forked from zivong/jekyll-theme-hydure
-
Notifications
You must be signed in to change notification settings - Fork 37
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
3 changed files
with
1,278 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,263 @@ | ||
| --- | ||
| layout: post | ||
| title: Generative Neural Networks | ||
| author: [Richard Kuo] | ||
| category: [Lecture] | ||
| tags: [jekyll, ai] | ||
| --- | ||
|
|
||
| This introduction includes Style Transfer, Vartional Autoencoders (VAEs), Text-to-Image, Text-to-Video, Text-to-Motion. | ||
|
|
||
| --- | ||
| ## Style Transfer | ||
|
|
||
| ### DeepDream | ||
| **Blog:** [Inceptionism: Going Deeper into Neural Networks](https://blog.research.google/2015/06/inceptionism-going-deeper-into-neural.html)<br> | ||
|  | ||
|
|
||
| --- | ||
| ### Nerual Style Transfer | ||
| **Paper:** [A Neural Algorithm of Artistic Style](https://arxiv.org/abs/1508.06576)<br> | ||
| **Code:** [ProGamerGov/neural-style-pt](https://github.com/ProGamerGov/neural-style-pt)<br> | ||
| **Tutorial:** [Neural Transfer using PyTorch](https://pytorch.org/tutorials/advanced/neural_style_tutorial.html) | ||
|
|
||
|  | ||
| 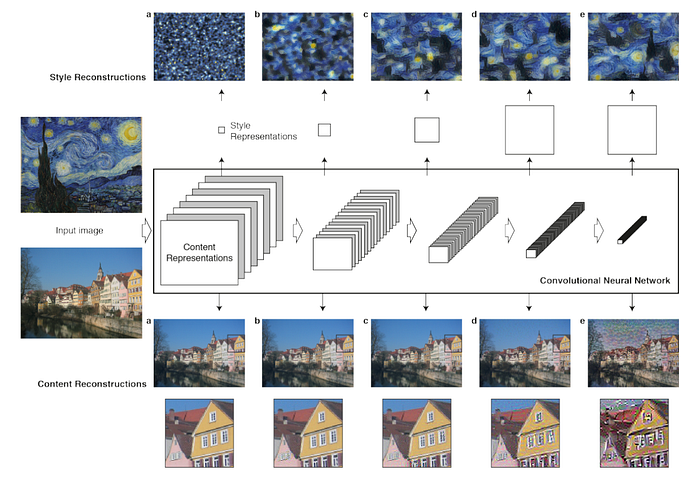 | ||
|
|
||
| --- | ||
| ### Fast Style Transfer | ||
| **Paper:**[A Neural Algorithm of Artistic Style](https://arxiv.org/abs/1508.06576) & [Perceptual Losses for Real-Time Style Transfer and Super-Resolution](https://arxiv.org/abs/1603.08155)<br> | ||
| **Code:** [lengstrom/fast-style-transfer](https://github.com/lengstrom/fast-style-transfer)<br> | ||
|
|
||
| <table> | ||
| <tr> | ||
| <td><img src="https://github.com/lengstrom/fast-style-transfer/raw/master/examples/style/udnie.jpg?raw=true"></td> | ||
| <td><img src="https://github.com/lengstrom/fast-style-transfer/blob/master/examples/content/stata.jpg?raw=true"></td> | ||
