Releases: microsoft/SynapseML
MMLSpark v1.0.0-rc4
v1.0.0-rc4
Bug Fixes 🐞
- fix setLinkedService in Synapse
- fix cognitive service errors (#1176)
- fix anomaly detector test cases
- rename NERPii to PII
- fix scala style error
- fix cog service test flakes
- fix setLinkedService issues in Synapse (#1177)
- improve LGBM error message for invalid slot names (#1160)
- flaky lime test
- fix flaky conversation transcription test
- fix SpeechToTextSDK setLinedService (#1138)
- fix generated python code (#1121)
- update notebookUtils class path (#1118)
- LIME returns NaN weight if a feature contains a single value or when the sampler cannot obtain a different state for a feature due to data skew. It returns zero weights for all other features. (#1117)
- fix Guava version issue in Azure Synapse and Databricks (#1103)
- fix flakiness in spark session stopping
- Fix result parsing for forms
- LIME sometimes return nan weights (#1112)
- reformat code
- explainers return wrong results when targetClassesCol is specified
- Unit test OOM error (#1093)
- Update codeowners (#1092)
- BingImageSearch fails randomly in E2E test (#1082)
- [Workaround] CNTKModel does not output correct result (#1076)
- small issue with null in bing image response (#1067)
- fix flaky conversation transcription test
- avoid strange issue with databricks json parser
- fix dependency exclusions and build secret querying
- Fix issue in tabular lime sampler (#1058)
- Bing search URL update (#1048)
- early stopping test and average precision metric (#1034)
- refactor python wrappers to use common class (#758)
- java params patch (#1027)
- missing returns in new python lightgbm model methods
- fix issue with r bindings silently failing
- fix conversation transcription participant column functionality
- reduce verbosity to prevent RPC disassociated errors
- Fix performance slip in Featurize
- add timeout for stt
- update subscription in build secrets
- Add ffmpeg time limit enforcing for flaky streams (#1001)
- fix upload python whl file to blob(#1000)
- adding more recommendation code owners (#996)
- cleanup python tests (#994)
- Fix read schemas (#988)
- fix issue with NER suite test
- make concurrent timeout infinite
- Make rate limiting retry indefinitely
- Recommender Patch for Spark 3 Update (#982)
- fix typo in text sentimant schema
- change ints to longs for offset and duration in STT
- fix python tests in build
- fix processing sparse vector size
- Fix Double User agent setting bug
Build 🏭
- add two teired security for build secrets
- Fixing build warnings (#1080)
- update ubuntu version to 18.04
- fix build for new intellij
- fix livy dependency resolution
Doc
- add predictive maintenence notebook
- Add CyberML link to README.md (#989)
- Add example cyberML notebook (#958)
Documentation 📘
- Adding document and notebooks for ONNXModel (#1164)
- Documentation and notebooks for Interpretability on Spark
