WaterML2, STA, EDR, and JSON (WIP) #21
Comments
|
See this endpoint for for a lot of ODM2/WaterML2 features forced into STA https://beta.hydroserver2.org/api/sensorthings/v1.1/ |
|
Would be interested to hear opinion about the usefulness of the various EDR query options. As we explore use cases will we be implementing all of them? or a standardized subset? |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Establishing an "IoW" opinion on data exchange, format, and web standards
TL;DR : The Way Forward
In general, the following two use cases represent at a high level what the Internet of Water is after. Both use cases focus on data that is one of four types:
Depending on the use case, water data presents some peculiarities with respect to these data tyopes
Use Case 1: Web App Development for Community Engagement and Education
Context: To enhance community engagement and education regarding water resource management, a web application is developed to make water data accessible and understandable to the general public. Example: https://maps.waterreporter.org/kuqRV2QhcCg5/
Scenario: A non-profit environmental organization aims to create an interactive web application that allows users to explore local water quality and usage data, including with a primarily visual, map-oriented interface. This application utilizes JSON-encoded data due to its ease of manipulation in common JavaScript frameworks and its compatibility with geospatial information systems. The app features interactive maps, charts, and educational content to explain the implications of water quality on community health.
Implementation Issues:
- Data Exchange and Web Standards: Within the application, a simple JSON format is used to facilitate data visualization and serves as the the format or as an intermediate format for data export. Data processing is generally client-side in a web browser or using desktop software on a personal computer.
- Simplified metadata: Users understand the meaning of the data meant to be communicated by the application without being overwhelmed by technical detail. Typically metadata required within the data itself is just a station identifier and location, variable name and definition, and units. Other contextual information such as the overall purpose and methodology of the application and its data is provided via the UX independent of the data back end.
- Data Accessibility: Lightweight, standard RESTful APIs underpin the web application, which includes a GUI that allows for data downloads, and can be exposed independently for "power users". The general query pattern allows for querying based on Space/Location, time windows, and variable.
Use Case 2: Scientific Analysis for Water Resource Management
Context: In the context of managing and protecting water resources, a scientific analysis platform is developed for researchers and policymakers. Example: https://hydrogen.princeton.edu
Scenario: A governmental agency develops a platform to facilitate the analysis of water quantity and quality across multiple jurisdictions. Researchers can access historical and real-time data, use sophisticated modeling tools, and collaborate on water management strategies.
Implementation Issues:
- Data Exchange and Web Standards: The platform rests on the aggregation of data from multiple government agencies that use a common data standard designed to carry maximal metadata. Data ETL'd into a format that is optimized for high-performance computing.
- Complex Metadata: In this scenario, detailed metadata is vital to ensure that data can be critically evaluated and appropriately used in scientific analysis. Researchers and policymakers rely on comprehensive metadata to assess provenance, and suitability for specific studies or regulatory needs. Metadata typically includes information about data collection and analysis equipment, procedures, and methodologies; data quality codes; detection limits or censor codes, environmental conditions at the point and time a measurement was taken, etc.
- Data Accessibility: The application rests on a flexible programmatic query interface and/or archives of cloud-optimized data available on the web in a documented place. Data processing occurs using high-performance infrastructure. The application includes some GUI and programmatic mechanisms for exporting highly customized data views with varying levels of metadata. Query patterns and exports are enabled for space, time, variable, methodological details, and observation-level data quality, statistical, and contextual metadata.
These use cases demonstrate how the IoW's Principles can be operationalized to develop solutions that not only meet the technical requirements of data management but also address broader goals of community engagement, scientific research, and regulatory compliance in water resource management.