| <td><img src="https://github.com/lengstrom/fast-style-transfer/blob/master/examples/results/stata_udnie.jpg?raw=true"></td> | ||
| </tr> | ||
| </table> | ||
|
|
||
| ## Variational AutoEncoder (VAE) | ||
|
|
||
| ### VAE | ||
| **Blog:** [VAE(Variational AutoEncoder) 實作](https://ithelp.ithome.com.tw/articles/10226549)<br> | ||
| **Paper:** [Auto-Encoding Variational Bayes](https://arxiv.org/abs/1312.6114)<br> | ||
| **Code:** [rkuo2000/fashionmnist-vae](https://www.kaggle.com/rkuo2000/fashionmnist-vae)<br> | ||
|
|
||
|  | ||
|  | ||
| 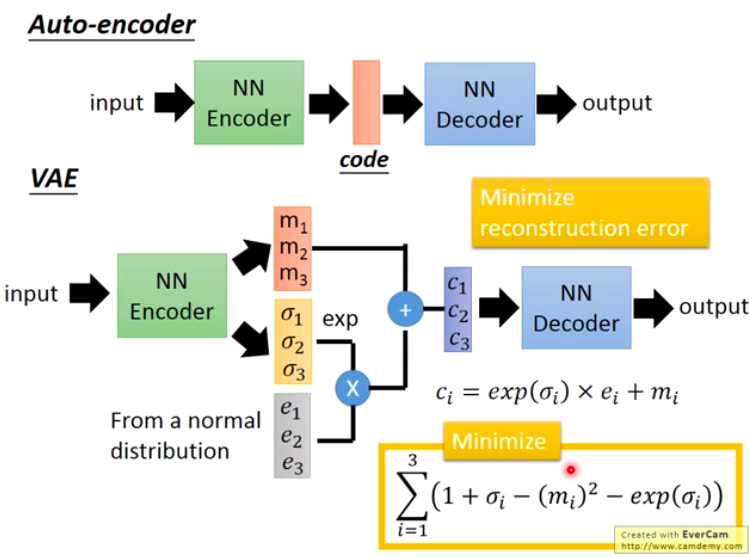 | ||
|
|
||
| --- | ||
| ### Arbitrary Style Transfer | ||
| **Paper:** [Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization](https://arxiv.org/abs/1703.06868)<br> | ||
| **Code:** [elleryqueenhomels/arbitrary_style_transfer](https://github.com/elleryqueenhomels/arbitrary_style_transfer)<br> | ||
| 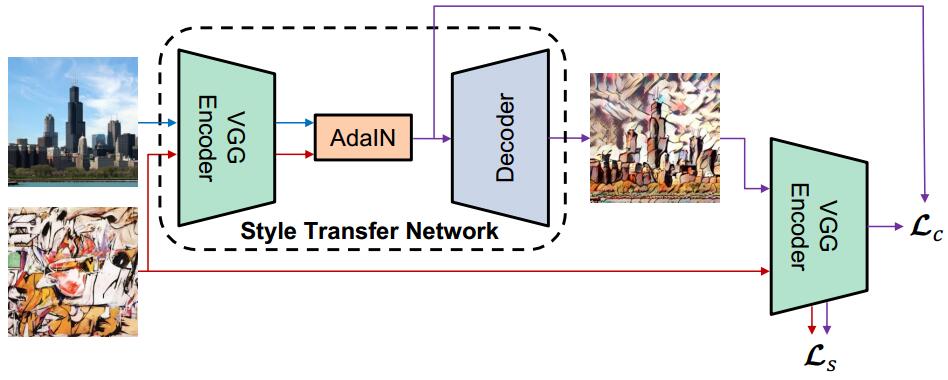 | ||
|
|
||
| <table> | ||
| <tr> | ||
| <td><img width="50%" height="50%" src="https://github.com/elleryqueenhomels/arbitrary_style_transfer/raw/master/images/style_thumb/udnie_thumb.jpg?raw=true"></td> | ||
| <td><img width="50%" height="50%" src="https://github.com/elleryqueenhomels/arbitrary_style_transfer/raw/master/outputs/udnie-lance-2.0.jpg?raw=true"></td> | ||
| </tr> | ||
| <tr> | ||
| <td><img width="50%" height="50%" src="https://github.com/elleryqueenhomels/arbitrary_style_transfer/raw/master/images/style_thumb/escher_sphere_thumb.jpg?raw=true"></td> | ||
| <td><img width="50%" height="50%" src="https://github.com/elleryqueenhomels/arbitrary_style_transfer/raw/master/outputs/escher_sphere-lance-2.0.jpg?raw=true"></td> | ||
| </tr> | ||
| <tr> | ||
| <td><img width="50%" height="50%" src="https://github.com/elleryqueenhomels/arbitrary_style_transfer/raw/master/images/style_thumb/mosaic_thumb.jpg?raw=true"></td> | ||
