Demo is currently up at https://parkervg.github.io/discourse-referent-demo.
This directory contains the serialized model that the API uses to do inference. Additionally, the id2tok and tok2id mappings are here.
The dataset described in the paper Modeling Semantic Expectations is in this directory. It was grabbed from Ashutosh Modi's website.
All the Python scripts used for training and inference are in this directory.
POST: https://127.0.0.1:8000/get_json_prediction/
JSON body:
- text: The string to perform coreference resolution and referent prediction on.
Outputs:
JSON with the following keys. All lists will be equal in length to len(tokenized_text)
R: List[int], contains binary variables of1or0, where1indicates a prediction that the word is an entity.E: List[int], contains the entity index. Will be-1at the indices whereR == 0E_softmax_ents: List[List[str]], contains the str representation the entity to which the word at the given index refers to. Contains those entity predictions with the highest softmax score, along with the first mentioned surface form of the entity. Is an empty string ifR == 0at that index.E_softmax_scores: List[List[float]], contains the softmax probabilities for the 3 entities mentioned inE_softmax_ents. Is -1 ifR == 0at that index.R_softmaxes: List[float], contains softmax probabilities forRpredictions. Is -1 ifR == 0at that index.tokenized_text: List[str], result after tokenization by nltk.word_tokenize.next_E: int, index of the next predicted entitynext_tok: str, the surface form of the next predicted entitydetok_markers: List[int], for each token, contains1if the token should receive a leading whitespace, and0if not. Example Output:
{
"R": [
1,
0,
0,
1,
1,
0,
0,
0,
1,
0,
1,
0
],
"E": [
0,
-1,
-1,
0,
1,
-1,
-1,
-1,
2,
-1,
3,
-1
],
"E_softmax_ents": [
[
"New Entity"
],
"",
"",
[
"i (0)",
"New Entity"
],
[
"New Entity",
"i (0)"
],
"",
"",
"",
[
"New Entity",
"sister (1)",
"i (0)"
],
"",
[
"New Entity",
"sister (1)",
"i (0)"
],
""
],
"E_softmax_scores": [
[
1
],
-1,
-1,
[
0.99,
0.01
],
[
0.99,
0.01
],
-1,
-1,
-1,
[
0.98,
0.02,
0
],
-1,
[
0.5,
0.48,
0.01
],
-1
],
"R_softmaxes": [
1,
-1,
-1,
1,
0.97,
-1,
-1,
-1,
0.99,
-1,
1,
-1
],
"tokenized_text": [
"I",
"went",
"with",
"my",
"sister",
"to",
"plant",
"a",
"tree",
".",
"She",
"put"
],
"next_E": 2,
"next_tok": "it",
"detok_markers": [
1,
1,
1,
1,
1,
1,
1,
1,
1,
0,
1,
1
]
}POST: https://127.0.0.1:8000/get_example_script/
JSON body:
- script_type: str, the script type to fetch. Must match one of the directory names in (data/taclData/data/testFiles, e.g.
bath,bike,cake.
Outputs: A random script from the InScript test set with the specified genre. It will be formatted so that the next token in the text is a masked token, used in model evaluation.
Example Output:
{
"text": "A few years ago, I did some volunteer work in my local community. I like giving back to my community. One of the things we did was plant trees in the city. This was my first experience with planting trees. First I had to prepare the"
}GET: https://127.0.0.1:8000/is_up/
This endpoint is used to check the API status. Since I've deployed the API on Heroku using their free plan, the API will fall into a "sleep" state if it doesn't receive traffic within 30 minutes. It takes about a minute to startup again when it's fallen asleep. To make the user experience a bit better for the demo, the is_up endpoint is called behind the scenes everytime the webpage is loaded.
Notes here are take from the original paper, Dynamic Entity Representations in Neural Language Models.
Model should assign probabilities to DRs already explicitly introduced in preceding text fragment, but also reserve some probability mass for 'new' DRs.
In incremental model, predicate is not always available in the history h^(t) for subject NPs.
EntityNLM
- RNN, augmented with random variables for entity mentions that capture coreference
- Dynamic representations of entities
- Generative
Additional random variables and representations for entities:
- Binary random variable, indicates whether
belongs to an entity mention.
- Categorical random variable if
- Indicates number of remaining words in the mention, including current word
for the last word in a mention
- Index of the entity referred to, if
starts as
, grows monotonically with
- Vector of entity
at timestep

Before predicting the entity at timestep t, we need a new embedding for the entity, if it does not exist.
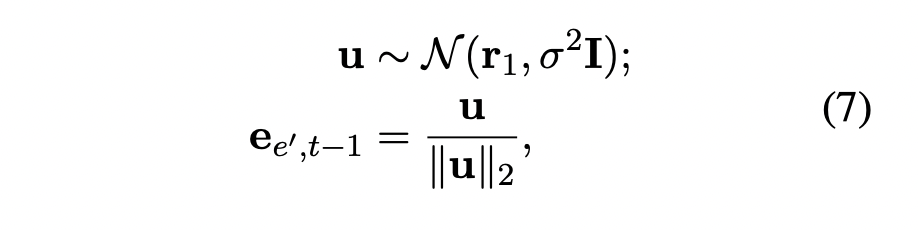
initialize_entity_embedding()