-
- 1 复杂度分析
1.1 时间复杂度
1.2 时间复杂度量级
1.3 空间复杂度
1.4 最好最坏平均均摊时间复杂度 - 2 数组
2.1 定义
2.2 插入删除
2.3 查找 - 3 链表
3.1 插入删除
3.2 查找
3.3 单链&双向链表&循环链表
3.4 链表操作 - 4 栈
4.1 入栈出栈
4.2 顺序栈&链式栈
4.3 栈应用 - 5 队列
5.1 队头队尾
5.2 顺序队列&链式队列
5.3 循环队列
5.4 阻塞队列&并发队列 - 6 递归
6.1 堆栈溢出 - 7 排序
7.1 冒泡排序
7.2 插入排序
7.3 选择排序
7.4 归并排序
7.5 快排
7.6 桶排序
7.7 计数排序
7.8 基数排序 - 8 二分查找
- 9 跳表
- 10 散列表
10.1 散列冲突
10.2 设计工业级散列表
10.3 LRU缓存淘汰算法
10.4 Redis有序集合
10.5 哈希算法
10.6 一致性哈希算法 - 11 树
11.1 高度深度层
11.2 二叉树&满二叉树&完全二叉树
11.3 二叉查找树
11.4 红黑树
11.5 递归树
11.6 B树&B+树 - 12 堆
12.1 定义
12.2 插入删除
12.3 堆排序 - 13 图
13.1 定义
13.2 图的存储
13.3 深度,广度优先搜索 - 14 字符串匹配算法
- 15 算法思想
- 16 其他算法
- 17 算法实战
- 1 复杂度分析
- 建立时间复杂度、空间复杂度意识,写出高质量的代码
- 性能更优,核心竞争力
- 数据结构算法导图
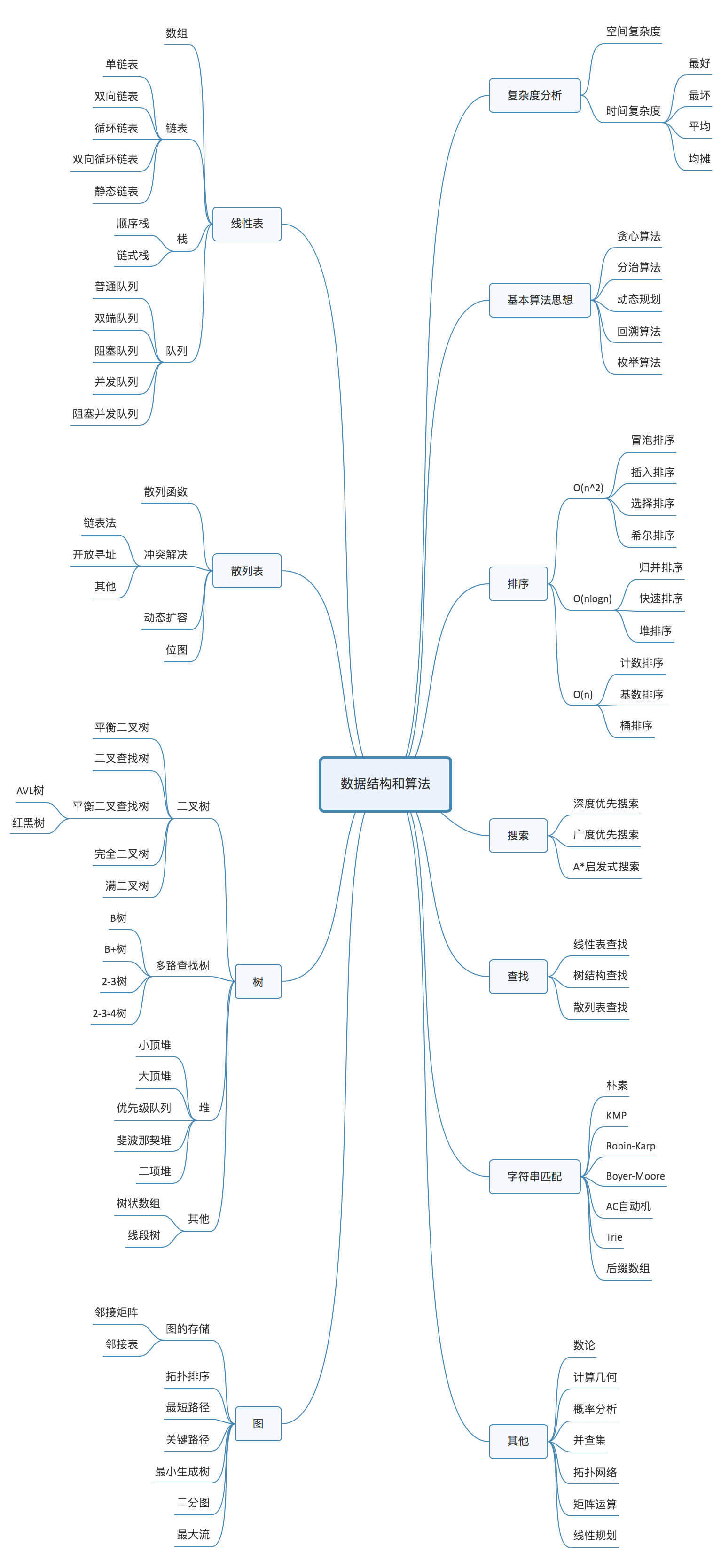{kind=link}
- 所有代码执行时间与数据规模增长的趋势,叫时间复杂度。
- 可以理解每行代码执行时间都是unit_time,执行次数和数据量的关系。知道执行次数,就能知道复杂度。
- 常数阶、对数阶、线性阶、线性对数阶、指数阶,平方阶,立方阶,k次方阶,阶乘阶。
- 算法存储空间与数据量的关系。
- 平均:执行次数*概率
- 内存连续(随机访问),数据类型相同,线性表。
- 插入删除 平均复杂度O(n)
- 查找 todo
- 随机访问 下标访问复杂度O(1)
- 插入删除 复杂度为O(1)
- 查找 复杂度O(n)
- 单链表,双向链表,循环链表. 带头链表,不带头链表
- 反转,合并有序链表,是否有环,删除倒数第n个节点,查找中间节点。
- 入栈,出栈,栈顶元素。
- 数组实现顺序栈,链表实现链式栈。
- 用栈实现:表达式求值
- 队头出队,队尾入队
- 顺序对列,链式队列
- 队满:(tail+1)% n = head;
- 队空: tail== head;
- 递归用循环代替
- 堆栈溢出,重复计算,空间度高,函数调用耗时多。
