Apache Spark is an open-source, distributed computing system designed for fast big data processing. It offers a comprehensive framework capable of handling a wide range of data processing tasks, including batch processing, interactive queries, real-time streaming, machine learning, and graph processing. Spark extends the MapReduce model to efficiently use more types of computations, such as interactive queries and stream processing, and introduces an in-memory cluster computing capability, which boosts the speed of the applications that require repetitive operations on the same datasets.
- Big Data Processing: Spark excels in environments where large volumes of data need to be processed efficiently. Its distributed computing model allows it to scale out linearly with the addition of more nodes.
- Real-Time Data Processing: Apache Spark Streaming can process real-time data with high throughput and low latency, making it ideal for use cases like real-time analytics, fraud detection, and monitoring.
- Machine Learning: Spark includes a scalable machine learning library called MLlib. It simplifies the development of scalable machine learning algorithms, handling large datasets much faster than on single machines.
- Iterative Algorithms: Spark's in-memory processing capability makes it highly suitable for iterative algorithms which involve multiple passes over the same data, such as clustering and logistic regression.
- Interactive Data Analysis: Tools like Spark SQL allow for interactive querying and analysis of big data, which is a common requirement in data analytics and business intelligence applications.
- Small-Scale Data Processing:
- Scenario: Companies dealing with moderate amounts of data where the overhead of setting up a distributed computing cluster may outweigh its benefits.
- Alternative: Traditional tools and frameworks like traditionals databases or Python's Pandas.
- Low-Latency, Small-Batch Jobs:
- Scenario: Tasks that require sub-millisecond latencies and operate on small batches (e.g., microservices handling a few data points at a time).
- Alternative: Dedicated microservice frameworks.
- Non-Distributed Workloads:
- Scenario: Workloads that don't benefit from distribution because they fit comfortably within the resources of a single machine.
- Alternative: Using standalone applications or libraries designed for single-machine operations, such as Scikit-Learn for machine learning.
- Highly Specialized Data Processing:
- Scenario: Use cases that require very specific processing capabilities not natively supported by Spark, such as certain types of geospatial or biological data analysis.
- Alternative: Specialized tools tailored to these domains, like GDAL for geospatial data or Bioconductor for biological data analysis. In summary, while Apache Spark is a powerful tool for big data processing, real-time analytics, and machine learning on large datasets, it might not be the best fit for small-scale, low-latency, non-distributed, or highly specialized tasks.
Specifically, to run on a cluster, the SparkContext can connect to several types of cluster managers (either Spark’s own standalone cluster manager, Mesos, YARN or Kubernetes), which allocate resources across applications. Once connected, Spark acquires executors on nodes in the cluster, which are processes that run computations and store data for your application. Next, it sends your application code (defined by JAR or Python files passed to SparkContext) to the executors. Finally, SparkContext sends tasks to the executors to run.

Spark has several key components that work together to provide a powerful and flexible distributed computing platform. These components include:
- Spark Core: The core engine of Spark that provides the basic functionality for distributed computing, including task scheduling, memory management, and fault recovery.
- Spark SQL: A module for working with structured data using SQL and DataFrame APIs.
- Spark Streaming: A module for processing real-time streaming data.
- MLlib: A machine learning library for building and training machine learning models.
- GraphX: A library for working with graph data and performing graph computations.
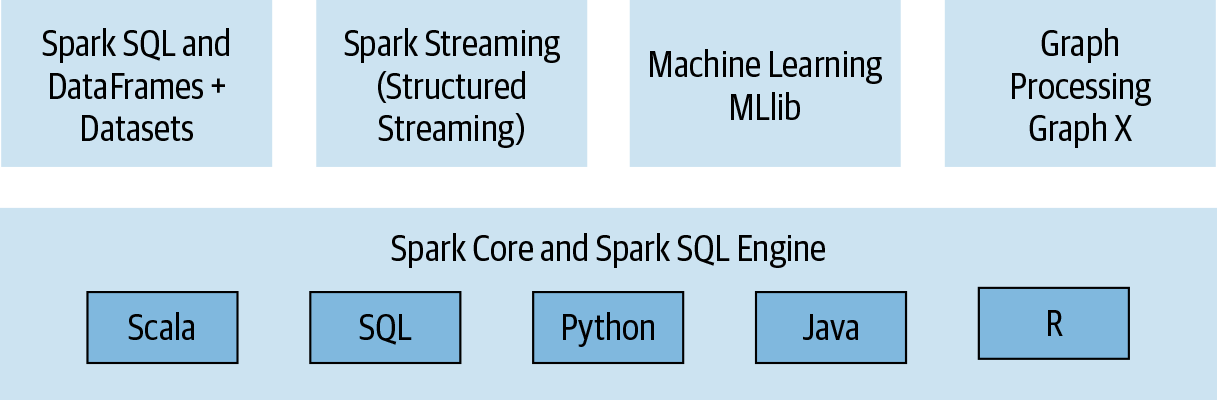
Apache Spark offers a wide range of features that make it a powerful tool for big data processing and analytics:
-
In-Memory Computing:
- Spark is designed for in-memory processing, which significantly boosts the speed of data processing tasks, particularly those that involve multiple iterations over the same dataset, such as machine learning algorithms.
-
Transformations, Actions, and Lazy Processing:
- Transformations: Operations that create a new dataset from an existing one. They're lazy, meaning Spark builds up a lineage of transformations to apply when an action is called. Examples include
map(),filter(), andreduceByKey(). - Actions: Operations that trigger the execution of the transformations to return a result to the driver program or write data to storage. Examples include
collect(),count(), andsaveAsTextFile(). - Lazy Processing: Spark uses lazy evaluation for transformations, delaying their execution until an action is called. This approach results in optimized execution plans, represented as a Directed Acyclic Graph (DAG), minimizing data shuffling and optimizing resource usage.
- Transformations: Operations that create a new dataset from an existing one. They're lazy, meaning Spark builds up a lineage of transformations to apply when an action is called. Examples include
-
Rich API, Integrations, and Resource Management:
- Rich API: Provides high-level APIs for Java, Scala, Python, and R, making it accessible to a wide range of developers. Its concise and expressive APIs allow for easy data manipulation and transformation.
- Integrations and Ecosystem: Spark seamlessly integrates with Hadoop and other big data tools, such as HDFS, HBase, and Cassandra. It supports various data formats and can be deployed in diverse environments, from standalone clusters to cloud services.
- Resource Management: Can be deployed using various resource managers, including Hadoop YARN, Apache Mesos, and Kubernetes, efficiently handling cluster resources.
-
Fault Tolerance:
- Spark ensures fault tolerance through lineage information. If a partition of data is lost, Spark can recompute it using the transformations recorded in the lineage.
By leveraging these key features, Apache Spark provides a robust and flexible platform for handling diverse big data processing and analytics workloads efficiently.
Dataset used in these examples haven been obtained from Malaga City Hall Open Data Portal.
- Inhabitants 2017
- Inhabitants 2018
- Inhabitants 2019
- Inhabitants 2020
- Inhabitants 2021
- Neighborhood
- Municipality
- Province
- Country
- Apache Spark
- Learning Spark
- Spark: The Definitive Guide by Bill Chambers and Matei Zaharia