| <td><img width="50%" height="50%" src="https://github.com/elleryqueenhomels/arbitrary_style_transfer/raw/master/outputs/mosaic-lance-2.0.jpg?raw=true"></td> | ||
| </tr> | ||
| </table> | ||
|
|
||
| ### zi2zi | ||
| **Blog:** [zi2zi: Master Chinese Calligraphy with Conditional Adversarial Networks](https://kaonashi-tyc.github.io/2017/04/06/zi2zi.html)<br> | ||
| **Paper:** [Generating Handwritten Chinese Characters using CycleGAN](https://arxiv.org/abs/1801.08624)<br> | ||
| **Code:** [kaonashi-tyc/zi2zi](https://github.com/kaonashi-tyc/zi2zi)<br> | ||
|
|
||
|  | ||
| 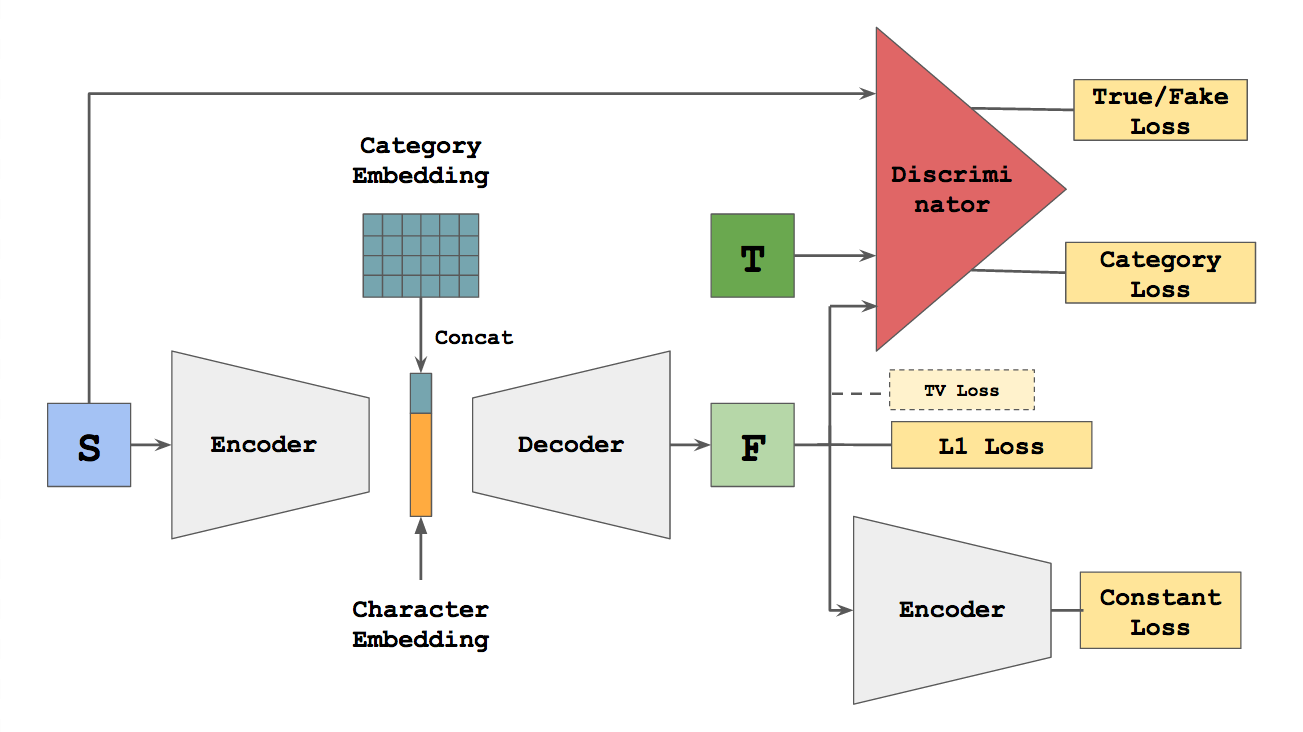 | ||
|
|
||
| --- | ||
| ### AttentionHTR | ||
| **Paper:** [AttentionHTR: Handwritten Text Recognition Based on Attention Encoder-Decoder Networks](https://arxiv.org/abs/2201.09390)<br> | ||
| 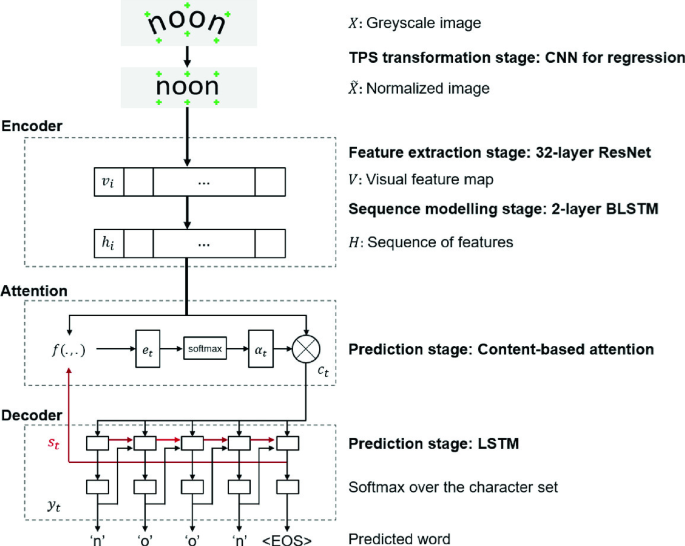 | ||
|
|
||
| **Github:** [https://github.com/dmitrijsk/AttentionHTR](https://github.com/dmitrijsk/AttentionHTR)<br> | ||
| **Kaggle:** [https://www.kaggle.com/code/rkuo2000/attentionhtr](https://www.kaggle.com/code/rkuo2000/attentionhtr)<br> | ||
|  | ||
|
|
||
| --- | ||
| ## Text-to-Image | ||
|
|
||
| **News:** [An A.I.-Generated Picture Won an Art Prize. Artists Aren’t Happy.](https://www.nytimes.com/2022/09/02/technology/ai-artificial-intelligence-artists.html)<br> | ||
|  | ||
|
|
||
| **Blog:** [DALL-E, DALL-E2 and StoryDALL-E](https://zhangtemplar.github.io/dalle/)<br> | ||
|
|
||
| --- | ||
| ### DALL.E | ||
| DALL·E is a 12-billion parameter version of GPT-3 trained to generate images from text descriptions, using a dataset of text–image pairs. <br> | ||
|
|
||
| **Blog:** [https://openai.com/blog/dall-e/](https://openai.com/blog/dall-e/)<br> | ||