- 判断排序算法效率衡量:
- 1 时间复杂度(最好,最坏,平均)
- 2 时间复杂度,系数,常熟,低阶
- 3 内存消耗(原地排序)
- 4 稳定性(都为3,排序前后位置不变的就是稳定算法)
- 原地排序,稳定性
- 有序度,逆序度,满有序度 n*(n-1)/2
- 时间复杂度。 O(n*n)
- 优于冒泡
- 低于冒泡和插入
- 时间复杂度:都为 nlogn
- 空间负责度: n
- 取分区点,大于在右,小于在左。利用插入排序思想原地排序。
- 时间复杂度对数阶。
- 优化:三数取中,随机法取分区点。
- 分为多个桶,多个桶之间有排序,桶内快排
- 只适合数组
- 只适合有序
- 数据太小或太大都不适合
- 如何在100MB内存之内,在1000W数据中查找。(数组排序,二分查找)
- 二分查找变形:第一个小于等于某个值。。。
- 链表+多级索引+有序
- 空间复杂度 O(n)
- 查找的时间复杂度 O(logn)
- 插入删除时间复杂度 O(logn) 查找复杂度+操作复杂度
- 防止跳表退化成链表:通过随机数k,把1-k层添加索引
- 为什么不用红黑树? 查询在区间内的数时,跳表效率比红黑树高。
- 通过散列函数把元素的键值映射为下标,将数据存储在数组下标中
- 哈希冲突: 链表法;开放寻址法;重复哈希
-
- hash函数设计
-
- hash表初始大小,动态扩容,高效扩容先扩容,然后等插入数据时再拷贝数据到新的散列表
-
- 散列冲突链表法可以用红黑树替代;
- LRU缓存淘汰算法:散列表+双向链表;复杂度都是O(1)
- Redis有序集合:散列表+跳表 ;可以按照添加顺序 顺序访问
- 插入,删除,查找 时间复杂度可到O(1)
- 应用: 安全加密、唯一标识、数据校验、散列函数、负载均衡、数据分片、分布式存储
- hash环,算法对2的32次方取模。添加和删除机器只需要对部分数据迁移。
- 节点太少可以添加虚拟节点
- 高度/深度/层
- 存储方法:数组,链表;
- 完全二叉树用数组方式存储浪费的空间少。
- 前序遍历,中序遍历,后续遍历;用递归实现
- 遍历时间复杂度O(n)
- 插入,查找,删除(如果有两个子节点,找到右节点的最小值,替换。)
- 重复:链表法或数组动态扩容放在一个节点;放在右子树;
- 散列表无序
- hash表扩容,hash冲突时,性能不稳定
- 时间复杂度常量级不一定比对数级更优
- hash表考虑因素多。hash冲突,扩容缩容。
-
根节点是黑色的;
-
每个叶子节点都是黑色的空节点(NIL),也就是说,叶子节点不存数据
-
任何相邻的节点都不能同时为红色,也就是说,红色节点是被黑色节隔开。
-
每个节点,从该节点到达其可达叶子节点的所有路径,都包含相同数的黑色节点
-
平衡二叉查找树,任何节点都左右节点高度不大于1.
