forked from zivong/jekyll-theme-hydure
-
Notifications
You must be signed in to change notification settings - Fork 37
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
2 changed files
with
498 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,253 @@ | ||
| --- | ||
| layout: post | ||
| title: Large Language Models | ||
| author: [Richard Kuo] | ||
| category: [Lecture] | ||
| tags: [jekyll, ai] | ||
| --- | ||
|
|
||
| Introduction to Large Language Models (LLMs), LLM in Vision, etc. | ||
|
|
||
| --- | ||
| ## History of LLM | ||
| [A Survey of Large Language Models](https://arxiv.org/abs/2303.18223)<br> | ||
| *Since the introduction of Transformer model in 2017, large language models (LLMs) have evolved significantly.*<br> | ||
| *ChatGPT saw 1.6B visits in May 2023.*<br> | ||
| *Meta also released three versions of LLaMA-2 (7B, 13B, 70B) free for commercial use in July.*<br> | ||
|
|
||
| --- | ||
| ### 從解題能力來看四代語言模型的演進 | ||
| An evolution process of the four generations of language models (LM) from the perspective of task solving capacity.<br> | ||
|  | ||
|
|
||
| --- | ||
| ### 大型語言模型統計表 | ||
| 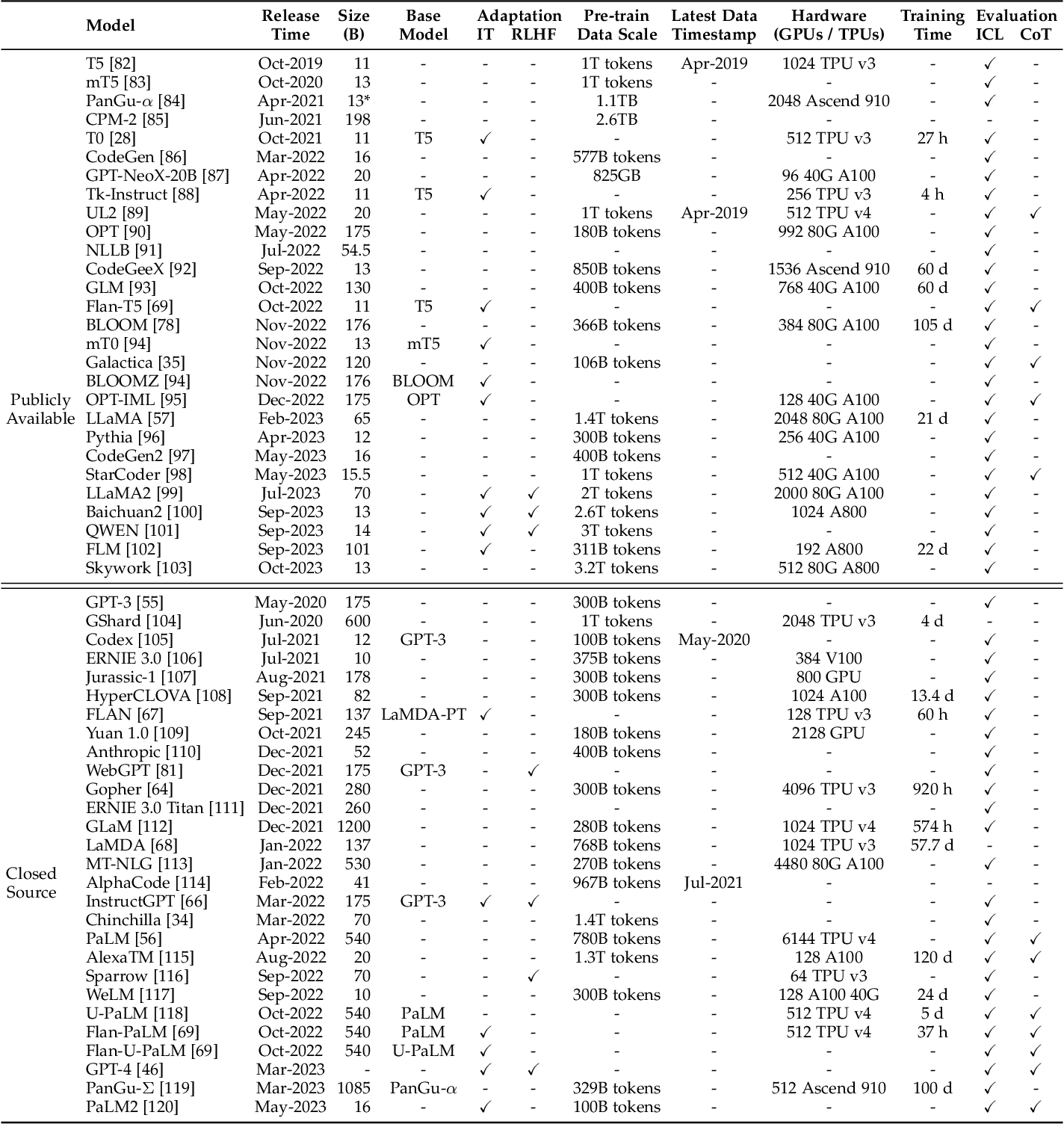 | ||
|
|
||
| --- | ||
| ### 近年大型語言模型(>10B)的時間軸 | ||
| 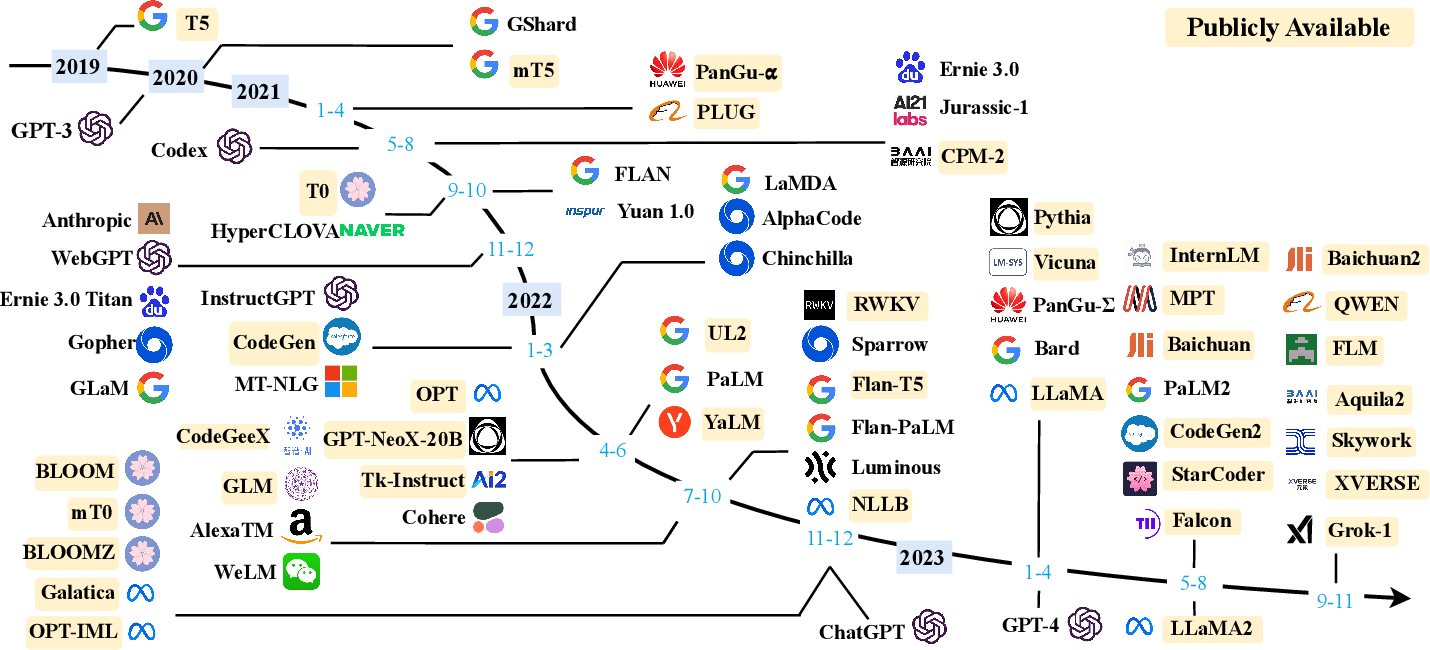 | ||
|
|
||
| --- | ||
| ### 大型語言模型之產業分類 | ||
| 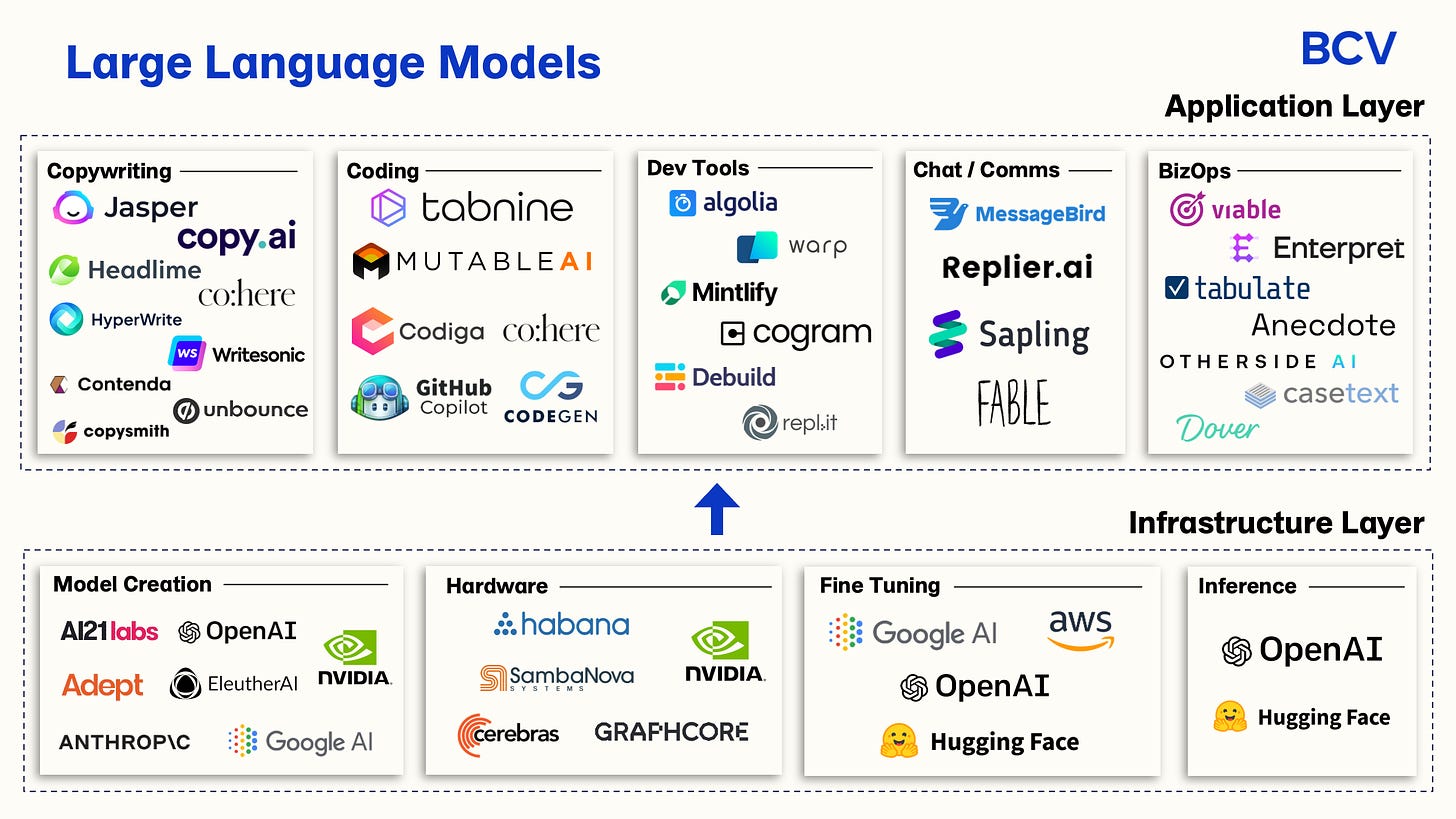 | ||
|
|
||
| --- | ||
| ### 大型語言模型之技術分類 | ||
|  | ||
|
|
||
| --- | ||
| ### 計算記憶體的成長與Transformer大小的關係 | ||
| [AI and Memory Wall](https://medium.com/riselab/ai-and-memory-wall-2cb4265cb0b8)<br> | ||
| 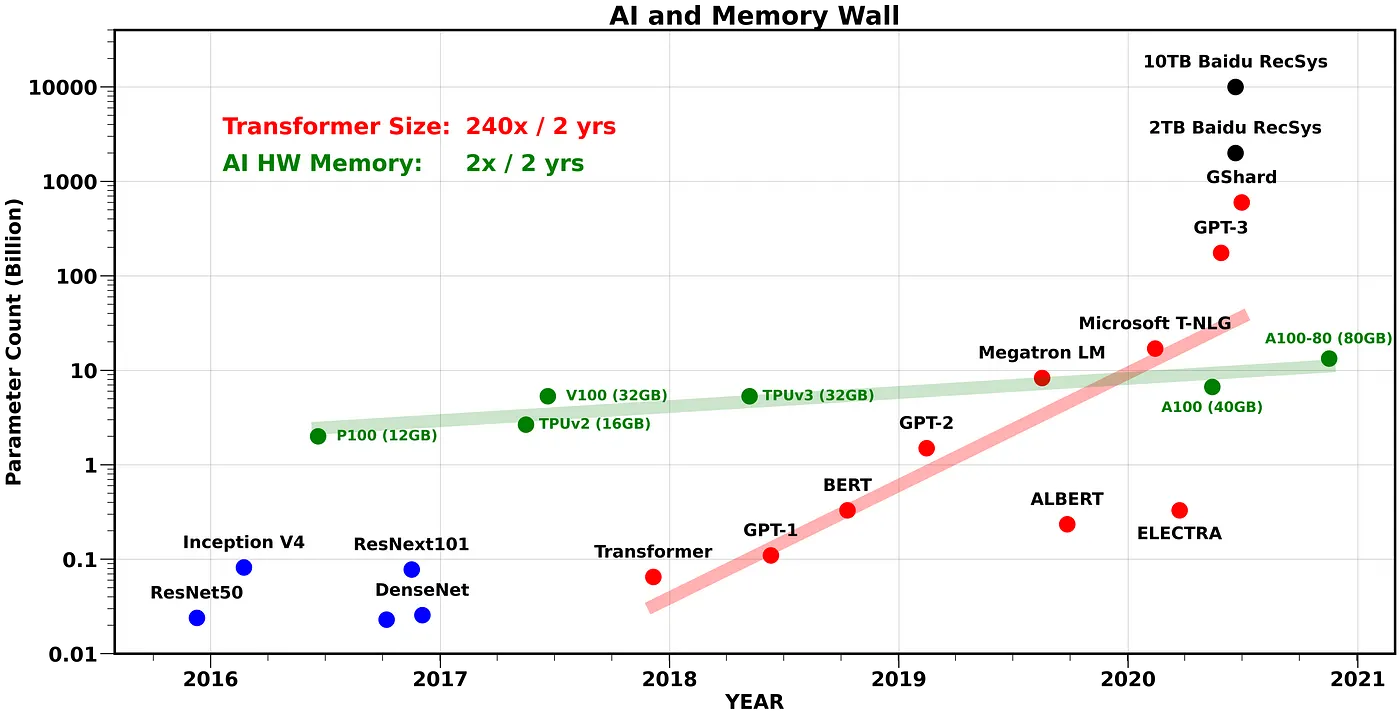 | ||
