v0.18.0

Microsoft ML for Apache Spark v0.18.0
Highlights
 |
 |
 |
 |
|---|---|---|---|
| Vowpal Wabbit on Spark | Quality and Build Refactor | LightGBM Ranking and More | Anomaly Detection and Speech To Text |
| Fast, Sparse, and Scalable Text Analytics | New Azure Pipelines build with Code Coverage, CICD, and an organized package structure. | Barrier Execution mode, performance improvements, increased parameter coverage | New cognitive services on Spark |
New Features
Vowpal Wabbit on Spark: Fast and Sparse Text Analytics
- VW on Spark is a new collaboration between the Vowpal Wabbit library and the Apache Spark community
- For full documentation check out the VW on Spark Docs
- Added
VowpalWabbitClassifierandVowpalWabbitRegressor - Added Vowpal Wabbit - Quantile Regression for Drug Discovery.ipynb
LightGBM on Spark
- Now supports barrier execution mode
- Added the
LightGBMRanker - Added
is_provide_training_metricto LightGBMRanker. - Enabled continued training with init score column
- Added batch training support
- Reduced memory usage
- Fixed issues with frozen jobs
- Fixes for multiclass classification
- Fixed issue where multiclass classification hangs due to partitions without all classes
HTTP on Spark
- Added
AnomalyDetectorandSimpleAnomalyDetectorAPIs - Added
SpeechToTexttransformer - Improved service concurrency
- Added robustness to socket timeouts
Miscellaneous
- Codegen support for wrapping
Rankerclasses - Notebooks now leverage public blob for faster execution
- Fixed summarize data column handling
- Better compute model statistics error messages
- Upgraded to Spark 2.4.3
- Added Spark on Kubernetes Helm Charts
- Added
StratifiedRepartitiontransformer for ensuring partitions contain all classes - Fixed issue where
ImageFeaturizercould not be executed on Databricks 2.4.3
Build, Quality, and Infrastructure Refactor
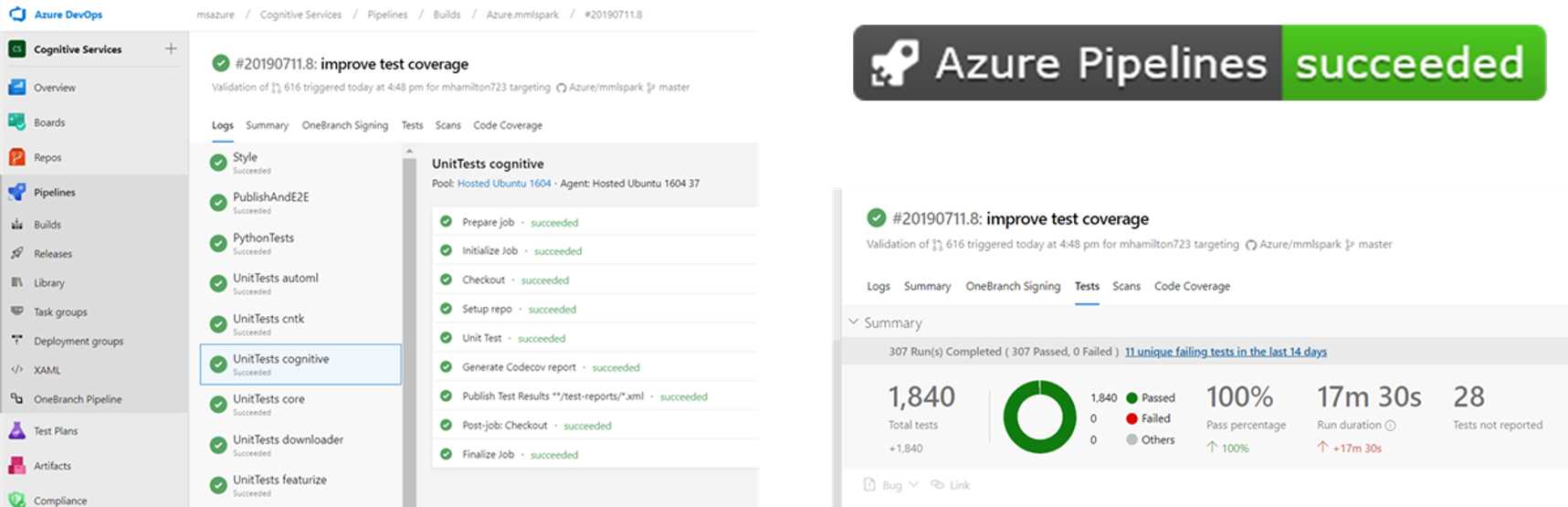
Azure Pipelines Integration
- Tests parallelized on Azure Pipelines. Builds now take ~25min vs ~90min!
- Serverless Builds: Queue as many builds as needed with no machine maintenance costs
- Test results, error messages, and time are viewable from github PR section
- Individual Tests can be re-queued from the GitHub PR Page
- Builds can be queued using the pull request comment:
/azp run.- Full details can be seen by typing
/azp help
- Full details can be seen by typing
- CI pipeline entirely specified in small .yaml file in git repo
Local Developer Support
- Dramatically simpler developer setup (all through SBT)
- Local developer setup now works on any platform including windows!
- Local setup no longer needs VM, Vagrant, or 30 min to import the library
- All build stages are SBT tasks and can be done locally for rapid testing
- This includes publishing maven packages to local repositories and the MMLSpark maven repo
- All secrets now managed by centralized Azure Key Vault
- IntelliJ will pick up on all scalastyle rules for editor-level style feedback while typing
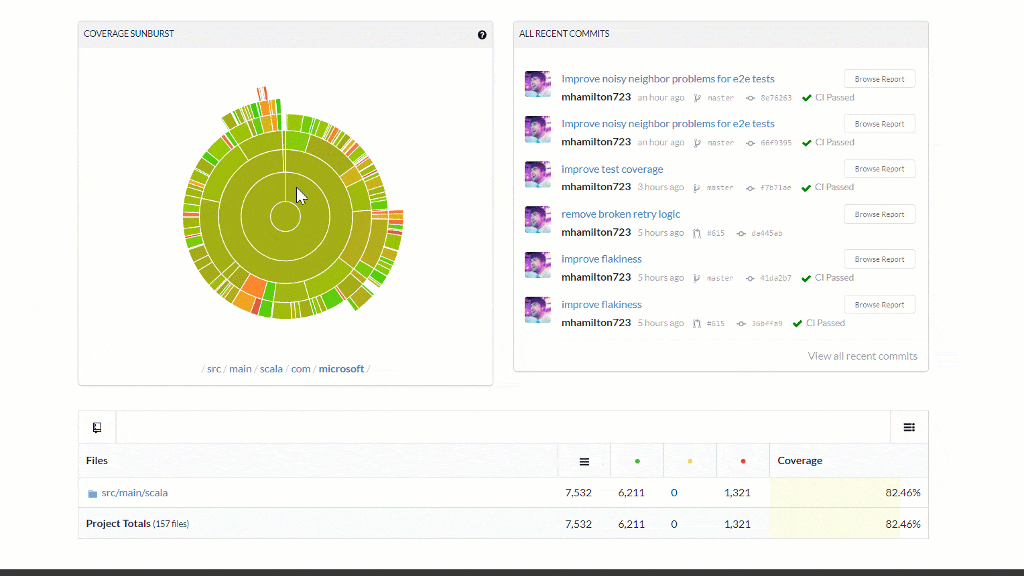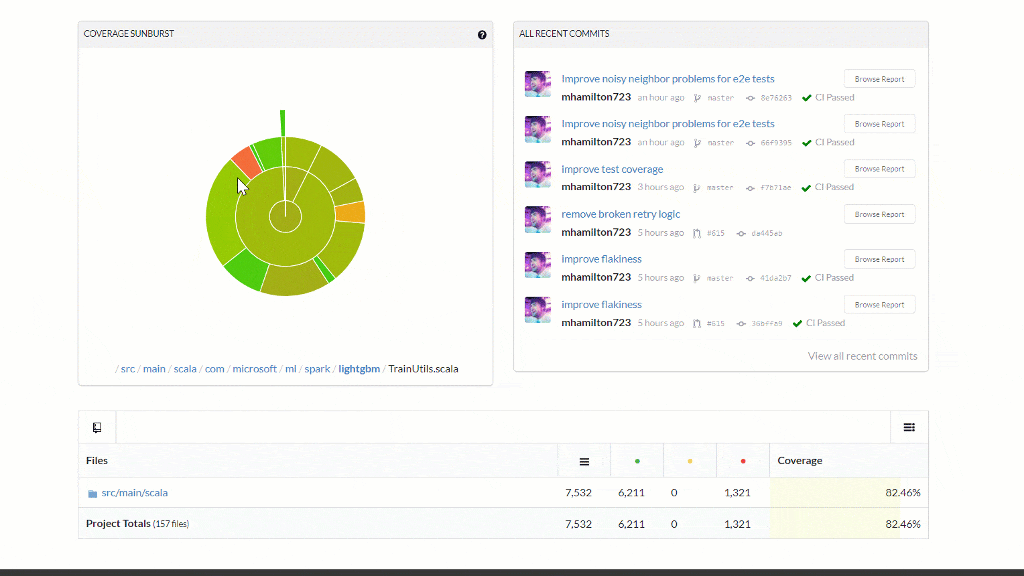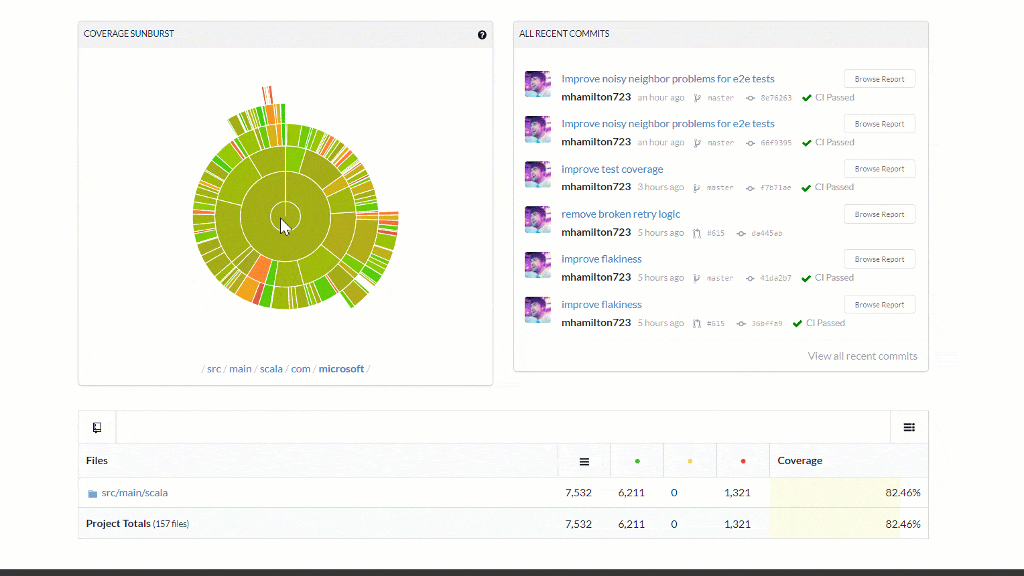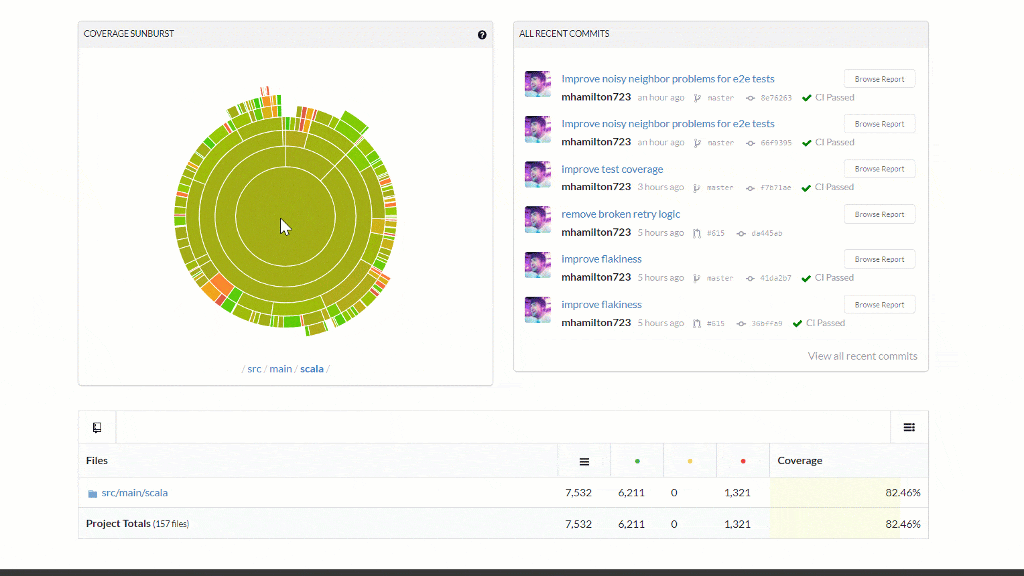
Code Quality Gates
- Code Coverage now supported for every PR and reported in the comments and badge
- Coverage is now a check-in gate to never decrease
- Test coverage increased and dead code removed from the library
- Custom and auto-generated Python tests now supported
- CODEOWNERS file for better code reviews and maintenance
- Codacy integration for automated PR reviews
Streamlined Library Structure
- MMLSpark now supports a true Scala/Java idiomatic package hierarchy
- Namespace hierarchy also reflected in PySpark code
- Note: This will require changes to existing MMLSpark Programs. For Support in migrating please contact
[email protected]
Maintainability and Community Management
- Issue and PR templates
- Gitter channel
- Welcome bot to greet new contributors
- Semantic Commits for autogenerating release notes
- Badges to display current and master versions in the README
Migration Support:
- For those that already have MMLSpark developer setups please read the new developer guide to reconfigure.
- For those that have standing PRs that need rebasing assistance please reach out to
[email protected] - Please report any bugs or feedback!
Acknowledgements
We would like to acknowledge the developers and contributors, both internal and external who helped create this version of MMLSpark.
- Ilya Matiach, Markus Cozowicz, Scott Graham, Daniel Ciborowski, Christina Lee, Dalitso Banda, Shaochen Shi, Sudarshan Raghunathan, Anand Raman, Eli Barzilay, Nick Gonsalves, Tao Wu, Jeremy Reynolds, Miguel Fierro, Robert Alexander, AI CAT Team, Azure Search Team
Contributions, Collaborations, and Feedback Welcome!
 |
|---|
Changes:
- 3bb48b8 chore: bump version number
- b0797b3 docs: Improve cog services on spark docs
- 8e966b3 docs: Docs for Cognitive Services (#647)
- eb0a421 docs: Improve VW on Spark Docs
- 54dbcad docs: add VowpalWabbit documentation
- fb5b79f docs: fix vw on spark description
- c0d5786 docs: update readme badges and icons
- 071b6b0 docs: Add gitter badge
- 5c34356 docs: Add VW on Spark to table
- 1bdcdbf chore: ignore .github folder for CI
See more
- 01d498c build: add sonatype publishing
- 8fab72d build: make e2e cancellable
- ddc7a4f build: remove broken codecov flags (will reinstate when codecov fixes their service_
- 188cbdb chore: Update issue templates
- f67b16a chore: fix welcome bot indenting
- eeb7eba fix: Fix logistic regression error when passing "--link logistic" (#644)
- b6a4f93 fix: fix socket timeout error (#640)
- 856db6d build: add mcr publishing
- c6e44f9 fix: fix issue with socket timeout in advanced handler
- 2425b7a fix: update detect anomaly suite to make anomaly more pronounced
- 07c7fec style: run markdown through markdown linter
- a0e85f5 build: increase setup timeouts
- 5c190f8 style: Fix style issues