| **Paper:** [Zero-Shot Text-to-Image Generation](https://arxiv.org/abs/2102.12092)<br> | ||
| **Code:** [openai/DALL-E](https://github.com/openai/DALL-E)<br> | ||
|
|
||
| The overview of DALL-E could be illustrated as below. It contains two components: for image, VQGAN (vector quantized GAN) is used to map the 256x256 image to a 32x32 grid of image token and each token has 8192 possible values; then this token is combined with 256 BPE=encoded text token is fed into to train the autoregressive transformer. The text token is set to 256 by maximal. | ||
| 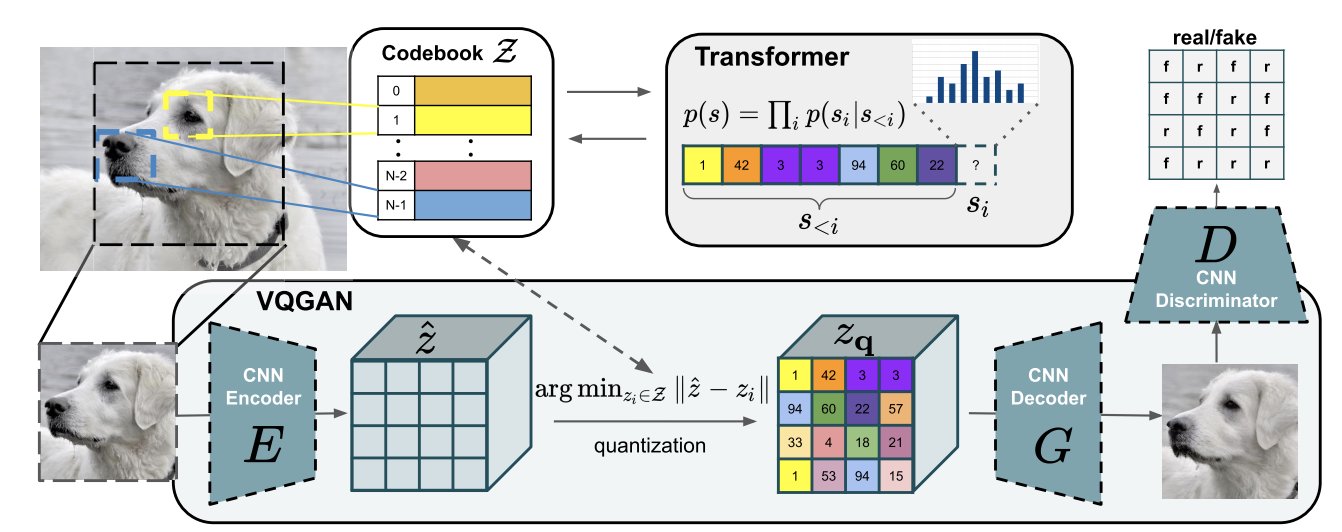 | ||
|
|
||
| --- | ||
| ### Contrastive Language-Image Pre-training (CLIP) | ||
| **Paper:** [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020)<br> | ||
|  | ||
|
|
||
| --- | ||
| ### [DALL.E-2](https://openai.com/dall-e-2/) | ||
| DALL·E 2 is a new AI system that can create realistic images and art from a description in natural language.<br> | ||
|
|
||
| **Blog:** [How DALL-E 2 Actually Works](https://www.assemblyai.com/blog/how-dall-e-2-actually-works/)<br> | ||
| "a bowl of soup that is a portal to another dimension as digital art".<br> | ||
|  | ||
|
|
||
| **Paper:** [Hierarchical Text-Conditional Image Generation with CLIP Latents](https://arxiv.org/abs/2204.06125)<br> | ||
| 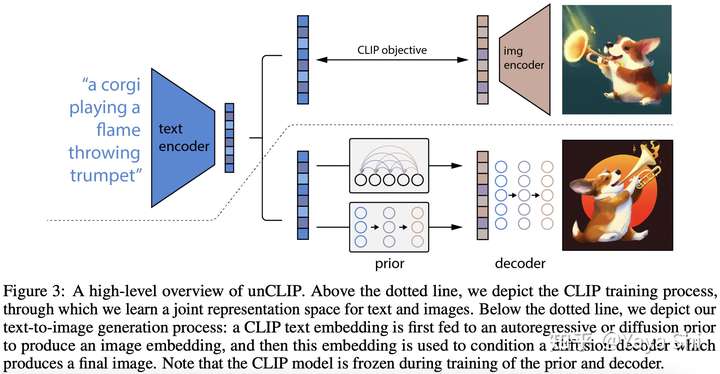 | ||
|
|
||
| --- | ||
| ### [LAION-5B Dataset](https://laion.ai/blog/laion-5b/) | ||
| 5.85 billion CLIP-filtered image-text pairs<br> | ||
| **Paper:** [LAION-5B: An open large-scale dataset for training next generation image-text models](https://arxiv.org/abs/2210.08402)<br> | ||
| 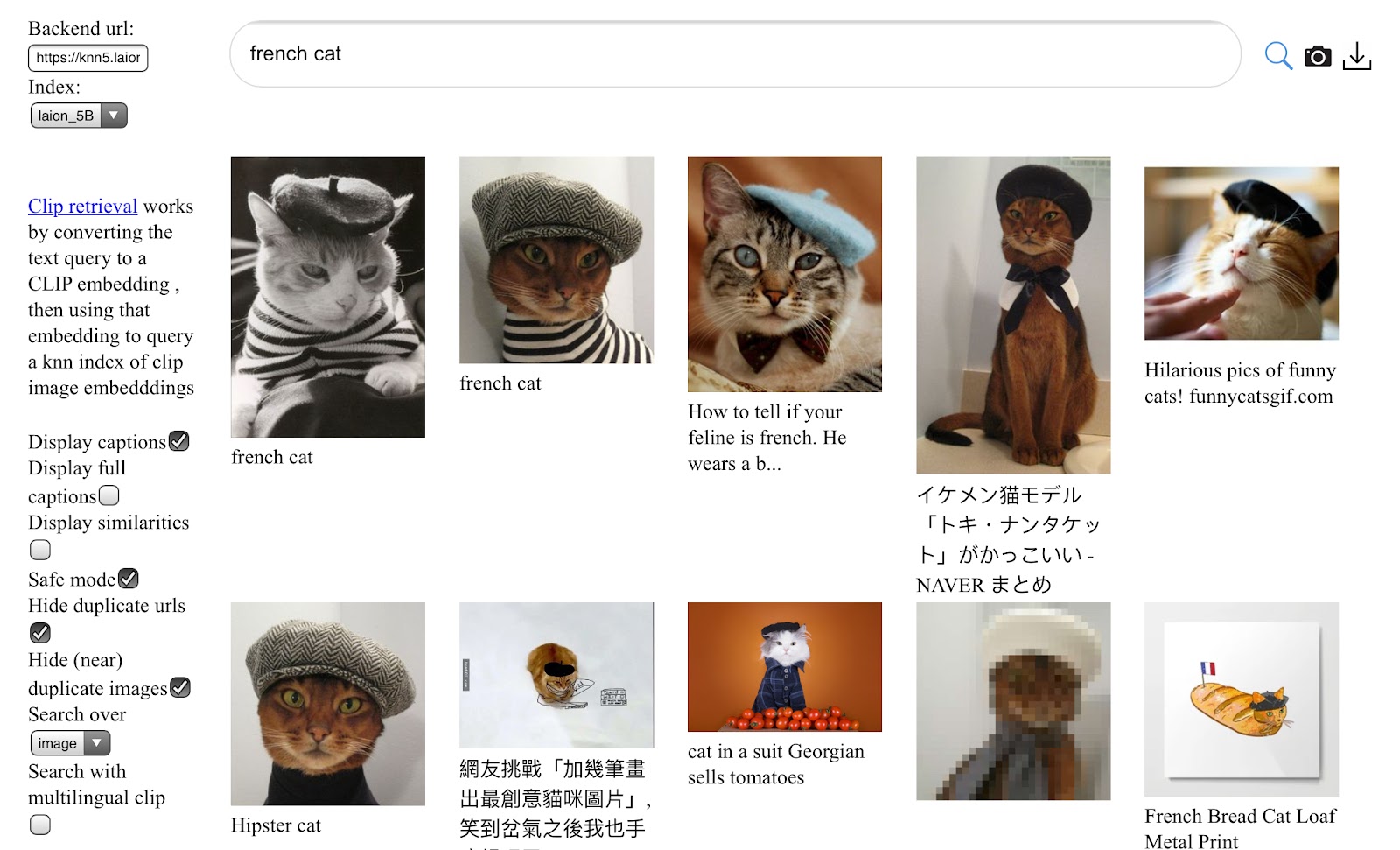 | ||
|
|
||
| --- | ||
| ### [DALL.E-3](https://openai.com/dall-e-3) | ||
|  | ||
|
|
||
| **Paper:** [Improving Image Generation with Better Captions](https://cdn.openai.com/papers/dall-e-3.pdf)<br> | ||