|
|
||
| --- | ||
| ### LLMops 針對生成式 AI 用例調整了 MLops 技術堆疊 | ||
|  | ||
|
|
||
| --- | ||
| ## Large Language Models | ||
|
|
||
| ### ChatGPT | ||
| [ChatGPT: Optimizing Language Models for Dialogue](https://openai.com/blog/chatgpt/)<br> | ||
| ChatGPT is fine-tuned from a model in the GPT-3.5 series, which finished training in early 2022.<br> | ||
|
|
||
|  | ||
|
|
||
| <iframe width="640" height="455" src="https://www.youtube.com/embed/e0aKI2GGZNg" title="Chat GPT (可能)是怎麼煉成的 - GPT 社會化的過程" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe> | ||
|
|
||
| --- | ||
| ### GPT4 | ||
| **Paper:** [GPT-4 Technical Report](https://arxiv.org/abs/2303.08774)<br> | ||
|  | ||
| **Paper:** [From Sparse to Dense: GPT-4 Summarization with Chain of Density Prompting](https://arxiv.org/abs/2309.04269)<br> | ||
| **Blog:** [GPT-4 Code Interpreter: The Next Big Thing in AI](https://medium.com/@aaabulkhair/gpt-4-code-interpreter-the-next-big-thing-in-ai-56bbf72d746)<br> | ||
|
|
||
| --- | ||
| ### Open LLMs | ||
| **[Open LLM leardboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)**<br> | ||
|
|
||
| --- | ||
| ### [LLaMA](https://huggingface.co/docs/transformers/main/model_doc/llama) | ||
| *It is a collection of foundation language models ranging from 7B to 65B parameters.*<br> | ||
| **Paper:** [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971)<br> | ||
| 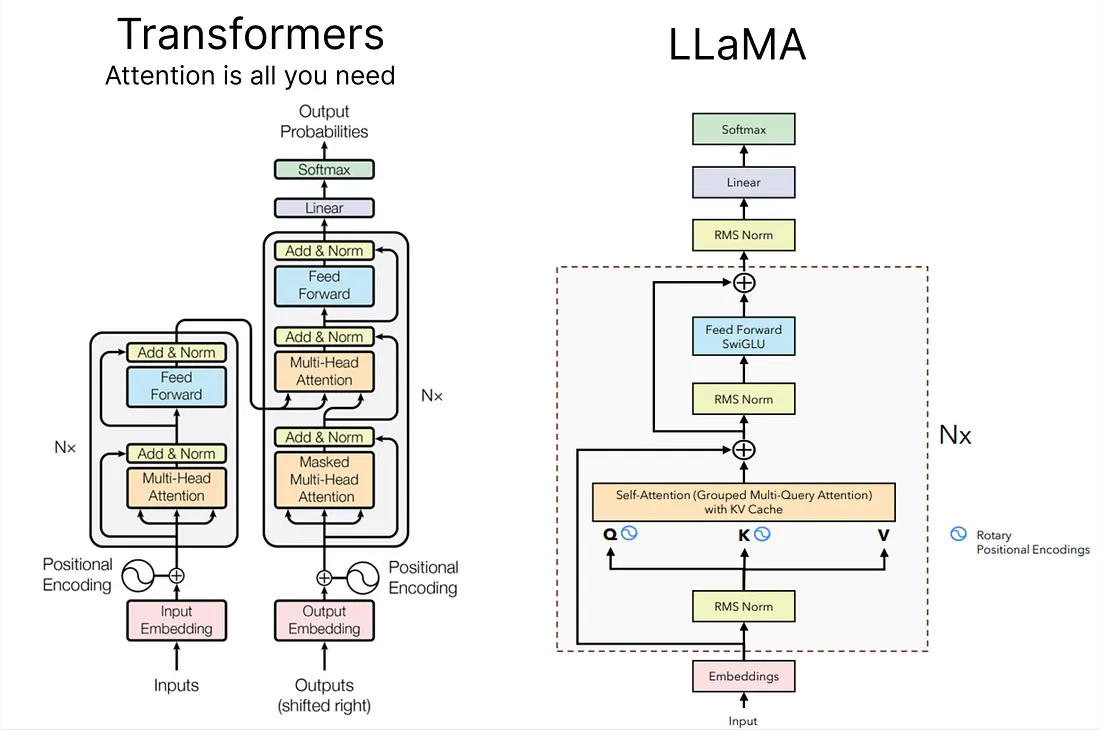 | ||
|
|
||
| --- | ||
| ### [OpenLLaMA](https://github.com/openlm-research/open_llama) | ||