- Add explicit pointer to HDI install
- fix typo (#990)
- Bump python install to top to make it clearer
Features 🌈
- Update Text Analytics API to V3.1 (#1193)
- add NERPii
- Add Infrastructure to Run Tests on Synapse (#1014)
- rename Read to ReadImage (#1163)
- ONNX model inference on Spark (#1152)
- update DocumentTranslator to support setLinkedService in Synapse (#1151)
- add setLinkedService (#1136)
- add translator (#1108)
- add singleton dataset mode for faster performance and use old sparse dataset create method to reduce memory usage (#1066)
- add form recognizer support (#1099)
- split library into subprojects (#1073)
- new LIME and KernelSHAP explainers (#1077)
- refactor to have separate dataset utils and partition processor (#1089)
- refactoring of lightgbm code in preparation for single dataset mode (#1088)
- move partition consolidator and add LocalAggregator API (#1071)
- add number of threads parameter (#1055)
- add custom objective function to lightgbm learners (#1054)
- Add more notebook samples for documentation (#1043)
- add matrix type parameter and improve auto logic (#1052)
- add several parameters related to dart boosting type (#1045)
- added chunk size parameter for copying java data to native (#1041)
- Add MMLSpark logging infrastructure (#1019)
- Add R wrapper gen
- add num iteration and start iteration to lightgbm model (#1024)
- Refactor code generation system
- add automated python test generation infrastructure (#998)
- add TextLIME
- Add ReadAPI
- add conversation transcription
- add m4a codec
Maintenance 🔧
- bump version numbers (#1203)
- Fix pom for sbt dependencies (#1202)
- Add script to clean and back up ACR
- fix bug in testgen parallelism
- testing new build
- disable failing synapse e2e tests
- fix flaky serialization fuzzing test
- disable failing doc translator test
- fix flakiness in python tests (#1144)
- auto-update packages in docker
- fix flaky notebook
- remove ununsed code
- fix codecov logging of wrapper generation (#1098)
- update to lightgbm 3.2.110
- fix badge publishing
- upgrade lightgbm to 3.2.100
- update build to new subscription (#991)
- fix Detect face suite (#968)
- remove issue in scalastle file for new IJ
- lower threshold for STT tests
Performance Improvements 🚀
- tune chunking code, fix memory leak
- moving to new streaming API for dense data to reduce memory usage
Update
- reformat code
- update setLocation
- remove parens
- use HasSetLinkedService trait
- add more cognitive service
- add more cognitive service
- add more cognitive service
- add more cognitive service
- remove test code
- add test code
- remove testing code
- add sample code for test
- add sample code for test
- add sample code for test
- add sample code for test
- add sample code for test
- add sample code for test
- add reflection
- remove example in test files
- add class path
- add reflection
- notebook
- update spark version to 3.1.2 (#1086)