-
查找插入删除 时间复杂度:logn
-
插入3种调整方式,删除4种调整方式。
- 用来分析时间复杂度
- 完全二叉树
- 每个节点比它的子节点都大或是都小。大顶堆,小顶堆。
- 堆插入,删除 ,堆化的过程。
- 插入删除时间复杂度。logn
- 建堆,排序 。复杂度nlogn
- 堆排序,取最顶堆化再重复。
- 交换次数比快排多;跳跃访问。所以性能比快排低。
- 优先级队列、求 Top K 问题和求中位数问题
- 顶点,边,度,有向图,无向图,加权图。
- 邻阶矩阵存储。浪费空间。
- 邻阶表存储(可以把链表换成散列表,跳表,红黑树)
- 小规模(邻阶表+跳表实现)
- 大规模(hash分片之后用跳表;或数据库)
- 广度:地毯式搜索,一层一层向外搜索。
- 深度:回溯思想。
- 时间复杂度O(边数),空间复杂度O(顶点数)
- 把模式串和主串 hash,再比较hash值。
- 每个小串计算hash时不用遍历,有关系表达式。
- 坏字符原则
- 好后缀原则
- O(m+n)时间复杂度
- 字符串匹配算法
- 公共的前缀重合在一起,多叉树
- 多模式串匹配算法
- 类似在树结构上加了next数组
- 霍夫曼编码。根据字符串频率编码后再存储
- MapReduce实现思想就是多台机器分治
- 回退再试
- 时间复杂度 指数级
- 分多个阶段,取最后阶段就是最大重量。
- 思路:状态转移表;状态转移方程;
- 时间复杂度 线性级
- 有权有向图,放到优先级队列中。
- 应用:地图推荐最短路径
- 布隆过滤器:位图 + hash
- 应用:爬虫URL去重
- 应用:过滤垃圾短信
- 欧几里得距离
- 应用:推荐系统
- 应用:游戏寻路
- hash表:redis,memcache 适合hash表构建索引
- 红黑树:适合构建内存索引
- B+树:适合构建磁盘索引。mysql,oracle等数据库
- 跳表:redis有序集合
- list: 压缩列表+循环链表
- hash: 压缩列表+hash表
- set: 有序数组+hash表
- 有序集合: 压缩列表+ 跳表+hash表
- 搜索,分析,索引,查询
- 交替执行,叠加执行。
- 单处理系统中:进程切换&共享变量,中断可能会在进程中任何地方停止 引起并发问题!
- 多处理系统中:多进程,上述问题或 同时执行同时访问同一变量 都会引起并发问题!
- 多个进程,线程读写数据时,结果依赖多个进程的指令执行顺序。
- 竞争;共享;通信;
- 禁用中断(多处理器中无效);
- 专用机器指令
- 信号量
- 管程
- 消息传递
-
- OSI七层:物理层(IEEE 802.1A, IEEE 802.2到IEEE 802.11)、数据链路层(FDDI, Ethernet, Arpanet, PDN, SLIP, PPP)、网络层(IP, ICMP, ARP, RARP, AKP, UUCP)、传输层(TCP, UDP)、会话层(SMTP, DNS)、表示层(Telnet, Rlogin, SNMP, Gopher)、应用层(HTTP、TFTP, FTP, NFS, WAIS、SMTP)
- TCP/IP四层:数据链路层、网络层、传输层、应用层
-
《点对点 ,端到端》
- 端到端:针对传输层,发送端与接收端之间建立连接再发数据。
- 点到点:针对数据链路层或网络层,数据发给直接相连的设备。
-
- 链路层:对电信号进行分组并形成具有特定意义的数据帧,然后以广播的形式通过物理介质发送给接收方
- 网络层:(IP协议,ARP协议,路由协议)定义网络地址,区分网段,子网内MAC寻址,对于不同子网的数据包进行路由
- 传输层:定义端口,标识应用程序身份,实现端口到端口的通信,TCP协议可以保证数据传输的可靠性。
- 应用层:定义数据格式并按照对应的格式解读数据
-
《TCP三次握手,四次挥手》《TCP三次握手,四次挥手详解》
- URG 紧急指针是否有效。为1,表示某一位需要被优先处理。
- ACK 确认号是否有效,一般置为1。
- PSH 提示接收端应用程序立即从TCP缓冲区把数据读走。
- RST 对方要求重新建立连接,复位。
- SYN 请求建立连接,并在其序列号的字段进行序列号的初始值设定。建立连接,设置为1.