- 4bf6f71 build: Add build cancel timeouts
- 915d683 build: add release job to Azure Pipelines
- e48f9cb build: Add github version badges
- 73581cb build: fix flaky codecov upload
- ce1e66d build: fix e2e notebook cluster check
- 19aeb80 build: Add behavior bot
- 72ccae2 build: Make task retry part of bash script
- 16dd7f4 Update formatting
- 3fe4db5 adding vagrant doc and fixing indentation in vagrantfile
- d58d6f4 Vowpal Wabbit on Spark
- 95dc734 adding vagrant file back in, updated for sbt (#622)
- 605c98f Add flaky test retry
- 4ebbb41 remove brittle dataset downloading from demos
- e572a9a try to Fix codecov upload
- fac542e Add codecov to python tests
- b6ba62f Add test publishing tobuild
- 5cada6f Increase coverage and remove dead code
- ae191a6 Fix build summary
- e18ec2e leverage codecov.io's coverage capabilities
- 8e76263 Improve noisy neighbor problems for e2e tests
- 6ab8916 add codecov file
- 70881b2 improve test coverage
- 41da2b7 improve flakiness
- aa3c98f improve coverage
- 237d388 Add Code Coverage badge
- 7146b9b Add unit test timeout
- fa87e42 Fix noisy neighbor search index tests
- 0f98f7d add codeowners file
- 4321809 add codeowners file
- 80aecab Add upload to codecov.io
- 66db39f Split LGBM tests for speed
- a6998ec Update README.md
- 027e6d7 Remove unused code
- 0205b7e Squash with partition fix
- dc1554f Add r package upload
- 2fbd81c Fix pipeline retry
- 0fde594 attempt to fix partition consolidator flakiness
- 7940967 Add codecov
- 7e8225f fix retry logic
- d8c0eb4 Increase timeout for e2e notebook tests
- ff059a3 Add ability to retry pipeline
- 8cf91ca Simplify build pipeline
- 5c8c903 Delete runme
- 210b522 Update CNTK code in README
- da6e497 Update pipeline.yaml for Azure Pipelines
- e946318 Add build status bar
- 37d36af Enable PR builds
- 6c56326 transition to new build system
- fb3e99e Update dockerfile
- 637df9d Update documentation for new build
- e9ef538 Improve test robustness