Acknowledgements
We would like to acknowledge the developers and contributors, both internal and external who helped create this version of MMLSpark.\n
Changes:
- 5fc65ab chore: bump version numbers (#1203)
- 993da81 chore: Fix pom for sbt dependencies (#1202)
- 327be83 feat: Update Text Analytics API to V3.1 (#1193)
- 6610577 fix: fix setLinkedService in Synapse
- e08a8e2 chore: Add script to clean and back up ACR
- d85aae8 fix: fix cognitive service errors (#1176)
- c6925db fix: fix anomaly detector test cases
- b52c361 fix: rename NERPii to PII
- 2ce1ba6...
MMLSpark v1.0.0-rc3
v1.0.0-rc3
Bug Fixes 🐞
- fix broken test link
- Fix incorrect indexing for determining eval prob in CB (#922)
- Update DBC path
Features 🌈
- Add Env variable parametrized UserAgent header
- Add support for ContextualBandit in the VW module (#896)
- Update text analytics api to v3 (#916)
Maintenance 🔧
- bump version to 1.0.0-rc3
Acknowledgements
We would like to acknowledge the developers and contributors, both internal and external who helped create this version of MMLSpark.
Contributors
Assets 2
MMLSpark v1.0.0-rc2

Highlights
 |
 |
 |
 |
 |
|---|---|---|---|---|
| Isolation Forest on Spark | CyberML | Speech To Text | Conditional KNN | LightGBM + SHAP |
| Distributed Nonlinear Outlier Detection | Machine Learning Tools for Cyber Security | Custom Speech to Text with Streaming Support | Scalable KNN Models with Conditional Queries | Interpret LightGBM Models using Additive Shapley Explanations |
New Features
Isolation Forest on Spark ⛺️
- Added LinkedIn's Isolation Forest outlier detection algorithm
- Read the original work for more info
CyberML 🧙♂️
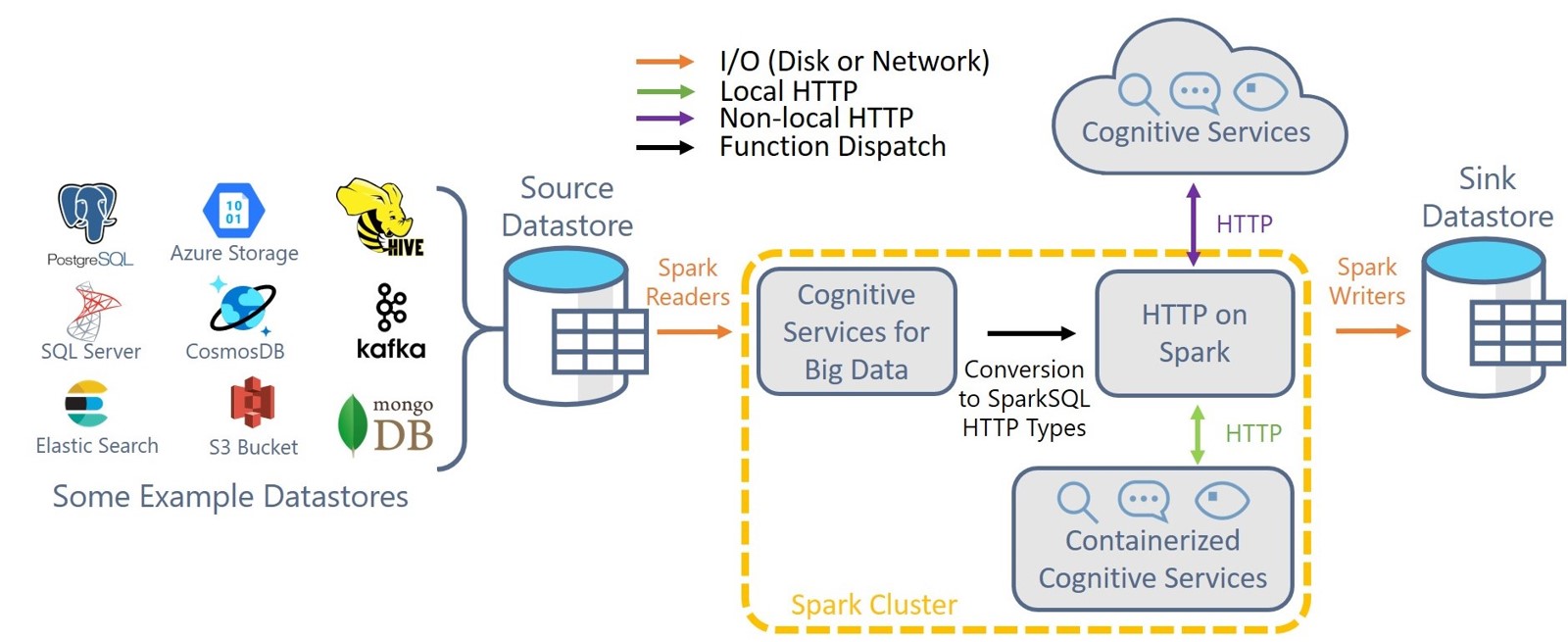
- CyberML aims to provide open source tools for distributed cybersecurity workflows. This first release includes an algorithm that learns user-resource access patterns to detect anomalous access patterns. For more information see the docs
Cognitive Services for Big Data🧠
- Added
SpechToTextSDKtransformer. This new transformer transcribes raw audio files and live audio streams into text. Transcription supports realtime audio streaming, automatic splitting into utterances, and profanity detection. Supports several languages and Custom Speech Models. - added
TextSentimentV3transformer to leverage new Cognitive Services v3 API - add save and load methods to AccessAnomalyModel (#905)
- stream robustness, output audio stream to file, and custom speech
- Add m3u8 streaming for
SpeechToTextSDK - enable mp3 file streaming in stt sdk (#822)
Conditional K-Nearest Neighbors 🏡🏡
- Added
ConditionalKNNestimator and model for efficient search of high dimensional KNNs with conditional predicates. - Added Conditional KNN demo here
- Find hidden artistic connections with the Mosaic application.
HTTP on Spark 🌐
- Added integration with python Requests to accelerate Python Requests with HTTP on Spark!