|
|
||
| **Blog:** [DALL-E 2 vs DALL-E 3 Everything you Need to Know](https://www.cloudbooklet.com/dall-e-2-vs-dall-e-3/)<br> | ||
|
|
||
| **Dataset Recaptioning**<br> | ||
|  | ||
|
|
||
| --- | ||
| ### Stable Diffusion | ||
| **Paper:** [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752)<br> | ||
| 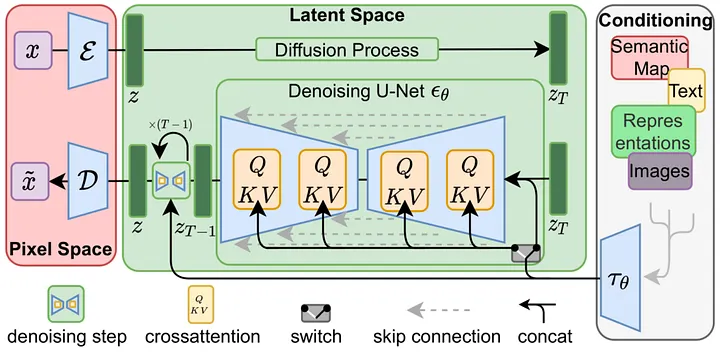 | ||
| **Blog:** [Stable Diffusion: Best Open Source Version of DALL·E 2](https://towardsdatascience.com/stable-diffusion-best-open-source-version-of-dall-e-2-ebcdf1cb64bc)<br> | ||
|  | ||
| **Code:** [Stable Diffusion](https://github.com/CompVis/stable-diffusion) | ||
|  | ||
|  | ||
|
|
||
| **Demo:** [Stable Diffusion Online (SDXL)](https://stablediffusionweb.com/)<br> | ||
| Stable Diffusion XL is a latent text-to-image diffusion model capable of generating photo-realistic images given any text input, cultivates autonomous freedom to produce incredible imagery, empowers billions of people to create stunning art within seconds. | ||
|
|
||
| --- | ||
| ### [Imagen](https://imagen.research.google/) | ||
| **Paper:** [Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding](https://arxiv.org/abs/2205.11487)<br> | ||
| **Blog:** [How Imagen Actually Works](https://www.assemblyai.com/blog/how-imagen-actually-works/)<br> | ||
|  | ||
|  | ||
| The text encoder in Imagen is the encoder network of T5 (Text-to-Text Transfer Transformer) | ||
|  | ||
|
|
||
| --- | ||
| ### Diffusion Models | ||
| **Blog:** [Introduction to Diffusion Models for Machine Learning](https://www.assemblyai.com/blog/diffusion-models-for-machine-learning-introduction/)<br> | ||
|
|
||
| Diffusion Models are a method of creating data that is similar to a set of training data. <br> | ||
