-
-
Notifications
You must be signed in to change notification settings - Fork 12
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Kien Nguyen Tuan
committed
Oct 21, 2024
1 parent
df34939
commit f0b814d
Showing
1 changed file
with
75 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,75 @@ | ||
| # Taskflow | ||
|
|
||
| Source: | ||
| - <https://wiki.openstack.org/wiki/TaskFlow> | ||
| - <https://docs.openstack.org/taskflow/latest> | ||
|
|
||
| Table of contents: | ||
|
|
||
| - [Taskflow](#taskflow) | ||
| - [1. Design](#1-design) | ||
| - [1.1. Atoms, tasks, retries and flows](#11-atoms-tasks-retries-and-flows) | ||
| - [2. Engines](#2-engines) | ||
| - [3. Persistence](#3-persistence) | ||
| - [4. Resumption](#4-resumption) | ||
| - [5. Jobs](#5-jobs) | ||
| - [6. Conductors](#6-conductors) | ||
|
|
||
| TaskFlow is a Python library that helps to make task execution easy, consistent and reliable. | ||
|
|
||
| ## 1. Design | ||
|
|
||
| 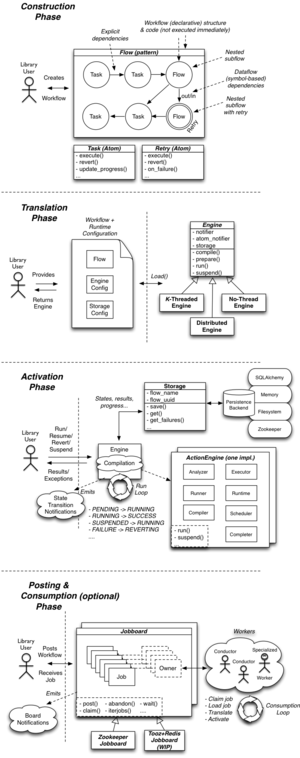 | ||
|
|
||
| ### 1.1. Atoms, tasks, retries and flows | ||
|
|
||
| - An **atom** is the smallest unit in TaskFlow which acts as the base for other classes (its naming was inspired from the similarities between this type and atoms in physical world). Atoms have a name and may have a version. An atom is expected to name desired input values (requirements) and name outputs (provided values). | ||
| - A **task** (derived from an atom) is a unit of work that can have an execute & rollback sequence associated with it (they are *nearly* analogous to functions). Your task objects should all derive from Task which defines what a task must provide in terms of properties and methods. | ||
|
|
||
| 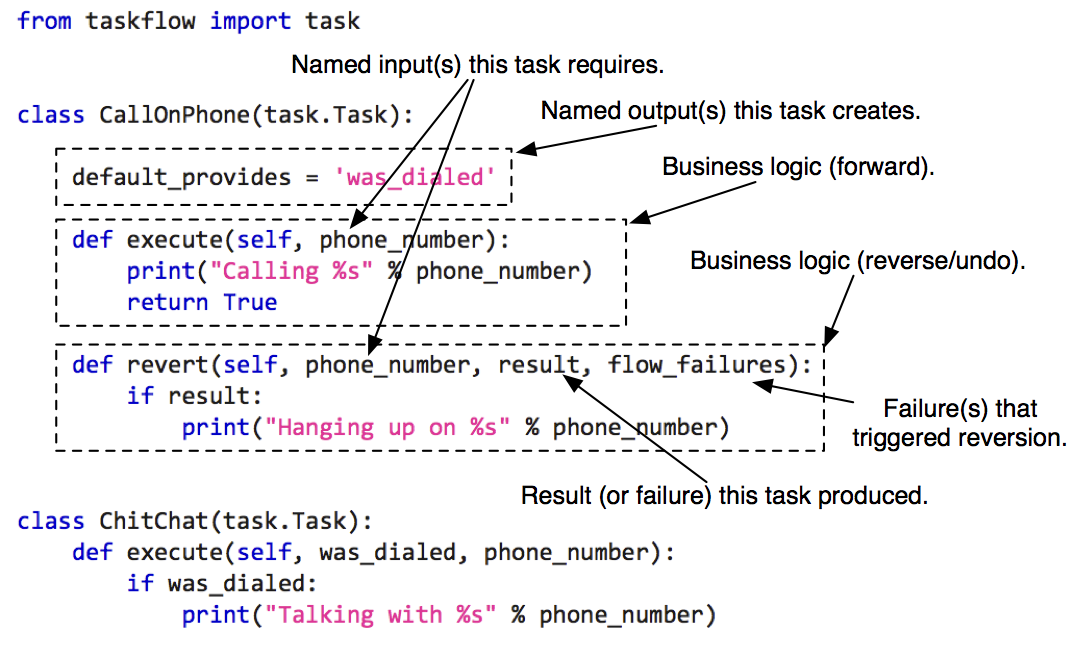 | ||
|
|
||
| - A **retry** (derived from an atom) is a special unit of work that handles errors, controls flow execution and can (for example) retry other atoms with other parameters if needed. When an associated atom fails, these retry units are *consulted* to determine what the resolution *strategy* should be. The goal is that with this consultation the retry atom will suggest a *strategy* for getting around the failure. | ||
| - A **flow** is a structure that defines relationships between tasks. You can add tasks and other flows (as subflows) to the flow, and the flow provides a way to implicitly or explicitly define how they are interdependent. Exact structure of the relationships is defined by concrete implementation, while this class defines common interface and adds human-readable (not necessary unique) name. | ||
| - Patterns: how you structure your work to be done (via tasks and flows) in a programmatic manner. | ||
|
|
||
| | Pattern | Description | Constraints | Use-case | Benefits | Drawbacks | | ||
| | --------- | ---------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------- | | ||
| | Linear | Runs a list of tasks/flows, one after the other in a serial manner | Predecessor tasks's outputs must satisfy successive task's inputs. | This pattern is useful for structing tasks/flows that are fairly simple, where task/flow follows a previous one | Simple | Serial, no potential for concurrency | | ||
| | Unordered | Runs a set of tasks/flows, in any order. | This pattern is useful for tasks/flows that are fairly simple and are typically embarrassingly parallel. | Disallows intertasks dependencies. | Simple. Inherently concurrent. | No dependencies allowed. Tracking and debugging harder due to lack of reliable ordering. | | ||
