Sarah Nabi, Philippe Esling, Geoffroy Peeters and Frédéric Bevilacqua.
In collaboration with the dancer/choreographer Marie Bruand.
This repository is linked to our paper presented at the 9th International Conference on Movement and Computing MOCO'24. Please, visit our GitHub page for supplementary materials with examples.
In this work, we investigate the use of deep audio generative models in interactive dance/music performance. We introduce a motion-sound interactive system integrating deep audio generative model and propose three embodied interaction methods to explore deep audio latent spaces through movements. Please, refer to the paper for further details.
You can find the Max/MSP patches for the 3 proposed embodied interaction methods in the code/ folder. We also provide tutorial videos in the Usage section.
NB: You can use the Max/MSP patches with other IMU sensors by replacing the riotbitalino object.
-
We propose new MaxMSP patches to use the 3 embodied interactions strategies introduced in our paper with smartphone's IMU motion sensors instead of R-IoTs sensors initially used. To do so, we rely on the CoMote package developed by the ISMM team at IRCAM. The implementation is available in the ./code/smartphones-imu-sensors/ directory.
-
We propose new MaxMSP patches to use the embodied interactions strategies introduced in our paper with hands position tracking instead of R-IoTs IMU sensors initially used. To do so, we rely on MediaPipe with Max's javascript object
jwebconnected to a live webcamera stream. We used thejweb-hands-landmarkergithub repository. The implementation is available in the ./code/mediapipe-hands-landmarks directory.
Our motion-sound interactive system implemented in Max/MSP.
First, you need to install the required dependencies.
We used R-IoT IMU motion sensors composed of accelerometers and gyroscopes with the MuBu library and the Gestural toolkit for real-time motion capture and analysis.
For deep audio generation, we relied on the RAVE model which enables fast and high-quality audio waveform synthesis in real-time on standard laptop CPU, and we used the nn_tilde external to import our pre-trained RAVE models in Max/MSP.
You can download pre-trained RAVE models in here.

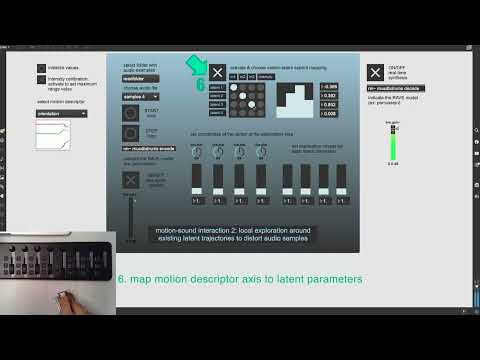
Tutorial video:
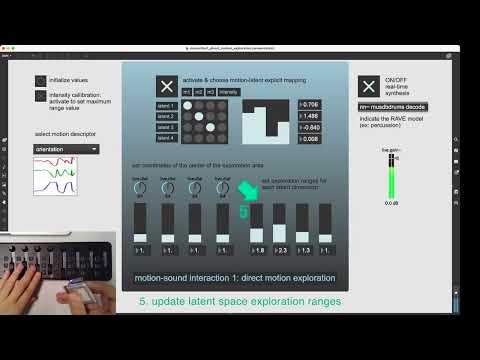

Tutorial video:
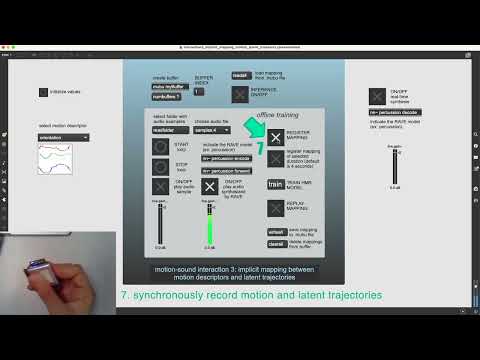
- First, do the training phase: synchronously record movement with sound to temporally-aligned both signals features and train the HMR model to capture the implicit movement-sound relationship.

- Second, do the performance phase: select the HMR model and activate the RAVE synthesis decoder for inference.

Tutorial video:
This work has been supported by the Paris Ile-de-France Région in the framework of DIM AI4IDF, and by Nuit Blanche-Ville de Paris. We extend our heartfelt thanks to Marie Bruand without which this study would not have been possible. We are also deeply grateful to our friends and colleagues from the STMS-IRCAM lab, particularly Victor Paredes, Antoine Caillon and Victor Bigand.
@inproceedings{nabi2024embodied,
title={Embodied exploration of deep latent spaces in interactive dance-music performance},
author={Nabi, Sarah and Esling, Philippe and Peeters, Geoffroy and Bevilacqua, Fr{\'e}d{\'e}ric},
booktitle={Proceedings of the 9th International Conference on Movement and Computing},
pages={1--8},
year={2024}
}