| **model:** [https://huggingface.co/openlm-research/open_llama_3b_v2](https://huggingface.co/openlm-research/open_llama_3b_v2)<br> | ||
| **Kaggle:** [https://www.kaggle.com/code/rkuo2000/llm-openllama](https://www.kaggle.com/code/rkuo2000/llm-openllama)<br> | ||
|
|
||
| --- | ||
| **Blog:** [Building a Million-Parameter LLM from Scratch Using Python](https://levelup.gitconnected.com/building-a-million-parameter-llm-from-scratch-using-python-f612398f06c2)<br> | ||
| **Kaggle:** [LLM LLaMA from scratch](https://www.kaggle.com/rkuo2000/llm-llama-from-scratch/)<br> | ||
|
|
||
| --- | ||
| ### Pythia | ||
| **Paper:** [Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling](https://arxiv.org/abs/2304.01373)<br> | ||
| **Dataset:** <br> | ||
| [The Pile: An 800GB Dataset of Diverse Text for Language Modeling](https://arxiv.org/abs/2101.00027)<br> | ||
| [Datasheet for the Pile](https://arxiv.org/abs/2201.07311)<br> | ||
| **Code:** [Pythia: Interpreting Transformers Across Time and Scale](https://github.com/EleutherAI/pythia)<br> | ||
|
|
||
| --- | ||
| ### Falcon-40B | ||
| **Paper:** [The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only](https://arxiv.org/abs/2306.01116)<br> | ||
| **Dataset:** [https://huggingface.co/datasets/tiiuae/falcon-refinedweb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb)<br> | ||
| **Code:** [https://huggingface.co/tiiuae/falcon-40b](https://huggingface.co/tiiuae/falcon-40b)<br> | ||
|
|
||
| --- | ||
| ### LLaMA-2 | ||
| **Paper:** [Llama 2: Open Foundation and Fine-Tuned Chat Models](https://arxiv.org/abs/2307.09288)<br> | ||