- FIN 希望断开连接。
- 三次握手: 1. SYN = 1,seq = j 2. SYN=1,ACK=1,ack= j+1,seq= k 3.ACK=1,ack=k+1
- 四次挥手: 1. FIN=m 2.ACK=m+1 3.FIN=n 4 ACK=1,ack=n+1
-
《HTTP协议详解,抓包分析》《HTTP2.0原理详解》《HTTP2.0二进制帧》
- HTTP2.0二进制桢
- HTTP2.0:多路复用、压缩头信息、请求划分优先级、支持服务器端主动推送
- HTTP1.0:每个请求都需单独建立连接(keep-alive能解决部分问题单不能交叉推送)、每个请求和响应都需要完整的头信息、数据未加密
-
-
- 浏览器发送HTTPS请求 2 服务器发送数字证书给客户端 3 浏览器CA列表验证证书 4 浏览器产生对称密钥,用公钥加密 5 用私钥揭秘获得对称密钥 6 用对称密钥加密通信。
-
- 《web优化必须了解的原理之I/o的五种模型和web的三种工作模式》
- I/O步骤:进程向操作系统请求数据 ;操作系统把外部数据加载到内核的缓冲区中;操作系统把内核的缓冲区拷贝到进程的缓冲区 ;进程获得数据完成自己的功能 ;
- 五种I/O模型:阻塞I/O,非阻塞I/O,I/O复用、事件(信号)驱动I/O、异步I/O,前四种I/O属于同步操作,I/O的第一阶段不同、第二阶段相同,最后的一种则属于异步操作。
- 三种 Web Server 工作方式:Prefork(多进程)、Worker方式(线程方式)、Event方式。
- 《一文读懂I/O复用》
- 第一阶段select阻塞,第二阶段recvfrom阻塞
- 《select、poll、epoll之间的区别总结[整理]》《select、poll、epoll区别》《epoll使用详解》
- 每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大
- 同时每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大
- select支持的文件描述符数量太小了,默认是1024
- 《长连接短链接》
- 《设计模式的六大原则》
- 开闭原则:对扩展开放,对修改关闭,多使用抽象类和接口。
- 里氏替换原则:基类可以被子类替换,使用抽象类继承,不使用具体类继承。
- 依赖倒转原则:要依赖于抽象,不要依赖于具体,针对接口编程,不针对实现编程。
- 接口隔离原则:使用多个隔离的接口,比使用单个接口好,建立最小的接口。
- 迪米特法则:一个软件实体应当尽可能少地与其他实体发生相互作用,通过中间类建立联系。
- 合成复用原则:尽量使用合成/聚合,而不是使用继承。
- 《23种设计模式》
- 《23种设计模式全解析》
- 《23种设计模式类图和示例》
TODO
-
- 进程模型:一个master进程,管理多个worker进程。一个请求只能一个worker进程处理。worker进程抢acceptMutex锁,然后接受请求,处理请求,返回请求,断开连接
- 事件模型:高并发,异步非阻塞事件机制(例如epoll,循环处理准备好的事件请求,IO事件没有准备好就放回epoll)。
- connection: TCP三次握手
- request: 请求行、请求头、请求体、响应行、响应头、响应体
-
《nginx配置》
-
- DNS域名解析;TCP连接;接受请求;处理请求;返回响应;关闭TCP;记录日志;解析HTML展示页面;
-
《apache与nginx原理详解及对比》《apache原理》《apache与nginx对比及优缺点》
- apache一个子进程处理一个请求。nginx一个子进程通过异步非阻塞事件模型可以处理多个请求,所以并发能力强。
- nginx轻量级,占用资源少。反向代理负载均衡。
- apache模块丰富
-
- perfork MPM多个进程,无线程设计,每个进程处理一个请求。worker MPM一个进程下有多个线程。每个线程处理一个请求。
-
- nginx处理静态请求,apache处理动态请求
- 《浅谈OpenResty》 《官方网站》
- 通过lua模块在nginx上开发。黑名单,防刷,限流等
- 《openResty作者agentzh的Nginx教程》
- 《跟着开涛学openResty》
- TODO 《亿级流量网站》
- 《Memcached 教程》