- Optimized HTTP on Spark asynchronous performance
Vowpal Wabbit on Spark 🐇
- add barrier mode support for VW (#832)
- add support for VW readable model, invert hash and re-using a previously trained VW Spark model (#821)
- support generic numeric types for weights and labels (#817)
LightGBM on Spark 🌳
- add featuresShapCol to LightGBMClassifierModel (#863)
- Expose parameter bin_construct_sample_cnt in spark for LightGBM (#780)
- add interface function for updating learning_rate per each iteration in LightGBMDelegate (#849)
- add delegate to monitor training (#847)
- Add the option to get Feature Contributions in LightGBMBooster used by LightGBMRanker (#791)
- Add option to add tolerance to improvement in metric evolution (#786)
- added pred leaf index for LightGBMClassifier
- Adding a new param for explicitly setting slot names. (#752)
- added the top_k param for voting parallel (#762)
- Adding a feature for positive and negative bagging fraction params. (#754)
Learn More
 |
 |
 |
|---|---|---|
| MosAIc Finds Hidden Connections in World Art (Article, Demo, Webinar) | Watch the Spark Summit Europe Keynote on MMLSpark | Learn about AI for Good and MMLSpark on the MSR Podcast |
 |
 |
 |
|---|---|---|
| New Docs for the Cognitive Services for Big Data | Read our New Paper on Conditional KNN Trees | Read our New Paper on Microservices in Databases |
Bug Fixes 🐞
- Updating regular Docker Images for helm chart. (#885)
- improve error message for invalid slot names (#897)
- categorical parameter regression on dense dataset caused by missing whitespace (#909)
- fix cyberml test imports
- add "s" to failing publicwasb download
- spark.executor.cores' default value based on master when counting workers (#855)
- fix flakiness in BiLSTM notebook
- make file type case insensitive
- Add support for URI parameters and default filetypes
- remove save_resume/preserve_performance_counters options as it breaks SGD/BFGS chaining (#828)
- fix optional parsing for the CustomOutputParser (#835)
- Fix flakiness in io tests
- Improve codegen readability and added getters and setters to generated models
- move tests to a separate package and refactor common code
- added multiclass init score support (#805)
- LightGBMRanker should repartition by grouping column (#778)
- Possible multithreading issue when two scores may come in parallel they may not safely fill pointer values (#799)
- Guarantee one boosterPtr is allocated and freed per LightGBMBooster instance (#792)
- Fix subtle bug in reverse index creation
- add cap on max allowed port in network init (#759)
- added min_data_in_leaf parameter (#760)
- Reorder ADB Status Checks to fix flakiness
- increase library install timeout (#763)
- Fix an issue with the sparkContext not being instantiated at eval time
- Fix GH release bade display
- Codegen dataframe param fixes
Build 🏭
- bump version
- Ignore existing installation when running installPipPackageTask (#895)
- update ffmpeg on build server
- make python test loop easier:
- updating lightgbm to 2.3.180 (#850)
- split cog services on spark tests
- Split e2e and publishing (#836)
- Add Caching to build pipeline
- added isolation forest test to build pipeline (#800)
- exclude scala from fat jar
Code Style 🎶
- Removing redundant file in the root directory: sp.txt (#796)
- ball tree style fixes
Documentation 📘
- Adding section to readme for installing with apache livy (#785)
- Add fix for maven resolver
- Added two classification examples using Vowpal Wabbit (#733)
Maintenance 🔧
- add Roy to CODEOWNERS
- fix flaky analyze image test
- move build to new subscription (#888)
- Update ...
Contributors
Assets 2
mmlspark-v1.0.0-rc1
v1.0.0-rc1
Features 🌈
- Add brands and objects to
AnalyzeImagetransformer - Add label conversion for VW binary classifier (0/1 -> -1/1) (#700)
- Add VowpalWabbit ngram support (#696)
- Add automatic schema inference for writing to Azure Search (#704)
- Add metric parameter to lightgbm learners (#672)
Bug Fixes 🐞
- Vowpal Wabbit kwargs + improvements (#692)
- Fix cast errors for label, weight, and init score columns
- Fix probabilities and some win errors
- Fix barrier execution mode with repartition for spark standalone (#651)
- Mitigate flakiness in
SpeechToTexttest
Build 🏭
- Add ability to create fat jars (#702)
- Make Databricks tests use instance pools to remove state (#673)
Code Refactoring 💎
- Clean up distributed and continuous HTTP tests
- Clean up LightGBM tests
Documentation 📘
- Example notebook of VW vs LightGBM (#641)
- Update Cognitive Service docs (#659)
- Fix typo in Spark Serving sdocs (#656)
- Add centOS to VW on spark docs
Maintenance 🔧
- Improve code-quality
- Update lightgbm to 2.2.400
- Move build to new Azure subscription (#661)
Acknowledgements
We would like to acknowledge the developers and contributors, both internal and external who helped create this version of MMLSpark.\n
Changes:
- 8d31c02 chore: Bump Version Number to 1.0.0-rc1
- 2701aed fixed early stopping test for validation (#711)
- 6b07829 docs: Example notebook of VW vs LightGBM (#641)
- 163dead fix:fix num cores per executor if config not specified (#709)
- bc0e010 chore: ignore flaky test for now
- ea7d899 feat: Add brands and objects to analyze image transformer
- 04a2fbd feat: added label conversion for VW binary classifier (0/1 -> -1/1) (#700)
- da124d7 feat: Add VowpalWabbit ngram support (#696)
- a44dafd fix validation data and ranker preprocessing
- 4037869 feat: Add automatic schema inference for writing to Azure Search (#704)
See More
- 77bb678 update lightgbm to 2.3.100, remove generateMissingLabels, fix lightgbm getting stuck on unbalanced data
- 2e45613 build: Add ability to create fat jars (#702)
- 035fcd9 cleanup duplication in unit tests (#695)
- 932ec86 adding debug for client mode issue and future investigations
- 95061d0 fix: Vowpal Wabbit kwargs + improvements (#692)
- 3ea5bc5 fix: cast errors for label, weight and init score columns
- f2bf39f fix categorical handling on lightgbm learners
- 671b688 re-enabling windows tests for lightgbm
- 8361ead add eval_at parameter to lightgbm ranker
- c0921fb Better error message when the group column is not a Int/Long
- 05a2bef fix: update lightgbm to 2.2.400, fix probabilities and some win errors
- 16ea090 chore: imporve code-quality
- ef14350 build: databricks tests use instance pools to remove state (#673)
- 8b27d88 feat: add metric parameter to lightgbm learners (#672)
- 9805996 fix: fix barrier execution mode with repartition for spark standalone (#651)
- 1e186ad chore: move to new subscription (#661)
- 360f2f7 refactor: clean up distributed HTTP tests
- 5eedc93 fix: mitigate flakiness in speechToText test
- 0290386 refactor: clean up continuous http tests
- 8ed3aeb refactor: clean up LightGBM tests
- f99c9f4 docs: Update Cog Service docs (#659)
- df089cd docs: fix typo in spark serving docs (#656)
- b369244 docs: add vw to related software
- 876553a docs: add links to readme
- 8136022 docs: change paper badge color
- f974a6a docs: improve README
- 8190eb5 Add links to API documentation
- 241a486 docs: add centOS to vw on spark docs
This list of changes was auto generated.
v0.18.1
v0.18.1
Bug Fixes 🐞
- fix lightgbm stuck in multiclass scenario and added stratified repartition transformer (#618)
- fix schema issue with databricks e2e tests (#653)
- update VW dependency to 8.7.0.2 built on CentOS and optimized for portability (#652)
Build 🏭
- add proper secrets to publishing step (#650)
Documentation 📘
- Remove script action section
Maintenance 🔧
- bump version number
Acknowledgements
We would like to acknowledge the developers and contributors, both internal and external who helped create this version of MMLSpark.
Ilya Matiach, Markus Cozowicz
Changes:
- 62946d1 chore: bump version number
- d518b8a fix: fix lightgbm stuck in multiclass scenario and added stratified repartition transformer (#618)
- 85fb3fc fix: fix schema issue with databricks e2e tests (#653)
- 258cafb fix: update VW dependency to 8.7.0.2 built on CentOS and optimized for portability (#652)
- 376cc6a build: add proper secrets to publishing step (#650)
- 0be08e9 docs: Remove script action section
This list of changes was auto generated.
v0.18.0

Microsoft ML for Apache Spark v0.18.0
Highlights
 |
 |
|
|
|---|---|---|---|
| Vowpal Wabbit on Spark | Quality and Build Refactor | LightGBM Ranking and More | Anomaly Detection and Speech To Text |
| Fast, Sparse, and Scalable Text Analytics | New Azure Pipelines build with Code Coverage, CICD, and an organized package structure. | Barrier Execution mode, performance improvements, increased parameter coverage | New cognitive services on Spark |
New Features
Vowpal Wabbit on Spark: Fast and Sparse Text Analytics
- VW on Spark is a new collaboration between the Vowpal Wabbit library and the Apache Spark community
- For full documentation check out the VW on Spark Docs
- Added
VowpalWabbitClassifierandVowpalWabbitRegressor - Added Vowpal Wabbit - Quantile Regression for Drug Discovery.ipynb
LightGBM on Spark
- Now supports barrier execution mode
- Added the
LightGBMRanker - Added
is_provide_training_metricto LightGBMRanker. - Enabled continued training with init score column
- Added batch training support
- Reduced memory usage
- Fixed issues with frozen jobs
- Fixes for multiclass classification
- Fixed issue where multiclass classification hangs due to partitions without all classes
HTTP on Spark
- Added
AnomalyDetectorandSimpleAnomalyDetectorAPIs - Added
SpeechToTexttransformer - Improved service concurrency
- Added robustness to socket timeouts
Miscellaneous
- Codegen support for wrapping
Rankerclasses - Notebooks now leverage public blob for faster execution
- Fixed summarize data column handling
- Better compute model statistics error messages
- Upgraded to Spark 2.4.3
- Added Spark on Kubernetes Helm Charts
- Added
StratifiedRepartitiontransformer for ensuring partitions contain all classes - Fixed issue where
ImageFeaturizercould not be executed on Databricks 2.4.3
Build, Quality, and Infrastructure Refactor
Azure Pipelines Integration
- Tests parallelized on Azure Pipelines. Builds now take ~25min vs ~90min!
- Serverless Builds: Queue as many builds as needed with no machine maintenance costs
- Test results, error messages, and time are viewable from github PR section
- Individual Tests can be re-queued from the GitHub PR Page
- Builds can be queued using the pull request comment:
/azp run.- Full details can be seen by typing
/azp help
- Full details can be seen by typing
- CI pipeline entirely specified in small .yaml file in git repo
Local Developer Support
- Dramatically simpler developer setup (all through SBT)
- Local developer setup now works on any platform including windows!
- Local setup no longer needs VM, Vagrant, or 30 min to import the library
- All build stages are SBT tasks and can be done locally for rapid testing
- This includes publishing maven packages to local repositories and the MMLSpark maven repo
- All secrets now managed by centralized Azure Key Vault
- IntelliJ will pick up on all scalastyle rules for editor-level style feedback while typing
Code Quality Gates
- Code Coverage now supported for every PR and reported in the comments and badge
- Coverage is now a check-in gate to never decrease
- Test coverage increased and dead code removed from the library
- Custom and auto-generated Python tests now supported
- CODEOWNERS file for better code reviews and maintenance
- Codacy integration for automated PR reviews
Streamlined Library Structure
- MMLSpark now supports a true Scala/Java idiomatic package hierarchy
- Namespace hierarchy also reflected in PySpark code
- Note: This will require changes to existing MMLSpark Programs. For Support in migrating please contact
[email protected]
Maintainability and Community Management
- Issue and PR templates
- Gitter channel
- Welcome bot to greet new contributors
- Semantic Commits for autogenerating release notes
- Badges to display current and master versions in the README
Migration Support:
- For those that already have MMLSpark developer setups please read the new developer guide to reconfigure.
- For those that have standing PRs that need rebasing assistance please reach out to
[email protected] - Please report any bugs or feedback!
Acknowledgements
We would like to acknowledge the developers and contributors, both internal and external who helped create this version of MMLSpark.
- Ilya Matiach, Markus Cozowicz, Scott Graham, Daniel Ciborowski, Christina Lee, Dalitso Banda, Shaochen Shi, Sudarshan Raghunathan, Anand Raman, Eli Barzilay, Nick Gonsalves, Tao Wu, Jeremy Reynolds, Miguel Fierro, Robert Alexander, AI CAT Team, Azure Search Team
Contributions, Collaborations, and Feedback Welcome!
 |
|---|
Changes:
- 3bb48b8 chore: bump version number
- b0797b3 docs: Improve cog services on spark docs
- 8e966b3 docs: Docs for Cognitive Services (#647)
- eb0a421 docs: Improve VW on Spark Docs
- 54dbcad docs: add VowpalWabbit documentation
- fb5b79f docs: fix vw on spark description
- c0d5786 docs: update readme badges and icons
- 071b6b0 docs: Add gitter badge
- 5c34356 docs: Add VW on Spark to table
- 1bdcdbf chore: ignore .github folder for CI
See more
- 01d498c build: add sonatype publishing
- 8fab72d build: make e2e cancellable
- ddc7a4f build: remove broken codecov flags (will reinstate when codecov fixes their service_
- 188cbdb chore: Update issue templates
- f67b16a chore: fix welcome bot indenting
- eeb7eba fix: Fix logistic regression error when passing "--link logistic" (#644)
- b6a4f93 fix: fix socket timeout error (#640)
- 856db6d build: add mcr publishing
- c6e44f9 fix: fix issue with socket timeout in advanced handler
- 2425b7a fix: update detect anomaly suite to make anomaly more pronounced
- 07c7fec style: run markdown through markdown linter
- a0e85f5 build: increase setup timeouts
- 5c190f8 style: Fix style issues
- 4bf6f71 build: Add build cancel timeouts
- 915d683 build: add release job to Azure Pipelines
- e48f9cb build: Add github version badges
- 73581cb build: fix flaky codecov upload
- ce1e66d build: fix e2e notebook cluster check
- 19aeb80 build: Add behavior bot
- 72ccae2 build: Make task retry part of bash script
- 16dd7f4 Update formatting
- 3fe4db5 adding vagrant doc and fixing indentation in vagrantfile
- d58d6f4 Vowpal Wabbit on Spark
- 95dc734 adding vagrant file back in, updated for sbt (#622)
- 605c98f Add flaky test retry
- 4ebbb41 remove brittle dataset downloading from demos
- e572a9a try to Fix codecov upload
- fac542e Add codecov to python tests
- b6ba62f Add test publishing tobuild
- 5cada6f Increase coverage and remove dead code
- ae191a6 Fix build summary
- e18ec2e leverage codecov.io's coverage capabilities
- 8e76263 Improve noisy neighbor problems for e2e tests
- 6ab8916 add codecov file
- 70881b2 improve test coverage
- 41da2b7 improve flakiness
- aa3c98f improve coverage
- 237d388 Add Code Coverage ba...