| **Code:** [https://github.com/facebookresearch/llama](https://github.com/facebookresearch/llama)<br> | ||
| **models:** [https://huggingface.co/meta-llama](https://huggingface.co/meta-llama)<br> | ||
|
|
||
| --- | ||
| ### Orca | ||
| **Paper:** [Orca: Progressive Learning from Complex Explanation Traces of GPT-4](https://arxiv.org/abs/2306.02707)<br> | ||
|
|
||
| --- | ||
| ### Vicuna | ||
| **Paper:** [Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena](https://arxiv.org/abs/2306.05685)<br> | ||
| **model:** [https://huggingface.co/lmsys/vicuna-7b-v1.5](https://huggingface.co/lmsys/vicuna-7b-v1.5)<br> | ||
| **Code:** [https://github.com/lm-sys/FastChat](https://github.com/lm-sys/FastChat)<br> | ||
|
|
||
| --- | ||
| ### [Platypus](https://platypus-llm.github.io/) | ||
| **Paper:** [Platypus: Quick, Cheap, and Powerful Refinement of LLMs](https://arxiv.org/abs/2308.07317)<br> | ||
| **Code:** [https://github.com/arielnlee/Platypus/](https://github.com/arielnlee/Platypus/)<br> | ||
|
|
||
| --- | ||
| ### Mistral | ||
| **Paper:** [Mistral 7B](https://arxiv.org/abs/2310.06825)<br> | ||
| **Code:** [https://github.com/mistralai/mistral-src](https://github.com/mistralai/mistral-src)<br> | ||
| **Kaggle:** [https://www.kaggle.com/code/rkuo2000/llm-mistral-7b-instruct](https://www.kaggle.com/code/rkuo2000/llm-mistral-7b-instruct)<br> | ||
|  | ||
|
|
||
| --- | ||
| ### Mistral 8X7B | ||
| 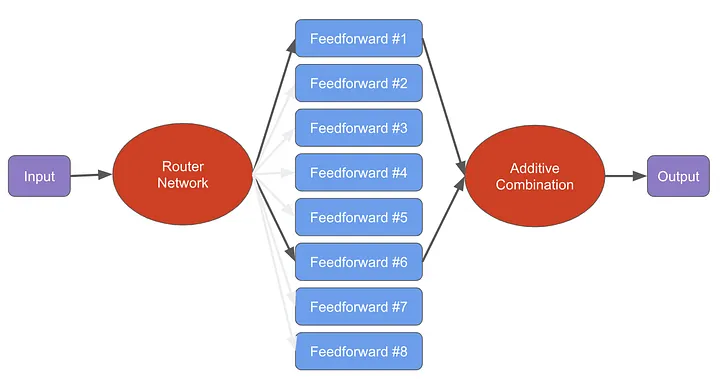 | ||
|
|
||
| --- | ||
| ### Zephyr | ||
| **Paper:** [Zephyr: Direct Distillation of LM Alignment](https://arxiv.org/abs/2310.16944)<br> | ||
