Este é um projeto de previsão de fraudes em instalações de aplicativos.
Primeiramente foi feito uma análise exploratória dos dados, utilizando-se a biblioteca Pandas, onde foram identificadas as características (features) relevantes para a modelagem dos dados. Também foram feitas algumas transformações nos dados, além da criação de novas colunas/características derivadas das originais.
Após essa primeira parte, a fim de aplicar modelos de machine learning de classificação para a previsão de fraudes, os dados foram divididos em conjuntos de treino, validação e teste.
Com a utilização do método de busca em grade (Grid Search) encontrou-se a melhor combinação de hiperparâmetros que maximizavam os scores das métricas definidas, para cada um dos seis algoritmos de machine learning utilizados e que foram aplicados aos dados de treino.
São esses os algoritmos de classificação utilizados:
Depois disso, esses modelos com os melhores hiperparâmetros foram aplicados aos dados de validação a fim de obter o melhor modelo dentre eles.
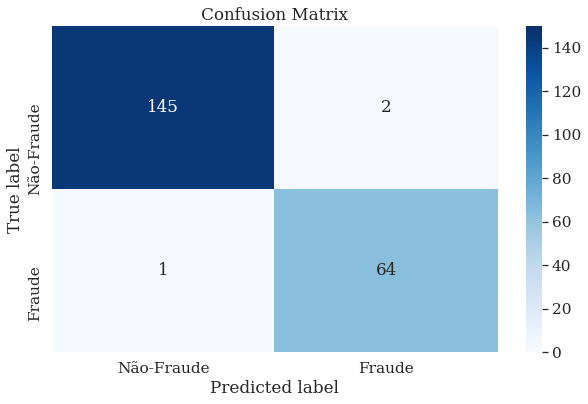
Por fim, o melhor modelo foi aplicado aos dados de teste, onde foi possível obter um excelente valor de f1-score.
A imagem a seguir mostra a matriz de confusão obtida para os dados de teste: