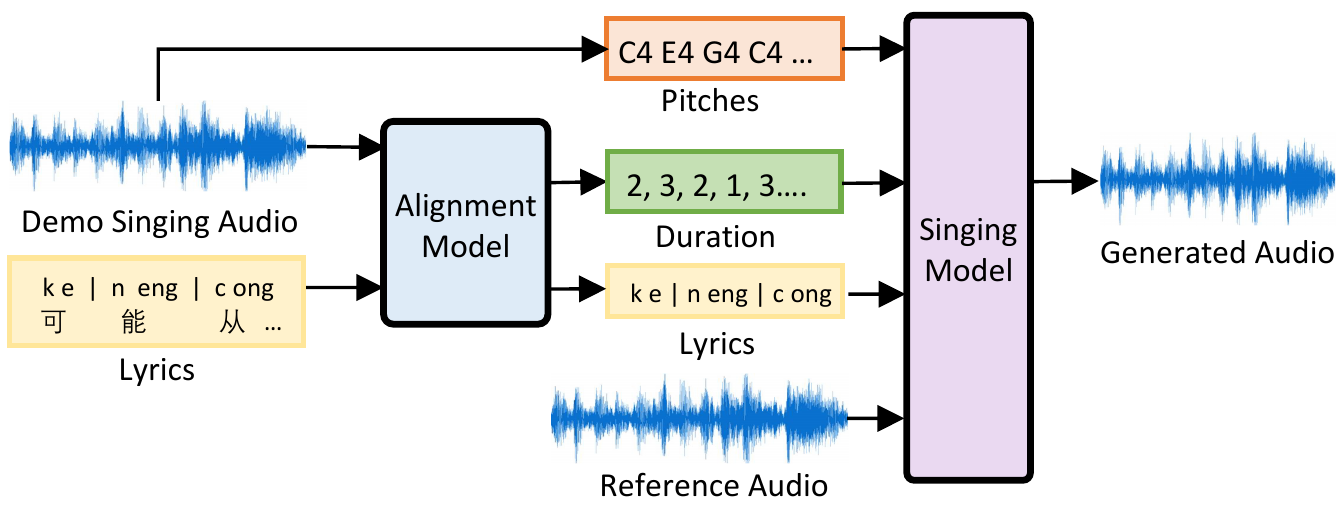 | ||
| <p align="center">The inference process of singing voice synthesis</p> | ||
|
|
||
| --- | ||
| ## Voice Conversion | ||
| **Paper:** [An Overview of Voice Conversion and its Challenges: From Statistical Modeling to Deep Learning](https://arxiv.org/abs/2008.03648)<br> | ||
|
|
||
|  | ||
|
|
||
| **Blog:** [Voice Cloning Using Deep Learning](https://medium.com/the-research-nest/voice-cloning-using-deep-learning-166f1b8d8595)<br> | ||
|
|
||
| --- | ||
| ### Deep Voice 3 | ||
| **Blog:** [Deep Voice 3: Scaling Text to Speech with Convolutional Sequence Learning](https://medium.com/a-paper-a-day-will-have-you-screaming-hurray/day-6-deep-voice-3-scaling-text-to-speech-with-convolutional-sequence-learning-16c3e8be4eda)<br> | ||
| **Paper:** [Deep Voice 3: Scaling Text-to-Speech with Convolutional Sequence Learning](https://arxiv.org/abs/1710.07654)<br> | ||
| **Code:** [r9y9/deepvoice3_pytorch](https://github.com/r9y9/deepvoice3_pytorch)<br> | ||
| **Code:** [Kyubyong/deepvoice3](https://github.com/Kyubyong/deepvoice3)<br> | ||
|
|
||
|  | ||
|
|
||
| --- | ||
| ### Neural Voice Cloning | ||
| **Paper:** [Neural Voice Cloning with a Few Samples](https://arxiv.org/abs/1802.06006)<br> | ||
| **Code:** [SforAiDl/Neural-Voice-Cloning-With-Few-Samples](https://github.com/SforAiDl/Neural-Voice-Cloning-With-Few-Samples)<br> | ||
|
|
||
|  | ||
|
|
||
| --- | ||
| ### SV2TTS | ||
| **Blog:** [Voice Cloning: Corentin's Improvisation On SV2TTS](https://www.datasciencecentral.com/profiles/blogs/voice-cloning-corentin-s-improvisation-on-sv2tts)<br> | ||
| **Paper:** [Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis](https://arxiv.org/abs/1806.04558)<br> | ||
| **Code:** [CorentinJ/Real-Time-Voice-Cloning](https://github.com/CorentinJ/Real-Time-Voice-Cloning)<br> | ||
|
|
||
|  | ||
|
|
||
| **Synthesizer** : The synthesizer is Tacotron2 without Wavenet<br> | ||
|  | ||
|
|
||
| **SV2TTS Toolbox**<br> | ||
| <iframe width="1148" height="646" src="https://www.youtube.com/embed/-O_hYhToKoA" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe> | ||
|
|
||
| --- | ||
| ### MelGAN-VC | ||
| **Paper:** [MelGAN-VC: Voice Conversion and Audio Style Transfer on arbitrarily long samples using Spectrograms](https://arxiv.org/abs/1910.03713)<br> | ||
| **Code:** [marcoppasini/MelGAN-VC](https://github.com/marcoppasini/MelGAN-VC)<br> | ||
|
|
||
|  | ||
|
|
||
| --- | ||
| ### Vocoder-free End-to-End Voice Conversion | ||
| **Paper:** [Vocoder-free End-to-End Voice Conversion with Transformer Network](https://arxiv.org/abs/2002.03808)<br> | ||
| **Code:** [kaen2891/kaen2891.github.io](https://github.com/kaen2891/kaen2891.github.io)<br> | ||
|
|
||
|  | ||
|
|
||
| --- | ||
| ### ConVoice | ||
| **Paper:** [ConVoice: Real-Time Zero-Shot Voice Style Transfer with Convolutional Network](https://arxiv.org/abs/2005.07815)<br> | ||
| **Demo:** [ConVoice: Real-Time Zero-Shot Voice Style Transfer](https://rebryk.github.io/convoice-demo/)<br> | ||
|
|
||
|  | ||
|
|
||
| <br> | ||
| <br> | ||
|
|
||
| *This site was last updated {{ site.time | date: "%B %d, %Y" }}.* | ||
|
|
||
|
|