| **Code:** [https://huggingface.co/HuggingFaceH4/zephyr-7b-beta](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta)<br> | ||
| **Kaggle:** [https://www.kaggle.com/code/rkuo2000/llm-zephyr-7b](https://www.kaggle.com/code/rkuo2000/llm-zephyr-7b)<br> | ||
|  | ||
|
|
||
| --- | ||
| **Blog:** [Zephyr-7B : HuggingFace’s Hyper-Optimized LLM Built on Top of Mistral 7B](https://www.unite.ai/zephyr-7b-huggingfaces-hyper-optimized-llm-built-on-top-of-mistral-7b/)<br> | ||
|  | ||
|  | ||
|  | ||
|
|
||
| --- | ||
| ### SOLAR-10.7B ~ Depth Upscaling | ||
| **Code:** [https://huggingface.co/upstage/SOLAR-10.7B-v1.0](https://huggingface.co/upstage/SOLAR-10.7B-v1.0)<br> | ||
| Depth-Upscaled SOLAR-10.7B has remarkable performance. It outperforms models with up to 30B parameters, even surpassing the recent Mixtral 8X7B model.<br> | ||
| Leveraging state-of-the-art instruction fine-tuning methods, including supervised fine-tuning (SFT) and direct preference optimization (DPO), | ||
| researchers utilized a diverse set of datasets for training. This fine-tuned model, SOLAR-10.7B-Instruct-v1.0, achieves a remarkable Model H6 score of 74.20, | ||
| boasting its effectiveness in single-turn dialogue scenarios.<br> | ||
|
|
||
| --- | ||
| ### Phi-2 (Transformer with 2.7B parameters) | ||
| **Blog:** [Phi-2: The surprising power of small language models](https://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models/)<br> | ||
| **Code:** [https://huggingface.co/microsoft/phi-2](https://huggingface.co/microsoft/phi-2)<br> | ||