Among the Principles are:
The scope of the Principles is meant to extend to all water data and related use cases. Certain classes of regulatory and administrative use cases and their required data, particularly around water infrastructure and water rights administration, are so bound up in state-level regulatory contexts that universally applicable best practices with respect to data standards are rare. However, water observation (and model) data that represent the quantity and quality of water in the natural environment is generally portable across jurisdictional boundaries for a variety of water science and management use cases. Historically, this means that the Internet of Water technical team has made recommendations with respect to water observation and model data that:
(Addressing Principles 6 and 8) Data producers make use of data models and metadata and data standards that include elements considered by the water data community to be necessary to make use of data. The IoW has used OGC or US Federal agency adoption as its main proxy to determine if such data models and standards pass the sniff test of the water data community. Possibly relevant data content standards:
WaterML2 (OGC)
WQX 3.0 (USEPA/USGS)
(Addressing Principle 3) Data producers make use of data exchange formats that serve both highly technical users as well as less-specifically-skilled users that support the development of information products and applications whose primary audience is the general public. This implies a preference for data exchange formats in JSON encodings that are easy to manipulate in existing JS frameworks, including geospatial support, and/or formats easily used by desktop spreadsheet and GIS applications. Possibly relevant exchange formats:
CSV
GeoJSON (OGC)
NetCDF (OGC)
CoverageJSON (OGC)
SensorThings JSON/ SensorThings DataArray JSON (OGC)
(Addressing Principles 4 and 9). Data producers should be encouraged to publish their data behind standardized web services/ APIs (preferably OGC adopted ones as per Principle 6) that allow for cross-organizational access and query in a federated context, or else make their data available on the web in open-spec formats via widely used data repositories (e.g. HydroShare) that support data discovery and accessibility (in bulk). Possibly relevant web standards:
Unfortunately, the current state of play in water data standards means that these principles lead to contradictory recommendations for water data content standards, water data exchange format standards, and water data web services, even when constraining to standards endorsed by the OGC. Moreover, between the two use case extremes, there is no silver bullet combination that serves both. Let us review, beginning with the underlying data model agreed to by water data community at least conceptually, and then proceed to implications for extant data exchange and web standards. To orient us to the interrelationships between all of these things, let's use a consistent dataset as a motivating example throughout. Here is a dataset daily values for streamflow and stage (height) for two separate USGS locations on the same river:
Station metadata:

Discharge and Stage data:

The Data Model: WaterML2 (Part 1: Timeseries)
WaterML2 (Part 1) is a data model adopted by OGC in 2012. It originated with something called the "Water Data Transfer Format", whose use case was to support the submission of water time series data from local government agencies and utilities in Australia to the Australian Bureau of Meteorology so that standardized data could be used to automatically calculate consistent water budgets so that water demand management measures could quickly be adopted in the context of a sever drought Australia faced in the mid-late 2000s.
The WDTF was later iterated on at OGC with participation from USGS and several international equivalents as well as CUAHSI as a representative of the international academic hydrology community to support water science. This became WaterML1 and later WaterML1.1, which is still used in the CUAHSI data infrastructure today since 2010, and the current WaterML2 standard (adopted 2012, revised 2014) used by a variety of government agencies and Kisters, one of the two major water data management software vendors. (telling that the other major vendor, Aquatic Informatics, doesn't use it at all...we'll get there).
It is a rather comprehensive data model that includes many entities, metadata elements, and supports/requires explicit references to external controlled vocabularies. Here is the complete content hierarchy:
Collection
Metadata
localDictionary[[repeatable]e.g. phenomena, quality; censorCode,method]
samplingFeatureMember (WaterML2 monitoring point(s))
observationMember[repeatable]
OM_Observation
metadata (properties that apply the result; not all are required)
Contact [repeatable]
SourceInformation
intendedSamplingInterval [optional]
status [optional]
sampleMedium [optional]
maximumGap [optional]
phenomenonTime
resultTime
validTime [optional]
procedure (methods; analytic, manual, sensor,
observedProperty (refers to phenomena local dictionary)
featureOfInterest (WaterML defines a monitoringPoint. This often refers to samplingFeatureMember)
result
metadata (properties that apply the result; not all are required)
spacing and baseTime [optional]
cumulative [optional]
aggregationDuration [optional]
defaultPointMetadata
quality
qualifier [repeatable; optional]
processing [optional]
uom
interpolationType
Point [repeatable]
time
value
TimeValuePairMetadata(defaults may come from above)
quality
qualifier ( [repeatable; optional] qualifiers, and offsets)
processing [optional]
uom [optional]
interpolationType
relatedObservation ([repeatable]used to point to a sample)
The Good
WaterML2 provides a spec for very complete metadata that allows scientists and regulators to to make a decision as to what purpose the data is useful for, and to combine it with other compliant datasets. It is used for water data exchange between USGS and NOAA to serve the National Water Model, and for data aggregation for the National Groundwater Monitoring Network.
