FlatBuffers Explained
FlatBuffers provide a custom schema language which allows us to specialise the types and the structure of the data we intend to store and read. For an in-depth understanding of schema definition language please visit FlatBuffers official website https://google.github.io/flatbuffers/flatbuffers_guide_writing_schema.html
For the sake of this article I would like to start with a very simple schema:
table Person {
name: string;
age : int;
}
root_type Person;
This schema enable us to do following in Swift:
let person = Person(name: "maxim", age: 34)
person.toByteArray
// [12, 0, 0, 0, 8, 0, 12, 0, 4, 0, 8, 0, 8, 0, 0, 0, 8, 0, 0, 0, 34, 0, 0, 0, 5, 0, 0, 0, 109, 97, 120, 105, 109]The result of person.toByteArray method call is a 32 byte long array that you can see on the next line. This byte array can be stored to disk or send to another machine. It is basically an equivalent to following JSON object.
{"name":"maxim","age":34}While JSON is designed to be human readable, FlatBuffers is optimised to be machine readable. To get the name of the person from JSON we would have to write something like:
let person = try? NSJSONSerialization.JSONObjectWithData(jsonData, options: NSJSONReadingOptions.MutableContainers)
let age = (person as? NSDictionary)["age"] as? NSNumberThe method call NSJSONSerialization.JSONObjectWithData hides a lot of complexity for us. But in reality, it has to tokenise the string, reproduce the tree structure which the JSON text represents and than transform it into instances of NSDictionary, NSArray, NSString or NSNumber. On the second line we have to do a lots of casting because there is no schema and there is no way to know which of the four NS classes will be returned.
FlatBuffersSwift can achieve the same goal with following two lines:
let person = Person.LazyAccess(data: fbData)
let age = person.ageThe first line will not parse anything, it will just create and return an instance of Person.LazyAccess class. The second line will return an Int32 because we defined the age property to be an int and ints are 32 bits long in FlatBuffers. Will there be some parsing involved on the second line? Nope!
To understand how FlatBuffers achieve this kind of fast data access we should analyse the byte array:
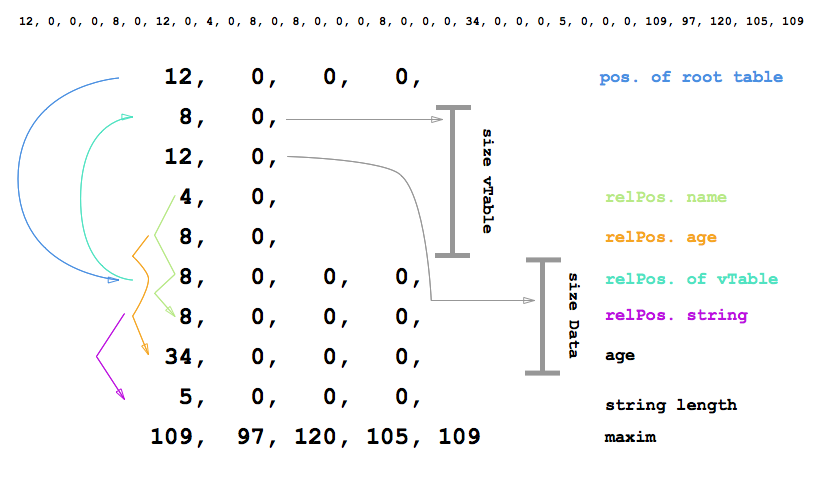
The image above might be very confusing with all the numbers and arrows, but don't worry I will walk you through one arrow at a time.
First of all, let's see where all the numbers come from. The first line in smaller font is the complete 32 UInt8 array which we already saw in the first Swift snippet. Underneath I am breaking it down into logical chunks.
-
On the 1st row we see 4 bytes which represent the position of the root table. Meaning that we have to hope 12 bytes ahead(to the right) to get to the root of the Person table. This offset is a Int32 number which results in 4 bytes
12, 0, 0, 0. Important to notice is that FlatBuffers define all numbers to be little endian, despite the architecture you are running on. For those of us who forgot about differences between little and big endian. A number 12 typed as Int32 would result in0, 0, 0, 12on a big endian architecture and12, 0, 0, 0on little endian architecture. This technicality bares good and bad news. Bad news - FlatBuffers will be slower on a big endian machine. Good news - most of the machines nowadays are little endian. -
Lets hop 12 byte and land on the 6th row. On 6th row we find the root of the table which is a Int32 telling us where to find the vTable(will explain in a minute). In our particular case it is 8 bytes behind (to the left), starting at second row.
-
2nd row is an Int16 which stores the size of the vTable (8 bytes).
-
3rd row is also an Int16 and it stores the size of the data stored in the table itself including the root of the table which tells us where to find the vTable. In our case the size is 12 bytes.
-
4th row is an Int16 which stores where to find the first property of the table, relative to the table root. So starting from table root hop 4 bytes ahead.
-
5th row is an Int16 which stores where to find the second property of the table, relative to the table root.
-
6th row is the root of the table which we already discussed.
-
7th row is an Int32 it is the place where 4th row sad we will find the first property of the table. However instead of finding the name we found another indirection. It tells us that we can find the string 8 bytes ahead.