| | Graph | Runs a graph (set of nodes and edges between those nodes) composed of tasks/flows in dependency driven ordering. | Dependency driven, no cycles. A task's dependents are guaranteed to be satisfied before the task will run. | This pattern allows for a very high level of potential concurrency and is useful for tasks which can be arranged in a directed acyclic graph (without cycles). Each independent task (or independent subgraph) in the graph could be run in parallel when its dependencies have been satisfied. | Allows for complex task ordering. Can be automatically made concurrent by running disjoint tasks/flows in parallel. | Complex. Can not support cycles. Tracking and debugging harder due to graph dependency traversal. | | ||
|
|
||
| ## 2. Engines | ||
|
|
||
| - Engines are what really runs your atoms. | ||
| - An **engine** takes a flow structure (described by patterns) and uses it to decide which atom to run and when. Their purpose is to reliably execute your desired workflows and handle the control & execution flow around making this possible. This makes it so that code using taskflow only has to worry about forming the workflow, and not worry about execution, reverting, or how to resume (and more!). | ||
| - Types: | ||
| - Serial: Runs all tasks on a single thread – the same thread run() is called from. | ||
| - Parallel: A parallel engine schedules tasks onto different threads/processes to allow for running non-dependent tasks simultaneously. | ||
| - Workers: separate processes dedicated for certain atoms execution, possibly running on other machines, connected via amqp (or other supported kombu transports). | ||
| - Engines provide a way to receive **notification** on task and flow state transitions (see states), which is useful for monitoring, logging, metrics, debugging and plenty of other tasks. | ||
|
|
||
| ## 3. Persistence | ||
|
|
||
| - In order to be able to receive inputs and create outputs from atoms (or other engine processes) in a fault-tolerant way, there is a need to be able to place what atoms output in some kind of location where it can be re-used by other atoms (or used for other purposes). To accommodate this type of usage TaskFlow provides an abstraction (provided by pluggable stevedore backends) that is similar in concept to a running programs memory. | ||
|
|
||
| ## 4. Resumption | ||
|
|
||
| - If a flow is started, but is interrupted before it finishes (perhaps the controlling process was killed) the flow may be safely resumed at its last checkpoint. This allows for safe and easy crash recovery for services. TaskFlow offers different persistence strategies for the checkpoint log, letting you as an application developer pick and choose to fit your application's usage and desired capabilities. | ||
|
|
||
| ## 5. Jobs | ||
|
|
||
| - Jobs and jobboards are a novel concept that TaskFlow provides to allow for automatic ownership transfer of workflows between capable owners (those owners usually then use engines to complete the workflow). They provide the necessary semantics to be able to atomically transfer a job from a producer to a consumer in a reliable and fault tolerant manner. They are modeled off the concept used to post and acquire work in the physical world (typically a job listing in a newspaper or online website serves a similar role). | ||
| - Jobboard types: | ||
| - Zookeeper. | ||
| - Redis. | ||
| - Etcd. | ||
|
|
||
| ## 6. Conductors | ||
|
|
||
| - Conductors provide a mechanism that unifies the various concepts under a single easy to use (as plug-and-play as we can make it) construct. | ||
| - They are responsible for the following: | ||
| - Interacting with jobboards (examining and claiming jobs). | ||
| - Creating engines from the claimed jobs (using factories to reconstruct the contained tasks and flows to be executed). | ||
| - Dispatching the engine using the provided persistence layer and engine configuration. | ||
| - Completing or abandoning the claimed job (depending on dispatching and execution outcome). | ||
| - Rinse and repeat. |