| **Kaggle:** [https://www.kaggle.com/code/rkuo2000/llm-phi-2](https://www.kaggle.com/code/rkuo2000/llm-phi-2)<br> | ||
|
|
||
| --- | ||
| ### Orca 2 | ||
| **Paper:** [https://arxiv.org/abs/2311.11045](https://arxiv.org/abs/2311.11045)<br> | ||
| **model:** [Orca 2: Teaching Small Language Models How to Reason](https://huggingface.co/microsoft/Orca-2-13b)<br> | ||
| **Blog:** [Microsoft's Orca 2 LLM Outperforms Models That Are 10x Larger](https://www.infoq.com/news/2023/12/microsoft-orca-2-llm/)<br> | ||
| <p><img src="https://s4.itho.me/sites/default/files/images/1123-Orca-2-microsoft-600.png" width="50%" height="50%"></p> | ||
|
|
||
| --- | ||
| **Paper:** [Variety and Quality over Quantity: Towards Versatile Instruction Curation](https://arxiv.org/abs/2312.11508)<br> | ||
|
|
||
| --- | ||
| ### [Next-GPT](https://next-gpt.github.io/) | ||
| **Paper:** [Any-to-Any Multimodal Large Language Model](https://arxiv.org/abs/2309.05519)<br> | ||
|  | ||
|
|
||
| --- | ||
| ### MLLM FineTuning | ||
| **Paper:** [Tuning LayerNorm in Attention: Towards Efficient Multi-Modal LLM Finetuning](https://arxiv.org/abs/2312.11420)<br> | ||
|
|
||
| --- | ||
| ## LLM in Vision | ||
| **Papers:** [https://github.com/DirtyHarryLYL/LLM-in-Vision](https://github.com/DirtyHarryLYL/LLM-in-Vision)<br> | ||
|
|
||
| --- | ||
| ### VisionLLM | ||
| **Paper:** [VisionLLM: Large Language Model is also an Open-Ended Decoder for Vision-Centric Tasks](https://arxiv.org/abs/2305.11175)<br> | ||
|  | ||
|
|
||
| --- | ||
| ### MiniGPT-v2 | ||
| **Paper:** [MiniGPT-v2: Large Language Model as a Unified Interface for Vision-Language Multi-task Learning](https://arxiv.org/abs/2310.09478)<br> | ||
