This is a fork of ultralytics' YOLOv3 repo, used for a project on pedestrian detection.
| Model | size (pixels) |
mAPval 0.5:0.95 |
mAPtest 0.5:0.95 |
mAPval 0.5 |
Speed V100 (ms) |
params (M) |
FLOPS 640 (B) |
|
|---|---|---|---|---|---|---|---|---|
| YOLOv3-tiny | 640 | 17.6 | 17.6 | 34.8 | 1.2 | 8.8 | 13.2 | |
| YOLOv3 | 640 | 43.3 | 43.3 | 63.0 | 4.1 | 61.9 | 156.3 | |
| YOLOv3-SPP | 640 | 44.3 | 44.3 | 64.6 | 4.1 | 63.0 | 157.1 | |
| YOLOv5l | 640 | 48.2 | 48.2 | 66.9 | 3.7 | 47.0 | 115.4 |
Table Notes (click to expand)
- APtest denotes COCO test-dev2017 server results, all other AP results denote val2017 accuracy.
- AP values are for single-model single-scale unless otherwise noted. Reproduce mAP by
python test.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65 - SpeedGPU averaged over 5000 COCO val2017 images using a GCP n1-standard-16 V100 instance, and includes FP16 inference, postprocessing and NMS. Reproduce speed by
python test.py --data coco.yaml --img 640 --conf 0.25 --iou 0.45 - All checkpoints are trained to 300 epochs with default settings and hyperparameters (no autoaugmentation).
pip install PyYAML==5.4.1 wandb
detect.py runs inference on a variety of sources, downloading models automatically from the latest YOLOv3 release and saving results to runs/detect.
$ python detect.py --source 0 # webcam
file.jpg # image
file.mp4 # video
path/ # directory
path/*.jpg # glob
'https://youtu.be/NUsoVlDFqZg' # YouTube video
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP streamTo run inference on example images in data/images:
$ python detect.py --source data/images --weights yolov3.pt --conf 0.25
model = torch.hub.load('ultralytics/yolov3', 'yolov3') # or 'yolov3_spp', 'yolov3_tiny'
Run get_citypersons.sh
Then, run make_citypersons_labels.py to generate label .txt files
img = 'https://ultralytics.com/images/zidane.jpg'
{kind=link}
results = model(img) results.print() # or .show(), .save()
## Training
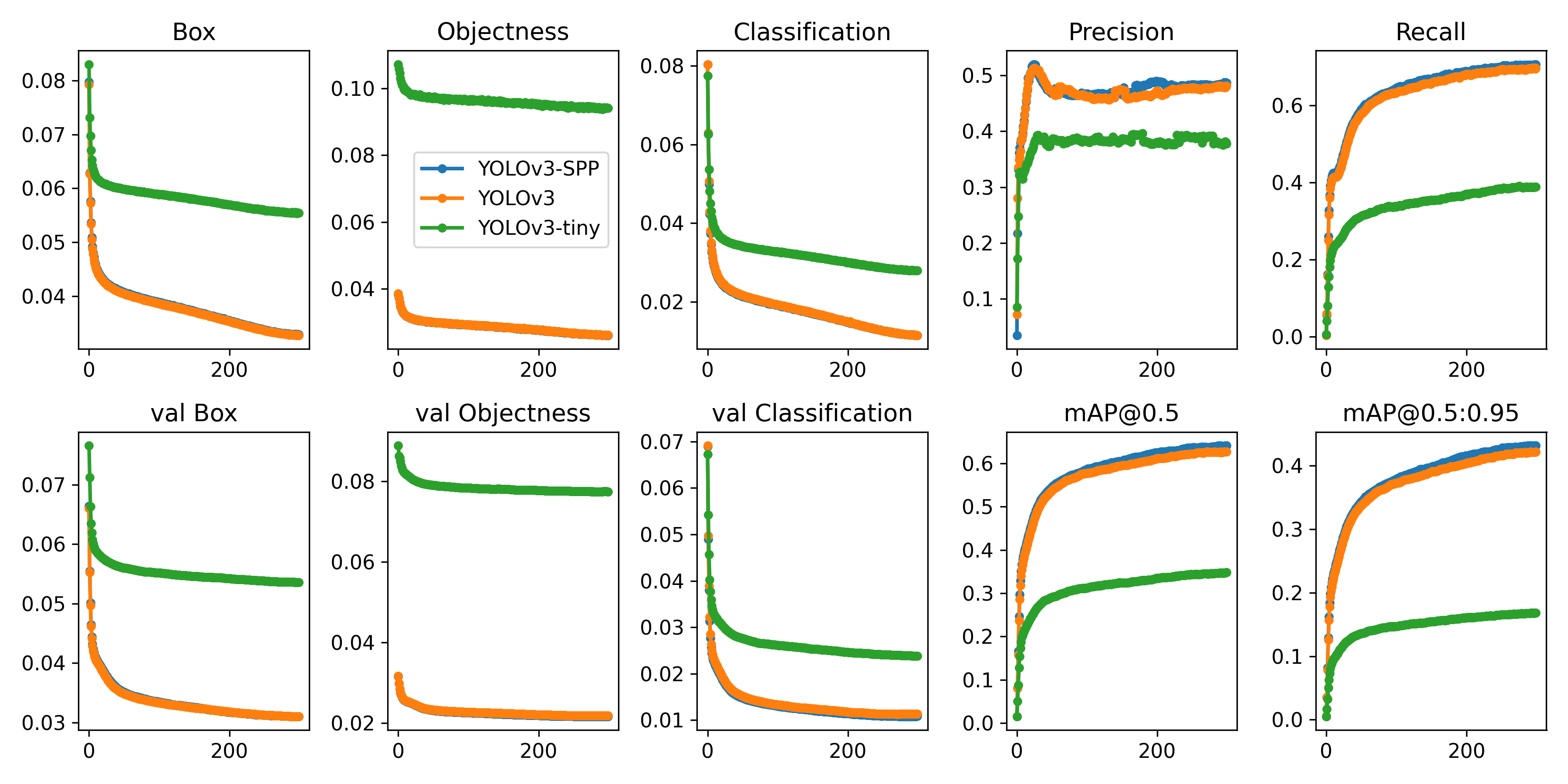
Run commands below to reproduce results on [COCO](https://github.com/ultralytics/yolov3/blob/master/data/scripts/get_coco.sh) dataset (dataset auto-downloads on first use). Training times for YOLOv3/YOLOv3-SPP/YOLOv3-tiny are 6/6/2 days on a single V100 (multi-GPU times faster). Use the largest `--batch-size` your GPU allows (batch sizes shown for 16 GB devices).
```bash
$ python train.py --data coco.yaml --cfg yolov3.yaml --weights '' --batch-size 24
yolov3-spp.yaml 24
yolov3-tiny.yaml 64
-
Create test set
-
Run baseline model
-
Run experiments