| They train by destroying the training data through the addition of noise, and then learning to recover the data by reversing this noising process. Given an input image, the Diffusion Model will iteratively corrupt the image with Gaussian noise in a series of timesteps, ultimately leaving pure Gaussian noise, or "TV static". | ||
|  | ||
| The Diffusion Model will then work backwards, learning how to isolate and remove the noise at each timestep, undoing the destruction process that just occurred.<br> | ||
| Once trained, the model can then be "split in half", and we can start from randomly sampled Gaussian noise which we use the Diffusion Model to gradually denoise in order to generate an image. | ||
|  | ||
|
|
||
| --- | ||
| ### SDXL | ||
| **Paper:** [SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis](https://arxiv.org/abs/2307.01952)<br> | ||
| **Code:** [Generative Models by Stability AI](https://github.com/stability-ai/generative-models)<br> | ||
|  | ||
|  | ||
|
|
||
| **Huggingface:** [stable-diffusion-xl-base-1.0](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0)<br> | ||
|  | ||
| SDXL consists of an ensemble of experts pipeline for latent diffusion: In a first step, the base model is used to generate (noisy) latents, which are then further processed with a refinement model (available here: https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/) specialized for the final denoising steps. Note that the base model can be used as a standalone module.<br> | ||
|
|
||
| **Kaggle:** [https://www.kaggle.com/rkuo2000/stable-diffusion-xl](https://www.kaggle.com/rkuo2000/stable-diffusion-xl/)<br> | ||
|
|
||
| --- | ||
| ### Turn-A-Video | ||
| **Paper:** [Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation](https://arxiv.org/abs/2212.11565)<br> | ||
| **Code:** [https://github.com/showlab/Tune-A-Video](https://github.com/showlab/Tune-A-Video)<br> | ||