| **Code:** [https://github.com/Vision-CAIR/MiniGPT-4](https://github.com/Vision-CAIR/MiniGPT-4)<br> | ||
|  | ||
|
|
||
| --- | ||
| ### GPT4-V | ||
| **Paper:** [Assessing GPT4-V on Structured Reasoning Tasks](https://arxiv.org/abs/2312.11524)<br> | ||
|
|
||
| --- | ||
| ### Gemini | ||
| **Paper:** [Gemini: A Family of Highly Capable Multimodal Models](https://arxiv.org/abs/2312.11805)<br> | ||
|  | ||
|
|
||
| --- | ||
| ### [LLaVA](https://llava-vl.github.io/) | ||
| **Paper:** [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485)<br> | ||
| **Paper:** [Improved Baselines with Visual Instruction Tuning](https://arxiv.org/abs/2310.03744)<br> | ||
| **Code:** [https://github.com/haotian-liu/LLaVA](https://github.com/haotian-liu/LLaVA)<br> | ||
| **Demo:** [https://llava.hliu.cc/](https://llava.hliu.cc/) | ||
|
|
||
| --- | ||
| ### [VLFeedback and Silkie](https://vlf-silkie.github.io/) | ||
| A GPT-4V annotated preference dataset for large vision language models. | ||
| **Paper:** [Silkie: Preference Distillation for Large Visual Language Models](https://arxiv.org/abs/2312.10665)<br> | ||
| **Code:** [https://github.com/vlf-silkie/VLFeedback](https://github.com/vlf-silkie/VLFeedback)<br> | ||
|  | ||
|
|
||
| --- | ||
| ## LLM in Robotics | ||
| **Paper:** [Language-conditioned Learning for Robotic Manipulation: A Survey](https://arxiv.org/abs/2312.10807)<br> | ||
|
|
||
| --- | ||
| **Paper:** [Human Demonstrations are Generalizable Knowledge for Robots](https://arxiv.org/abs/2312.02419)<br> | ||