The Bad
WaterML2 only has a standard serialization in XML. The only open-spec web service that provides WaterML2 is a SOAP /XML interface called the SensorObservationService which is generally considered to be out of date and difficult to use. There is an open-source SensorObservationService provider but as you can see from its recent PR history it's kind of on life-support. The XML is so complex to render that even USGS is discontinuing it for its high-frequency "instantaneous values" web service after a database upgrade. Few, if any functional open source clients exist for WaterML2 to meet the "Web" use case elaborated in Use Case 1. Here is our example dataset as WaterML2 XML: https://gist.github.com/ksonda/91a3ae86a01003f73e05ddf1d507e249
With WaterML2 XML having little to no support on either the data client side or the data management/provider side, we need a way to express WaterML2 in a way that is more friendly to today's web developers and water data scientists, perhaps in a flavor for each of these personas. This brings us to data exchange formats!
Data Exchange Formats
Above we covered the existing XML spec for WaterML2. What other candidates are there?
CSV. That's fine, probably should be an option as a data export, but XML and then JSON are used on the web for nested data structures and referencing controlled vocabularies for good reasons. Requires multiple files with bespoke linking patterns to represent complex metadata linked to time series observations. Also difficult to represent complex feature geometries well and error-free in CSV.
NetCDF. This is a binary file format for multidimensional arrays like timeseries data about many locations. It is very useful for bulk data exchange, and is commonly used to distribute things like regional and continental-scale climate or streamflow model output but requires specialized libraries to read and is a bit cumbersome for use in web development.
zarr. This is a new cloud-optimized multidimensional data array format that has been demonstrated to be more performant than netCDF or even parquet for this type of data. Like netCDF it requires specific libraries to read, probably more useful as a back-end than a data delivery format for web clients.
GeoJSON. The current most common standard for displaying geospatial information in web maps. It was designed as plaintext JSON counterpart to common binary data formats and file databases used in GIS applications. It includes a detailed specification to represent different kinds of geometry (point, polygon, line, etc.), and then includes a specification to include attributes. As a flavor of JSON, infinite nesting is possible. However, there is no standard for how to represent nested concepts. So, vanilla GeoJSON clients are not guaranteed to present nested metadata or time series data represented in GeoJSON documents as the author intends them to. For example, there is no guidance anywhere for web developers on how to read, translate, or unify between these two documents. Feel free to copy and paste into https://geojson.io to see how they differ to a standard client:
https://labs.waterdata.usgs.gov/sta/v1.1/Things?$filter=name%20eq%20%27USGS-02085000%27%20or%20name%20eq%20%27USGS-0209734440%27&$expand=Locations,Datastreams($expand=ObservedProperty,Sensor,Observations($top=30))
However, there is no document anywhere that recommends this query in particular. OData is so flexible (similar to GraphQL, convo for another day) that depending on the exact query, the desired entities may show up nested within each other in varying ways, so SensorThings API clients are really designed only for specific query patterns, which may not produce identical behavior across data providers who have added metadata to their SensorThings data in varying ways. Conversely, a given STA instance may provide different information to different clients nominally designed fro the same use case due to different assumptions about how the data and metadata are mapped to the STA data model. You can see this variability by exploring the different SensorThings API endpoints visualized here: https://api4inspire.k8s.ilt-dmz.iosb.fraunhofer.de/servlet/is/226/
Web Services
I use the perhaps old term "web services" to encompass standards used to make data queryable on the web without downloading the entire dataset to a local place before filtering and manipulating it. This includes API standards and cloud-optimized file formats. I will ignore zarr and geoparquet as strategies for now, since we do want to support vanilla web developers used to working with JSON.