- 《深入理解Memcached原理》
- 《Memcached工作原理》
- 《Memcache技术分享:介绍、使用、存储、算法、优化、命中率》
- 《memcache 中 add 、 set 、replace 的区别》
- 《Redis 教程》
- 《redis底层原理》
- 《Redis持久化》
- RDB方式:定期备份快照,常用于灾难恢复。优点:通过fork出的进程进行备份,不影响主进程、RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。缺点:会丢数据。
- AOF方式:保存操作日志方式。优点:恢复时数据丢失少,缺点:文件大,回复慢。
- 也可以两者结合使用。
- 《分布式缓存--序列3--原子操作与CAS乐观锁》
- 《Redis单线程架构》
- 《redis的回收策略》
- 《tair源码》
- 《tair与redis比较总结》
- 《消息队列简介及好处》
- 提高系统响应速度、提高系统稳定性、异步化、解耦、消除峰值
- 《Kafka、RabbitMQ、RocketMQ等消息中间件的对比 —— 消息发送性能和区别》
- Push方式:优点是可以尽可能快地将消息发送给消费者,缺点是如果消费者处理能力跟不上,消费者的缓冲区可能会溢出。 RabbitMQ 消费者默认是推模式(也支持拉模式)。
- Pull方式:优点是消费端可以按处理能力进行拉去,缺点是会增加消息延迟。 Kafka 默认是拉模式。
- 《消息顺序和重复问题》
- 《RabbitMQ应用场景以及基本原理介绍》《消息队列之 RabbitMQ》- 《RabbitMQ之消息确认机制(事务+Confirm)》
- 支持事务,推拉模式都是支持、适合需要可靠性消息传输的场景。
- 《RocketMQ 实战之快速入门》《RocketMQ源码分析》
- Java实现,推拉模式都是支持,吞吐量逊于Kafka。可以保证消息顺序。
- 《ActiveMQ消息队列介绍》
- 纯Java实现,兼容JMS,可以内嵌于Java应用中。
- 《Kafka深度解析,众人推荐,精彩好文》《Kafka分区机制介绍与示例》
- 高吞吐量、采用拉模式。适合高IO场景,比如日志同步。
- 《Redis用作消息队列》
- 生产者、消费者模式完全是客户端行为,list 和 拉模式实现,阻塞等待采用 blpop 指令。
请求转发、安全认证、协议转换、容灾
- 《三大范式五大约束》
- 《事务隔离级别》
- 《数据库事务特性》
- 《数据库事务隔离级别》
- 《InnoDB幻读问题》
- 原子性,一致性,隔离性,持久性
- 读不提交,出现脏读
- 读提交,出现不可重复读
- 重复读,出现幻读
- 序列化,--
- 连接层,优化/缓存层,存储引擎
- frm文件表空间描述
- ibd文件索引和数据
- page页:头双向链表,body链表存储记录
- 索引:B+树
- 《索引原理》
- 聚族索引与非聚簇索引
- B+树,非叶子结点不存数据,只存索引键值,叶子结点存数据。
- 聚族索引与非聚簇索引
- 单列索引
- 索引覆盖
- 组合索引,索引合并
- 全文索引
-
1.在经常需要搜索的列上,可以加快索引的速度
-
2.主键列上可以确保列的唯一性
-
3.在表与表的而连接条件上加上索引,可以加快连接查询的速度
-
4.在经常需要排序(order by),分组(group by)和的distinct 列上加索引 可以加快排序查询的时间, (单独order by 用不了索引,索引考虑加where 或加limit)
-
5.在一些where 之后的 < <= > >= BETWEEN IN 以及某个情况下的like 建立字段的索引(B-TREE)
-
6.like语句的 如果你对nickname字段建立了一个索引.当查询的时候的语句是 nickname lick '%ABC%' 那么这个索引讲不会起到作用.而nickname lick 'ABC%' 那么将可以用到索引
-
7.索引不会包含NULL列,如果列中包含NULL值都将不会被包含在索引中,复合索引中如果有一列含有NULL值那么这个组合索引都将失效,一般需要给默认值0或者 ' '字符串
-
8.使用短索引,如果你的一个字段是Char(32)或者int(32),在创建索引的时候指定前缀长度 比如前10个字符 (前提是多数值是唯一的..)那么短索引可以提高查询速度,并且可以减少磁盘的空间,也可以减少I/0操作.
