How to use the LinkScanner utility
-
How to configure the
LinkScanner - How to use the
LinkScanner - Export and import results
- Interact and manipulate results
- Event list
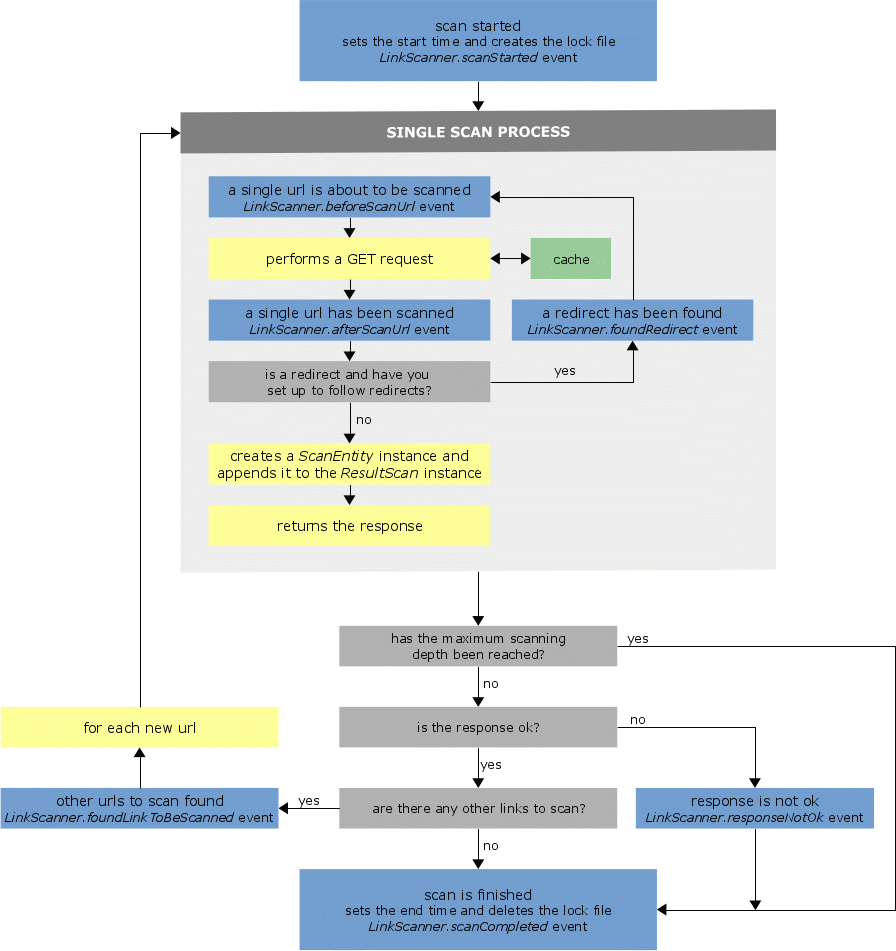
- The scanning process chart
The LinkScanner class uses the InstanceConfigTrait and then you can set up the configuration using the setConfig() method.
The default configuration:
'cache' => true,
'excludeLinks' => '/[\{\}+]/',
'exportOnlyBadResults' => false,
'externalLinks' => true,
'followRedirects' => false,
'fullBaseUrl' => null,
'maxDepth' => 0,
'lockFile' => true,
'target' => LINK_SCANNER_TMP,Explanation of configuration values:
-
cache, boolean, iftruethe cache will be used for GET responses (except for error responses). See also How to configure the cache; -
excludeLinks: string or array. Patterns of links to be excluded from the scan. By default, links that contain invalid characters will be excluded; -
exportOnlyBadResults: boolean, iftrueonly negative results will be considered when exporting. This allows you to save space for exported files; -
externalLinks: boolean, iftrueexternal links will be scanned (without recursion); -
followRedirects: boolean, iftrueredirects will be followed; -
fullBaseUrl: string ornull. This is the url from which the scan will start. IfnulltheApp.fullBaseUrlvalue will be used; -
maxDepth: integer, maximum scanning depth. If0the depth will have no limits; -
lockFile: boolean, iftruea lock file will be created at the beginning of the scan, which will then be deleted at the end. This prevents you from running multiple scans simultaneously; -
target: string, path where the scan results will be exported if no path is specified.
Example:
$LinkScanner = new LinkScanner();
$LinkScanner->setConfig('fullBaseUrl', 'http://google.com',)
->setConfig('maxDepth', 2);The setConfig() method can also accept an array, so for example:
$LinkScanner = new LinkScanner();
$LinkScanner->setConfig([
'fullBaseUrl' => 'http://google.com',
'maxDepth' => 2,
]);The LinkScanner class owns the $Client property, which is an instance of the \Cake\Http\Client and will be used to make each GET request.
Also in this case it is possible to use the setConfig() method (default configuration for the Client class). Example:
$LinkScanner = new LinkScanner();
$LinkScanner->Client->setConfig('timeout', 3);This plugin uses the HTTP Client to make requests and get responses, which are inspected and processed one by one.
This can take a lot of resources and generate a lot of network traffic. For this
reason, the plugin uses the cache (except for error responses).