OGC-API Features
This is a standard for querying vector data, like say, locations and attributes of water monitoring stations. This standard requires that HTML and GeoJSON be output formats, although others are allowed. Our own https://reference.geoconnex.us implements this standard. The main opinion of the standard is the following RESTful resource pattern:
/collectionsgive a list of the names, descriptions, and some provenance information for all datasets represented in the API endpoint/collections/{collectionId}give more detailed metadata about the identified collection/collections/{collectionId}/itemsgives a (default GeoJSON) feature collection of all entities in the collection (subject to pagination limits)/collections/{collectionId}/items/{itemId}gives a specific (default GeoJSON) featureThe Good
Simple RESTful pattern. Client and server implemented by ESRI and most open source GIS softwares. Good geospatial query support
The Bad
The normal limitations of GeoJSON apply. No opinions on a canonical data model. Theoretically one could use OGC-API features to give a WaterML2 XML output format if the underlying data had all of the elements available. The GeoJSON would be nonstandard though. Complex multi-entity filtering is not possible without guidance outside of the spec. Not suitable for raster data
OGC SensorThings API
This API spec is really just OData with the following entity-relationship model
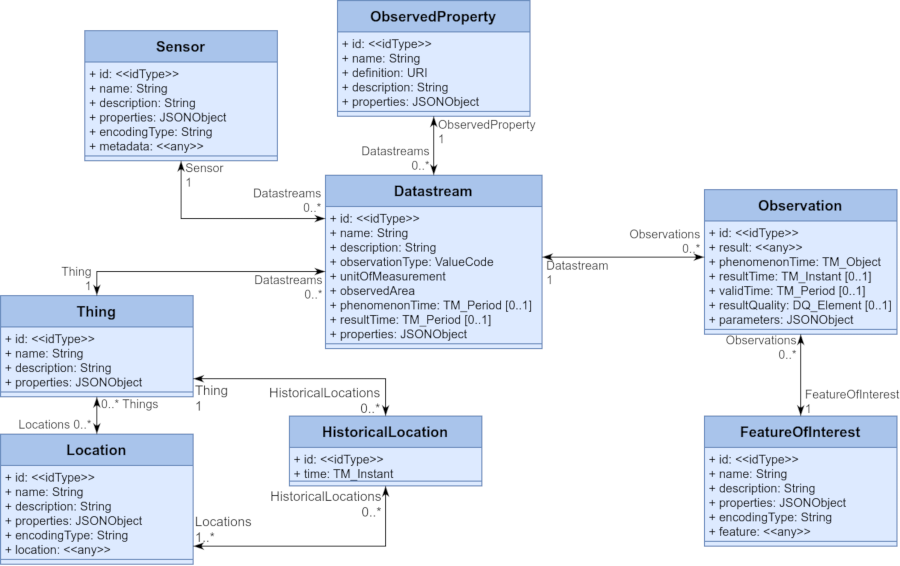
Full documentation about how it works is here
The Good
The Bad
OGC API Environmental Data Retrieval
This is a standard to query both raster and station-based data over space, time, and parameter. Its default data output format is covJSON, although others could be supported. It is highly opinionated in which query combinations are possible and what the resulting output would be. The main opinion of the standard extends the OGC-API Features model by allowing the query of a
/collections/{collectionId}by geospatial filters combined withparameter-nameanddatetime. Other functions allow for creating on-the-fly outputs at alternative spatial resolutionsThe Good
Strong, simple opinion on queries driv common behavior across clients, and makes it possible to proxy a wide variety of other web services to the same spec.
Strong, opinion on data model ensures minimum interoperability for web-app type use cases for earth observation data
Support for both raster and station-based data from one endpoint is compelling
Basic support provided in pygeoapi, which we are core contributors to.
The Bad
Current open-source implementations only support zarr as a back-end, and zarr is a fairly complex file format that many organizations would find quite foreign.
Data model is too simple, even moreso than STA, to allow filtering of all WaterML2 required entities consistently
The Way Forward #
In consideration of all of the above, in my opinion, we should
Related issues:
opengeospatial/ogcapi-environmental-data-retrieval#373
wmo-im/wis2box#703
opengeospatial/CoverageJSON#174
The text was updated successfully, but these errors were encountered: