Implementation of Capture the Flag: the emergence of complex cooperative agents of the DeepMind. I first describe how to set the DeepMind lab for running the Capture The Flag map. Next, I also add a way how to design your own simple CTF map. Finally, I am going to train the agent for the Capture the Flag game in the 1 vs 1 case. The scale of the network will be a little smaller than the original paper. However, you can have a basic knowledge of how to build the agent for the CTF game.
- Python 3.8
- tensorflow==2.8.4
- tensorflow-probability==0.12.0
- opencv-python==4.2.0.34
- numpy==1.21.0
- dm-env
- pygame
- Bazel==6.4.0(sudo apt-get install gettext)
| Name | Shape | Description |
|---|---|---|
| RGB_INTERLEAVED | (640, 640, 3) | Game Screen |
| DEBUG.GADGET_AMOUNT | (1,) | Remaining Bullet Number |
| DEBUG.GADGET | (1,) | Weapon Type |
| DEBUG.HAS_RED_FLAG | (1,) | Whether or not the Player currently is holding the enemy flag |
| Name | value | Description |
|---|---|---|
| noop | _action(0, 0, 0, 0, 0, 0, 0) | |
| look_left | _action(-20, 0, 0, 0, 0, 0, 0) | |
| look_right | _action(20, 0, 0, 0, 0, 0, 0) | |
| look_up | _action(0, 10, 0, 0, 0, 0, 0) | |
| look_down | _action(0, -10, 0, 0, 0, 0, 0) | |
| strafe_left | _action(0, 0, -1, 0, 0, 0, 0) | Move left without changing the view angle |
| strafe_right | _action(0, 0, 1, 0, 0, 0, 0) | Move right without changing the view angle |
| forward | _action(0, 0, 0, 1, 0, 0, 0) | |
| backward | _action(0, 0, 0, -1, 0, 0, 0) | |
| fire | _action(0, 0, 0, 0, 1, 0, 0) | |
| jump | _action(0, 0, 0, 0, 0, 1, 0) | |
| crouch | _action(0, 0, 0, 0, 0, 0, 1) |
| Name | Description |
|---|---|
| reason | TAG_PLAYER, CTF_FLAG_BONUS |
| team | blue, red |
| score | 0, 1 |
| player_id | 1 |
| location | x, y, and z position |
| other_player_id | 2, 3, 4, 5, 6 |
The player is always the Blue team.
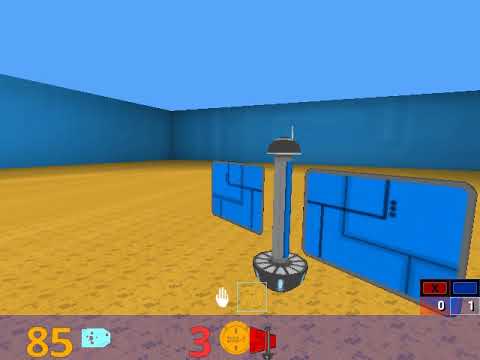
An agent can see each other without exploration, 1 vs 1 same as a simple map, default weapon
import deepmind_lab
import numpy as np
import cv2
import random
env = deepmind_lab.Lab("ctf_simple", ['RGB_INTERLEAVED', 'DEBUG.GADGET_AMOUNT', 'DEBUG.GADGET', 'DEBUG.HAS_RED_FLAG'],
{'fps': '30', 'width': '640', 'height': '640'})
env.reset(seed=1)
def _action(*entries):
return np.array(entries, dtype=np.intc)
ACTIONS = {
'look_left': _action(-20, 0, 0, 0, 0, 0, 0),
'look_right': _action(20, 0, 0, 0, 0, 0, 0),
'strafe_left': _action(0, 0, -1, 0, 0, 0, 0),
'strafe_right': _action(0, 0, 1, 0, 0, 0, 0),
'forward': _action(0, 0, 0, 1, 0, 0, 0),
'backward': _action(0, 0, 0, -1, 0, 0, 0),
'fire': _action(0, 0, 0, 0, 1, 0, 0),
}
ACTION_LIST = list(ACTIONS)
def render(obs):
obs = cv2.cvtColor(obs['RGB_INTERLEAVED'], cv2.COLOR_BGR2RGB)
cv2.imshow('obs', obs)
cv2.waitKey(1)
while True:
if not env.is_running() or step == 1000:
print('Environment stopped early')
break
env.render()
obs = env.observations()
render(obs)
action = random.choice(ACTION_LIST)
reward_game = env.step(ACTIONS[action], num_steps=2)
reward = 0
events = env.events()
if len(events) != 0:
for event in events:
if event[0] == 'reward':
event_info = event[1]
reason = event_info[0]
team = event_info[1]
score = event_info[2]
player_id = event_info[3]
location = event_info[4]
other_player_id = event_info[5]
if team == 'blue':
print("team == 'blue'")
reward = REWARDS[reason]
print("reason: {0}, team: {1}, score: {2}, reward: {3}".format(reason, team, score, reward))This environment only needs 7 actions because the map height is the same at every place.
An agent need to explore the map to find out each other, 1 vs 1 same as simple map, default weapon

import deepmind_lab
env = deepmind_lab.Lab("ctf_middle", ['RGB_INTERLEAVED', 'DEBUG.GADGET_AMOUNT', 'DEBUG.GADGET', 'DEBUG.HAS_RED_FLAG'],
{'fps': '30', 'width': '640', 'height': '640'})This environment only needs 7 actions because the map height is the same at every place.
An agent needs to explore the map to find out each other, 3 bots are added to previous maps for 2 vs 2, powerful beam-type weapon to default weapon

Like a setting of Deepmind CTF paper,

The same state and action size are used in this project.