|
|
||
| --- | ||
| ## Advanced Topics | ||
|
|
||
| ### XoT | ||
| **Paper:** [Everything of Thoughts: Defying the Law of Penrose Triangle for Thought Generation](https://arxiv.org/abs/2311.04254)<br> | ||
| 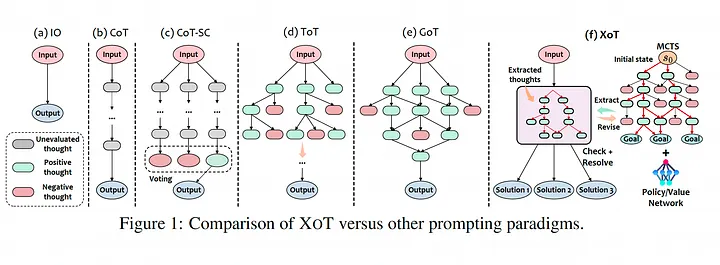 | ||
|
|
||
| --- | ||
| ### FunSearch | ||
| [DeepMind發展用LLM解困難數學問題的方法](https://www.ithome.com.tw/news/160354)<br> | ||
| 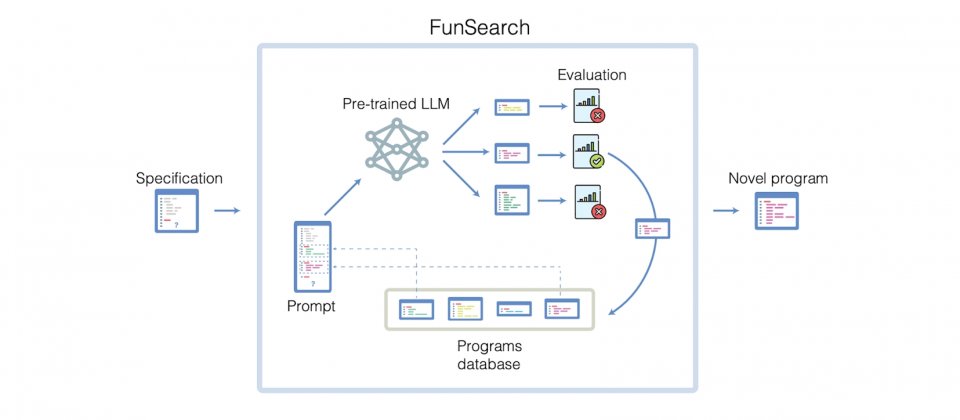 | ||
|
|
||
| --- | ||
| ### [ALTER-LLM](https://tnoinkwms.github.io/ALTER-LLM/) | ||
| **Paper:** [From Text to Motion: Grounding GPT-4 in a Humanoid Robot "Alter3"](https://arxiv.org/abs/2312.06571)<br> | ||
| <iframe width="593" height="346" src="https://www.youtube.com/embed/SAc-O5FDJ4k" title="play the metal" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe> | ||
| 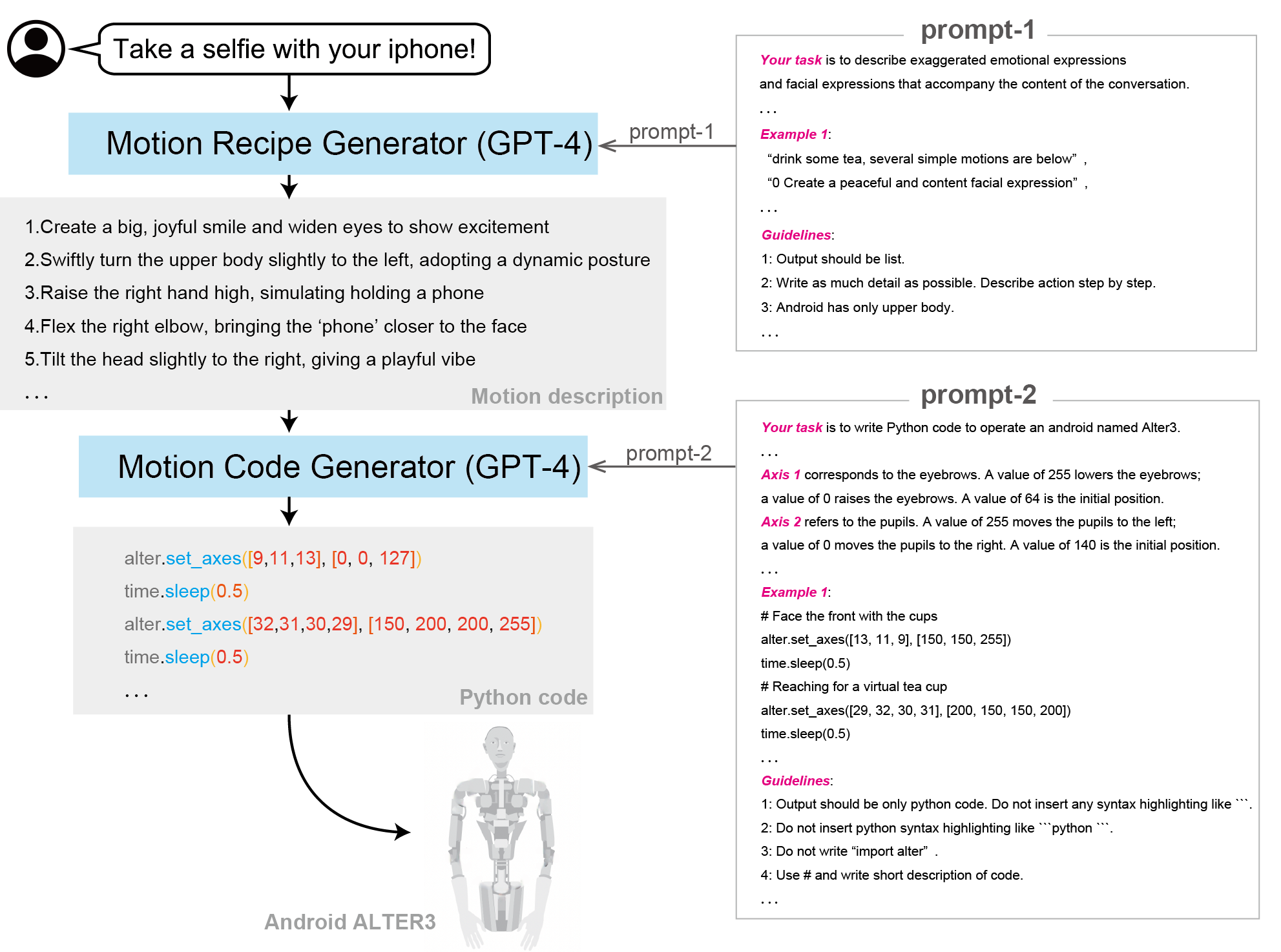 | ||
| 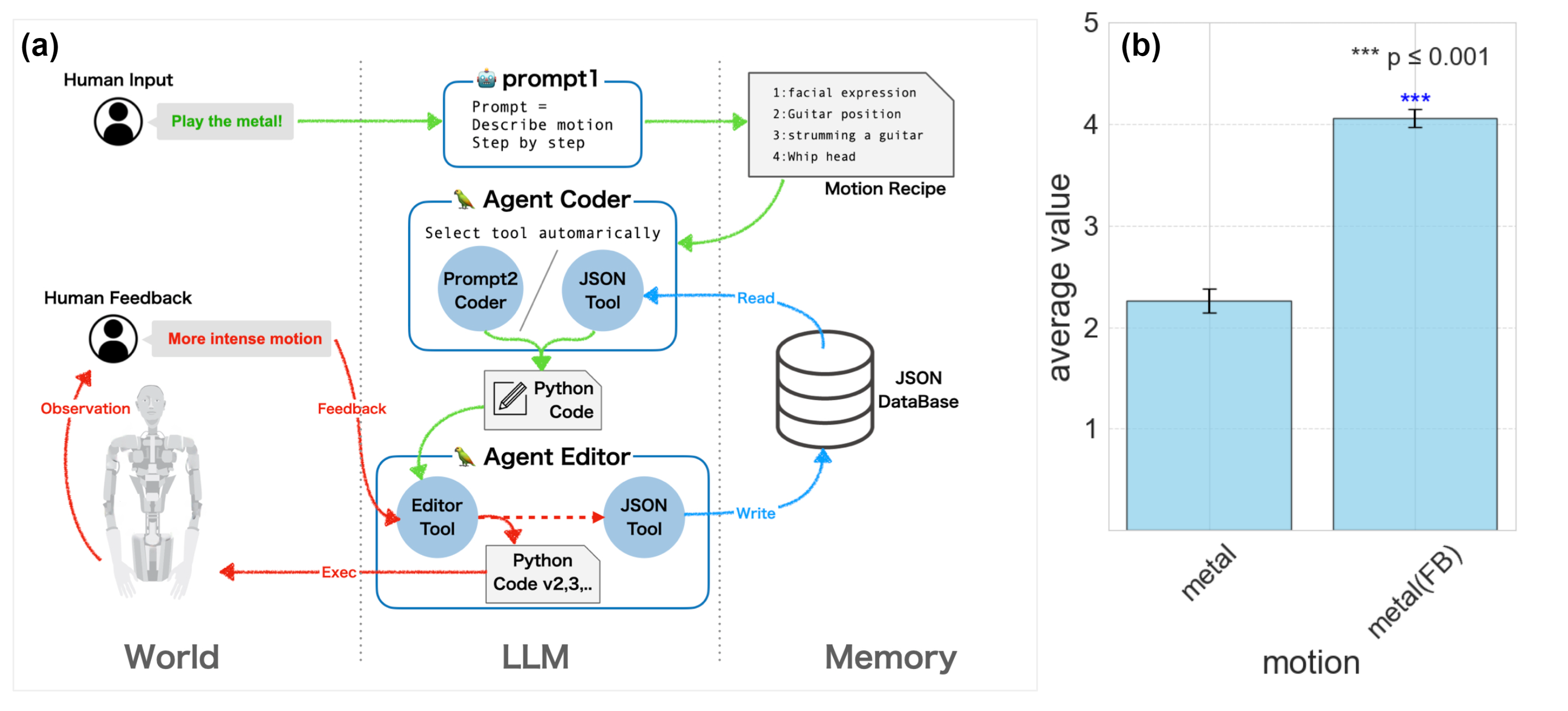 | ||
|
|
||
| --- | ||
| ### BrainGPT | ||
| **Paper:** [DeWave: Discrete EEG Waves Encoding for Brain Dynamics to Text Translation](https://arxiv.org/abs/2309.14030)<br> | ||
| **Blog:** [New Mind-Reading "BrainGPT" Turns Thoughts Into Text On Screen](https://www.iflscience.com/new-mind-reading-braingpt-turns-thoughts-into-text-on-screen-72054)<br> | ||
|  | ||
|  | ||
| <iframe width="993" height="559" src="https://www.youtube.com/embed/crJst7Yfzj4" title="UTS HAI Research - BrainGPT" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe> | ||
|
|
||
| <br> | ||
| <br> | ||
|
|
||
| *This site was last updated {{ site.time | date: "%B %d, %Y" }}.* | ||
|
|
Oops, something went wrong.