v0.17
Highlights
- LightGBM evaluation 3-4x faster!
- Spark Serving v2
- LightGBM training supports early stopping and regularization
- LIME on Spark significantly faster
New Features
Spark Serving v2:
- Both Microbatch and Continuous mode have sub-millisecond latency
- Supports fault tolerance
- Can reply from anywhere in the pipeline
- Fail fast modes for warning callers of bad JSON parsing
- Fully based on DataSource API v2
LightGBM:
- 3-4x evaluation performance improvement
- Add early stopping capabilities
- Added L1 and L2 Regularization parameters
- Made network init more robust
- Fixed bug caused by empty partitions
LIME on Spark:
- LIME Parallelization significantly faster for large datasets
- Tabular Lime now supported
Other:
- Added UnicodeNormalizer for working with complex text
- Recognize Text exposes parameters for its polling handlers
Acknowledgements
We would like to acknowledge the developers and contributors, both internal and external who helped create this version of MMLSpark.
- Ilya Matiach, Markus Cozowicz, Scott Graham, Daniel Ciborowski, Jeremy Reynolds, Miguel Fierro, Robert Alexander, Tao Wu, Sudarshan Raghunathan, Anand Raman,Casey Hong, Karthik Rajendran, Dalitso Banda, Manon Knoertzer, Lars Ahlfors, The Microsoft AI Development Acceleration Program, Cognitive Search Team, Azure Search Team
v0.16
New Features
- Added the
AzureSearchWriterfor integrating Spark with Azure Search - Added the Smart Adaptive Recommender (SAR) for better recommendations in SparkML
- Added Named Entity Recognition Cognitive Service on Spark
- Several new LightGBM features (Multiclass Classification, Windows Support, Class Balancing, Custom Boosting, etc.)
- Added Ranking Train Validation Splitter for easy ranking experiments
- All Computer Vision Services can now send binary data or URLs to Cognitive Services
New Examples
- Learn how to use the Azure Search writer to create a visual search system for The Metropolitan Museum of Art with: AzureSearchIndex - Met Artworks.ipynb
Updates and Improvements
General
- MMLSpark Image Schema now unified with Spark Core
- Now supports Query pushdown and Deep Learning Pipelines
- Bugfixes for Text Analytics services
PageSplitternow propagates nulls- HTTP on Spark now supports socket and read timeouts
HyperparamBuilderpython wrappers now return idiomatic python objects
LightGBM on Spark
- Added multiclass classification
- Added multiple types of boosting (Gradient Boosting Decision Tree, Random Forest, Dropout meet Multiple Additive Regression Trees, Gradient-based One-Side Sampling)
- Added windows OS support/bugfix
- LightGBM version bumped to
2.2.200 - Added native support for categorical columns, either through Spark's StringIndexer, MMLSpark's ValueIndexer or list of indexes/slot names parameter
isUnbalanceparameter for unbalanced datasets- Added boost from average parameter
Acknowledgements
We would like to acknowledge the developers and contributors, both internal and external who helped create this version of MMLSpark.