-
8th row is an Int32 and it actually stores the second property of the table (age = 34)
-
9th row is an Int32 which stores the length of the string "maxim" which was referred on 7th row
-
10th row contains the string "maxim" encoded in UTF8.
We are done!
Previous excursion into depths of data representation in FlatBuffers might scare some people of. One can argue that FlatBuffers follows the Fundamental theorem of software engineering
"We can solve any problem by introducing an extra level of indirection."
However if we analyse how those indirections help us, we might come to another conclusion.
First and most obvious benefit of an indirection is the fact that we can store the date not only as a tree but as a graph.
Here is a schema where we can store a list of people:
table List {
people : [Person];
}
table Person {
firstName : string;
lastName : string;
}
root_type List;
and here is an example of data we can represent as JSON:
[{"firstName":"Maxim","lastName":"Zaks"},{"firstName":"Alex","lastName":"Zaks"}]Again using the Swift API we can get something like:
let p1 = Person(firstName: "Maxim", lastName: "Zaks")
let p2 = Person(firstName: "Alex", lastName: "Zaks")
let list = List(people: [p1, p2])
let fbData = list.toByteArray
// [10, 0, 0, 0, 6, 0, 8, 0, 4, 0, 6, 0, 0, 0, 4, 0, 0, 0, 2, 0, 0, 0, 8, 0, 0, 0, 33, 0, 0, 0, 235, 255, 255, 255, 8, 0, 0, 0, 41, 0, 0, 0, 5, 0, 0, 0, 77, 97, 120, 105, 109, 8, 0, 12, 0, 4, 0, 8, 0, 8, 0, 0, 0, 8, 0, 0, 0, 12, 0, 0, 0, 4, 0, 0, 0, 65, 108, 101, 120, 4, 0, 0, 0, 90, 97, 107, 115]This time we got a byte array of length 87. Let's see what is inside
10, 0, 0, 0, position of root table list : List
-- list : List
6, 0, size vTable List
8, 0, size List data
4, 0, rel. pos 'people' field
6, 0, 0, 0, root of Table list : List
4, 0, 0, 0, rel. pos people Vector
-- list.people
2, 0, 0, 0, length of vector
8, 0, 0, 0, rel. pos to p1 : Person
33, 0, 0, 0, rel. pos to p2 : Person
-- p1
235, 255, 255, 255, root of Table p1 : Person
8, 0, 0, 0, rel. pos to String 'Maxim'
41, 0, 0, 0, rel. pos to String 'Zaks'
-- p1.firstName = "Maxim"
5, 0, 0, 0, Length of 'Maxim' string
77, 97, 120, 105, 109, 'Maxim' string UTF8 Encoded
-- p2
8, 0, size vTable Person
12, 0, size Person data
4, 0, rel. pos 'firstName' field
8, 0, rel. pos 'lastName' field
8, 0, 0, 0, root of Table p2 : Person
8, 0, 0, 0, rel pos. to String 'Alex'
12, 0, 0, 0, rel pos. to String 'Zaks'
-- p2.firstName = "Alex"
4, 0, 0, 0, length of String 'Alex'
65, 108, 101, 120, 'Alex' string UTF8 Encoded
-- p1.lastName = "Zaks" && p2.lastName = "Zaks"
4, 0, 0, 0, length of String 'Zaks'
90, 97, 107, 115 'Zaks' string UTF8 Encoded
As we are a bit more experienced with FlatBuffers binary representation I want to point out just some interesting facts.
The representation of p1 is very concise, because it has no vTable of it's own. The root of Table p1 is defined as 235, 255, 255, 255 which translates to -21 when converted to Int32. Meaning that we can find the vTable 21 bytes ahead, which is the vTable of p2. This is possible because both instances have same relative layout. You can also see that the string "Zaks" is stored only once.
The indirections let us reuse equal parts of memory. Therefore leading to a smaller footprint, for repeating data.
Achieving a small footprint by collapsing tree into a graph is an important benefit of the FlatBuffer layout, but it is not the most important one. Way more important is the fact that, if you introduce a non destructive changes to the schema. You stay backwards and forwards compatible.
What is a non destructive change?
Let's take the simple example again:
table Person {
name: string;
age : int;
}
root_type Person;
And say we realised that age is not exactly what we wanted to store. A birthDate field would be much better. We can introduce the birthDate field non destructively by adding it to the end of the field list:
table Person {
name: string;
age : int;
birthDate : double;
}
root_type Person;
This change is not destructive because we just extended the Person table. And because of the FlatBuffers internal layout we can still read a binary which was produced with previous version of the schema. We will just get 0 for the birthDate if it is not specified.
We might also want to prohibit users from saving new states with the age. In this case we can set age to be deprecated:
table Person {
name: string;
age : int (deprecated);
birthDate : double;
}
root_type Person;
This way Swift API removes the age field from Person class, and introduces read only __age property. This way you can access the age if you deal with a state persisted by old client, but can't write it back.
This is what is called backwards compatibility. New clients can read data stored by old clients.
Forwards compatibility means that old clients can read data stored by new clients. In our example we would have a byte array which stores person with name and birthDate. An old client would still be able to get the name, but would get a 0 when it would access the age. It doesn't know about the birthDate, but this is not important. It is up to application developer to think what to do in such cases, but at least from FlatBuffers perspective everything works, without any errors.