| <p align="center"> | ||
| <img src="https://tuneavideo.github.io/assets/teaser.gif" width="1080px"/> | ||
| <br> | ||
| <em>Given a video-text pair as input, our method, Tune-A-Video, fine-tunes a pre-trained text-to-image diffusion model for text-to-video generation.</em> | ||
| </p> | ||
|
|
||
| --- | ||
| ### Open-VCLIP | ||
| **Paper:** [Open-VCLIP: Transforming CLIP to an Open-vocabulary Video Model via Interpolated Weight Optimization](https://arxiv.org/abs/2302.00624)<br> | ||
| **Paper:** [Building an Open-Vocabulary Video CLIP Model with Better Architectures, Optimization and Data](https://arxiv.org/abs/2310.05010)<br> | ||
| **Code:** [https://github.com/wengzejia1/Open-VCLIP/](https://github.com/wengzejia1/Open-VCLIP/)<br> | ||
|  | ||
|
|
||
| --- | ||
| ## Text-to-Motion | ||
|
|
||
| ### TMR | ||
| **Paper:** [TMR: Text-to-Motion Retrieval Using Contrastive 3D Human Motion Synthesis](https://arxiv.org/abs/2305.00976)<br> | ||
| **Code:** [https://github.com/Mathux/TMR](https://github.com/Mathux/TMR)<br> | ||
|
|
||
| --- | ||
| ### Text-to-Motion Retrieval | ||
| **Paper:** [Text-to-Motion Retrieval: Towards Joint Understanding of Human Motion Data and Natural Language](https://arxiv.org/abs/2305.15842)<br> | ||
| **Code:** [https://github.com/mesnico/text-to-motion-retrieval](https://github.com/mesnico/text-to-motion-retrieval)<br> | ||
| `A person walks in a counterclockwise circle`<br> | ||
|  | ||
| `A person is kneeling down on all four legs and begins to crawl`<br> | ||
|  | ||
|
|
||
| --- | ||
| ### MotionDirector | ||
| **Paper:** [MotionDirector: Motion Customization of Text-to-Video Diffusion Models](https://arxiv.org/abs/2310.08465)<br> | ||
|
|
||
| --- | ||
| ### [GPT4Motion](https://gpt4motion.github.io/) | ||