At first, we are going to run the Capture The Flag map in human-playing mode. Try to follow the below instructions for that.
You need to clone the official DMLab from https://github.com/deepmind/lab. After that, run one of the human play examples of DMLab to check you can run the DMLab well.
Next, copy Capture the flag files to the DeepMind lab folder that you cloned. Please set the path as your own.
$ sh map_copy_dmlab.sh [deepmind lab path]
e.g $ sh map_copy_dmlab.sh /home/kimbring2/lab
Finally, you can run the Capture the Flag game using the 'bazel run :game -- -l ctf_simple -s logToStdErr=true' command from your DMLab root.
It is possible that you run the DMLab from a Python script. Before, you should install the Python package of DMLab. Follow official instructions to generate the install file for Python. Below is an example command in my workspace.
$ export PYTHON_BIN_PATH="/usr/bin/python3"
$ bazel build -c opt --python_version=PY3 //python/pip_package:build_pip_package
$./bazel-bin/python/pip_package/build_pip_package /tmp/dmlab_pkg
$ python3 -m pip install /tmp/dmlab_pkg/deepmind_lab-1.0-py3-none-any.whl
After installing, run the env_test.py file. Check that you can import DmLab using 'import deepmind_lab' code from the Python script.
The paths of cloned DMLab and Python installed are different. Therefore, you need to copy the map files to the Python package path.
$ sh map_copy_python.sh [deepmind lab path of Python]
e.g $ sh map_copy_python.sh /home/kimbring2/.local/lib/python3.8/site-packages/deepmind_lab
You can design your own map using a program called GtkRadiant. I also make the ctf_simple map like the below image.

For that, you need to install three programs mentioned in https://github.com/deepmind/lab#upstream-sources. After that, open GtkRadiant. You just need to make a closed room and put essential components for Capture The Flag game such as info_player_intermission, team_ctf_blueflag, team_ctf_redflag, team_ctf_blueplayer, team_ctf_redplayer, team_ctf_bluespawn and team_ctf_redspawn.
After installing those packages, please download the map files from baseq3. You need to copy those files under ioq3/build/release-linux-x86_64/baseq3.
After that, please check that you can play the Quake 3 Arena game by executing the ioq3/build/release-linux-x86_64/ioquake3.x86_64 file.
If you finish designing a map and make a map format file, you should convert it to a binary format called the bsp, aas. The DeepMind also provides a tool for that.
Before running that script, you need to modify the Q3MP, and BSPC path of that file according to your folder structure. Below is an example of my workspace.
readonly Q3MP="/home/kimbring2/GtkRadiant/install/q3map2"
readonly BSPC="/home/kimbring2/lab/deepmind/level_generation/bspc/bspc"
In my case, I use the command 'sudo ./compile_map.sh -a /home/kimbring2/GtkRadiant/test' for conversion. Please beware there is no gap in your map. That will make an error named the leaked.
You also need to prepare a Lua script for running a map file with DmLab. Tutorial for that can be found at minimal_level_tutorial. The only important thing is setting the game type as CAPTURE_THE_FLAG.
You can train the agent using the below command. The experiment name should be one of 'kill', or 'flag'. The 'kill' environment gives a reward when the agent kills the enemy agent. Otherwise, the agent can obtain the reward when it grabs the enemy team flag and brings it back to the home team base in the 'flag' environment
$ ./run_reinforcement_learning.sh [number of envs] [gpu use]
e.g. $ ./run_reinforcement_learning.sh 64 True
Tensorboard log file is available from the '/kill/tensorboard_actor' and '/kill/tensorboard_learner' folder.

There are a total of 4 difficult levels of bot. You can set it by changing the level parameter of ctf_simple.lua.

You can evaluate the trained agent using the below command.
$ python run_evaluation.py --exp_name [experiment name] --model_name [saved model name]
e.g. $ python run_evaluation.py --exp_name kill --model_name model_8000
I also share the pre-trained weight of my own through Google Drive. Please download from the below links
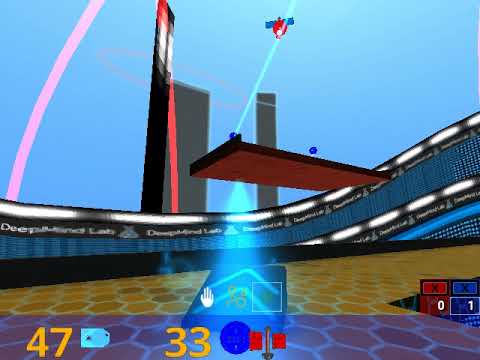
This environment needs 11 actions because there are many height changes during game playing.

- DeepMind Lab: https://github.com/deepmind/lab
- CTF map design tip: https://www.quake3world.com/forum/viewtopic.php?f=10&t=51042