- Ilya Matiach, Casey Hong, Daniel Ciborowski, Karthik Rajendran, Dalitso Banda, Manon Knoertzer, Sudarshan Raghunathan, Anand Raman,Markus Cozowicz, The Microsoft AI Development Acceleration Program, Cognitive Search Team, Azure Search Team
v0.15
New Features
- Add the
TagImageandDescribeImageservices - Add Ranking Cross Validator and Evaluator
New Examples
- Learn how to use HTTP on Spark to work with arbitrary web services at scale in HttpOnSpark - Working with Arbitrary Web APIs.ipynb
Updates and Improvements
LightGBM
- Fix issue with
raw2probabilityInPlace - Add weight column
- Add
getModelAPI toTrainClassifierandTrainRegressor - Improve robustness of getting executor cores
HTTP on Spark and Spark Serving
- Improve robustness of Gateway creation and management
- Imrpove Gateway documentation
Version Bumps
- Updated to Spark 2.4.0
- LightGBM version update to 2.1.250
Misc
- Fix Flaky Tests
- Remove autogeneration of scalastyle
- Increase training dataset size in snow leopard example
Acknowledgements
We would like to acknowledge the developers and contributors, both internal and external who helped create this version of MMLSpark.
- Ilya Matiach, Casey Hong, Karthik Rajendran, Daniel Ciborowski, Sebastien Thomas, Eli Barzilay, Sudarshan Raghunathan, @flybywind, @wentongxin, @haal
Contributors
Assets 2
v0.14
New Features
- The Cognitive Services on Spark: A simple and scalable integration between the Microsoft Cognitive Services and SparkML
- Bing Image Search
- Computer Vision: OCR, Recognize Text, Recognize Domain Specific Content,
Analyze Image, Generate Thumbnails - Text Analytics: Language Detector, Entity Detector, Key Phrase Extractor,
Sentiment Detector, Named Entity Recognition - Face: Detect, Find Similar, Identify, Group, Verify
- Added distributed model interpretability with LIME on Spark
- 100x lower latencies (<1ms) with Spark Serving
- Expanded Spark Serving to cover the full HTTP protocol
- Added the
SuperpixelTransformerfor segmenting images - Added a Fluent API,
mlTransformandmlFit, for composing pipelines more elegantly
New Examples
- Chain together cognitive services to understand the feelings of your favorite celebrities with
CognitiveServices - Celebrity Quote Analysis.ipynb - Explore how you can use Bing Image Search and Distributed Model Interpretability to get an Object Detection system without labeling any data in
ModelInterpretation - Snow Leopard Detection.ipynb - See how to deploy any spark computation as a Web service on any Spark platform with the
SparkServing - Deploying a Classifier.ipynbnotebook
Updates and Improvements
LightGBM
- More APIs for loading LightGBM Native Models
- LightGBM training checkpointing and continuation
- Added tweedie variance power to LightGBM
- Added early stopping to lightGBM
- Added feature importances to LightGBM
- Added a PMML exporter for LightGBM on Spark
HTTP on Spark
- Added the
VectorizableParamfor creating column parameterizable inputs - Added
handlerparameter added to HTTP services - HTTP on Spark now propagates nulls robustly
Version Bumps
- Updated to Spark 2.3.1
- LightGBM version update to 2.1.250
Misc
- Added Vagrantfile for easy windows developer setup
- Improved Image Reader fault tolerance
- Reorganized Examples into Topics
- Generalized Image Featurizer and other Image based code to handle Binary Files as well as Spark Images
- Added
ModelDownloaderR wrapper - Added
getBestModelandgetBestModelInfotoTuneHyperparameters - Expanded Binary File Reading APIs
- Added
ExplodeandLambdatransformers - Added
SparkBindingstrait for automating spark binding creation - Added retries and timeouts to
ModelDownloader - Added
ResizeImageTransformerto removeImageFeaturizerdependence on OpenCV
Acknowledgements
We would like to acknowledge the developers and contributors, both internal and external who helped create this version of MMLSpark. (In alphabetical order)
- Abhiram Eswaran, Anand Raman, Ari Green, Arvind Krishnaa Jagannathan, Ben Brodsky, Casey Hong, Courtney Cochrane, Henrik Frystyk Nielsen, Ilya Matiach, Janhavi Suresh Mahajan, Jaya Susan Mathew, Karthik Rajendran, Mario Inchiosa, Minsoo Thigpen, Soundar Srinivasan, Sudarshan Raghunathan, @terrytangyuan