- d34f9d1 Remove unused build scripts
- 4034a4f Add doc publishing to build
- 36d8c3b Fixup after rebase
- 7c5e7b6 Get e2e tests working
- 07316a8 Fix serialization fuzzing error
- f6df907 Make recomendation tests faster
- dd99937 Add python tests
- 02a8ac6 Add publish task
- 3a526c8 Fix Test Errors and Improve Reliability
- 4a696c5 Parallelize Tests
- 2b75b62 Make build windows compatible
- 94e9b21 Add developer-readme.md
- 5659287 Fix python testing
- 987c7c4 Get python codegen to work
- 90089fa Add scalastyle and unidoc
- 79d4110 Add secrets
- 5742c0e Refactor build
- 77d7cb4 Move library into a single package
- 29c15cb add barrier execution mode
- aac0536 fix default value for double array param in codegen
- 2bd2faf fix wrapper generator for ranker models
- 6885ef5 added lightgbm ranker model pyspark api
- 08b3085 fix summarize data columns
- 044d0b5 reduce memory usage, fix frozen jobs, add more debug logging
- 45c91f9 defer lightgbm probability calculation to native core to fix multiclass bug in some scenarios (#578)
- 4473520 squish runs together
- 00ebf64 use right python version
- 216abea updated readme. more mini images
- 3232d84 Fix flakey test
- e9a612b Fix Entity Detector Suite
- ba3dbd0 Improve service concurrency
- 75819a5 Add simple Anamoly Detector
- 17a765e Add
is_provide_training_metricto LightGBMRanker. - ceb5291 Print metrics of validation data as well.
- b54363c Implement
is_provide_training_metricin Scala codes through JNI. - c7e31e6 fix query column to support long type
- 6a6d57f Poke Build System
- 11fe799 Fixing Cog Service Test
- 6eba0b6 ignore flaky test
- 53c4b9e adding LightGBMRanker
- fa77857 add init score column for continued training
- 32ac353 Add anomaly detection and speech to text services
- 06273b2 improved compute model statistics error message
- e7a309c pass through slot names to native structure
- b295dae add batch training support in lightgbm classifier and regressor
This list of changes was auto generated.