By default, the cache is active. You can enable or disable it using the cache option. Example:
$LinkScanner = new LinkScanner();
//Disables the cache
$LinkScanner->setConfig('cache', false);
//Re-enables the cache
$LinkScanner->setConfig('cache', true);LinkScanner will use the homonymous cache engine defined in its bootstrap file.
If you want to use your own cache engine or if you want to use a different configuration than the default one, then you have to configure the LinkScanner cache engine before loading the plugin. Example:
Cache::setConfig('LinkScanner, [
'className' => 'File',
'duration' => '+1 day',
'path' => LINK_SCANNER_TMP . 'cache' . DS,
'prefix' => 'link_scanner_',
]);For more information on how to configure a cache engine, please refer to the Cookbook.
A convenient alternative to configure LinkScanner is to use a configuration file.
Create the APP/config/link_scanner.php file. The file must return an array with the LinkScanner key and as value a sub-array containing the configuration:
<?php
return [
'LinkScanner' => [
'cache' => true,
'excludeLinks' => [
'/^https?:\/\/[^\/]+\/a-directory-to-be-excluded/',
'/[\{\}+]/',
],
'exportOnlyBadResults' => true,
'externalLinks' => false,
'followRedirects' => true,
'fullBaseUrl' => 'http://mysite.com',
],
];These values will override the default ones when the class is instantiated.
After instantiating the class and eventually changed the configuration, you can run the scanning with the scan() method.
A complete example:
$LinkScanner = new LinkScanner();
$LinkScanner->setConfig([
'externalLinks' => true,
'fullBaseUrl' => 'http://google.com',
'maxDepth' => 2,
]);
$LinkScanner->Client->setConfig('timeout', 3);
$LinkScanner->scan();This means that:
- the scan will have a maximum depth of 2 levels;
- the scan will take place starting from
http://google.com; - external links will not be followed (against the initial URL);
- the
Clientwho will make the GET requests will use a 3 second timeout.
After the scan, you can get some LinkScanner properties. A full example:
$LinkScanner = new LinkScanner();
$LinkScanner->setConfig([
'externalLinks' => true,
'fullBaseUrl' => 'http://google.com',
'maxDepth' => 2,
]);
$LinkScanner->Client->setConfig('timeout', 3);
$LinkScanner->scan();
print 'Scanning started from the url: ' . $LinkScanner->getConfig('fullBaseUrl');
print PHP_EOL;
print 'Hostname: ' . $LinkScanner->hostname . PHP_EOL;
print 'Startime: ' . (new Time($LinkScanner->startTime))->nice() . PHP_EOL;
print 'Endtime: ' . (new Time($LinkScanner->endTime))->nice();Output:
Scanning started from the url: http://google.com
Hostname: google.com
Startime: Feb 22, 2019, 1:16 PM
Endtime: Feb 22, 2019, 1:16 PM
When the scan is completed, you can export the LinkScanner instance (and its results) with the export() method. This method takes as a single argument a path where you want to export; if it's null, the filename will be generated automatically.
The export() method returns the path of the export file. Continuing from the previous example:
$exported = $LinkScanner->export(TMP . ' my_results');It is right to point out that not only the raw results are exported, but the whole LinkScanner instance, with its properties and with the scan results.
Instead, you can import the results using the import() method, which takes a path as the only argument and returns a LinkScanner instance:
$LinkScanner = new LinkScanner();
$LinkScanner->import(TMP . ' my_results');The LinkScanner instance owns the $ResultScan property (a ResultScan instance), which at the end of the scan will be populated with results.
ResultScan extends Cake\Collection\Collection and so you can use all the Collection methods described in the CookBook.
In fact, each scanned url becomes a ScanEntity instance and will be added to the ResultScan instance. In other words, the $ResultScan property contains a collection of results, where each result is a ScanEntity instance.
Each ScanEntity instance has these properties:
-
code, integer, the HTTP status code (eg200or404); -
external, boolean,trueif is an external link (compared to the full base url); -
location, string, the location header (for the url that are redirect); -
type, string, the response type (egtext/html; charset=UTF-8); -
url, string, the current url; -
referer, string ornull, the referer.
Moreover, a ScanEntity instance can call all the methods of the Cake\Http\Client\Response class, thanks to the __call() method.
On this wiki you can find some examples for ResultScan.
The LinkScanner can trigger some events:
-
LinkScanner.afterScanUrlwill be triggered after a single url is scanned; -
LinkScanner.beforeScanUrlwill be triggered before a single url is scanned; -
LinkScanner.foundLinkToBeScannedwill be triggered when other links to be scanned are found; -
LinkScanner.foundRedirectwill be triggered if a redirect is found; -
LinkScanner.resultsImportedwill be triggered when the results have been exported; -
LinkScanner.responseNotOkwill be triggered when a single url is scanned and the response is not ok; -
LinkScanner.resultsExportedwill be triggered when the results have been exported; -
LinkScanner.scanStartedwill be triggered before the scan starts; -
LinkScanner.scanCompletedwill be triggered after the scan is finished.
This chart illustrates the entire scanning process.