| **Paper:** [GPT4Motion: Scripting Physical Motions in Text-to-Video Generation via Blender-Oriented GPT Planning](https://arxiv.org/abs/2311.12631)<br> | ||
| <video width="320" height="240" controls><src="https://gpt4motion.github.io/static/24videos/1.0_1.0_A%20basketball%20spins%20out%20of%20the%20air%20and%20falls.mp4" type="video/mp4">GPT4Motion BasketBall</video> | ||
|
|
||
| --- | ||
| ### [Awesome Video Diffusion Models](https://github.com/ChenHsing/Awesome-Video-Diffusion-Models) | ||
|
|
||
| ### StyleCrafter | ||
| **Paper:** [StyleCrafter: Enhancing Stylized Text-to-Video Generation with Style Adapter](https://arxiv.org/abs/2312.00330)<br> | ||
| **Code:** [https://github.com/GongyeLiu/StyleCrafter](https://github.com/GongyeLiu/StyleCrafter)<br> | ||
|  | ||
|
|
||
| --- | ||
| ### Stable Diffusion Video | ||
| **Paper:** [Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets](https://arxiv.org/abs/2311.15127)<br> | ||
| **Code:** [https://github.com/nateraw/stable-diffusion-videos](https://github.com/nateraw/stable-diffusion-videos)<br> | ||
|  | ||
|
|
||
| --- | ||
| ### AnimateDiff | ||
| **Paper:** [AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning](https://arxiv.org/abs/2307.04725)<br> | ||
| **Paper:** [SparseCtrl: Adding Sparse Controls to Text-to-Video Diffusion Models](https://arxiv.org/abs/2311.16933)<br> | ||
| **Code:** [https://github.com/guoyww/AnimateDiff](https://github.com/guoyww/AnimateDiff)<br> | ||
|  | ||
|
|
||
| --- | ||
| ## Image-to-3D | ||
|
|
||
| ### [Stable Zero123](https://stability.ai/news/stable-zero123-3d-generation) | ||
| **Code:** [https://huggingface.co/stabilityai/stable-zero123](https://huggingface.co/stabilityai/stable-zero123) | ||
|  | ||
|
|
||
|
|
||
| <br> | ||
| <br> | ||
|
|
||
| *This site was last updated {{ site.time | date: "%B %d, %Y" }}.* | ||
|
|
||
|
|
Oops, something went wrong.