-
9.不要在列上进行运算,这样会使得mysql索引失效,也会进行全表扫描
-
10.选择越小的数据类型越好,因为通常越小的数据类型通常在磁盘,内存,cpu,缓存中 占用的空间很少,处理起来更快
-
尽量选择区分度高的列作索引
- 索引列 like "%xx"
- 使用函数计算
- or 有没有索引的列
- 类型不一致
- order by 查询的列不是主键排序就不走索引
- 《explain分析SQL》
- select_type:simple,primary,subquery,derived,union,union result
- type:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
-
《为什么需要并发?》
- 充分利用多核CPU的计算能力
- 业务拆分,提升性能
-
- 并发:通过切换时间片的方式多个任务交替进行;并行:真正意义上的“同时进行”
-
- 硬件,网络,架构设计(各种分布式,缓存,中间件,异步),开发语言,数据结构,算法,数据库优化,代码层(多线程编程,同步异步)
- 《高并发实现中一种方式:多线程开发及优缺点》
- 优点:耗时任务放入子线程防止阻塞,提升响应速度;充分利用CPU,提高性能;改善程序结构;
- 缺点:频繁切换上下文;线程安全问题;
- 《线程安全问题及解决方案》
- 产生原因:CPU切换时间片执行多线程产生竞态条件
- 原子性,可见性,时序性;原子性:要么都执行,要么都不执行。a++是先查,后加,不是原子操作。
- 加锁
- 《锁的分类》
- 乐观锁&悲观锁,互斥锁/写锁,共享锁/读锁,公平锁/非公平锁,重入锁/非重入锁,分段锁等。
- 《悲观锁与乐观锁》
- select for update
-
《乐观锁》
- 是一种思想,提交更新时对冲突检测,让用户决定重试或是其他。
- ABA问题,解决方法对每次更新加上版本号
-
《对mysql乐观锁、悲观锁、共享锁、排它锁、行锁、表锁概念的理解》
- 对于update,insert,delete语句会自动加排它锁,只共享读。
-
《select.. for update导致的数据库死锁分析》
- mysql的innodb存储引擎实务锁虽然是锁行,但它内部是锁索引的。
- 锁相同数据的不同索引条件可能会引起死锁。
- 《15天的性能优化工作,5方面的调优经验》
- 代码层面、业务层面、数据库层面、服务器层面、前端优化。
- 《系统优化的几个方面》
- 《互联网架构,如何进行容量设计?》
- 总访问量,平均访问量,高峰QPS,压测获取单机极限QPS,机器配置。
- 《互联网性能与容量评估的方法论和典型案例》
- 《搭建简易堡垒机》
- 《邪恶的JAVA HASH DOS攻击》
- 利用JsonObject 上传大Json,JsonObject 底层使用HashMap;不同的数据产生相同的hash值,使得构建Hash速度变慢,耗尽CPU。
- 《一种高级的DoS攻击-Hash碰撞攻击》
- 《关于Hash Collision DoS漏洞:解析与解决方案》
-
- 滑动验证码是根据人在滑动滑块的响应时间,拖拽速度,时间,位置,轨迹,重试次数等来评估风险。
- 用户密码非明文保存,加动态salt。
- 身份证号,手机号如果要显示,用 “*” 替代部分字符。
- 联系方式在的显示与否由用户自己控制。
- TODO
- 《常见对称加密算法》
- DES、3DES、Blowfish、AES
- DES 采用 56位秘钥,Blowfish 采用1到448位变长秘钥,AES 128,192和256位长度的秘钥。
- DES 秘钥太短(只有56位)算法目前已经被 AES 取代,并且 AES 有硬件加速,性能很好。
-
- MD5 和 SHA-1 已经不再安全,已被弃用。
- 目前 SHA-256 是比较安全的。
- 《常见非对称加密算法》
-
RSA、DSA、ECDSA(螺旋曲线加密算法)
-
和 RSA 不同的是 DSA 仅能用于数字签名,不能进行数据加密解密,其安全性和RSA相当,但其性能要比RSA快。
-
256位的ECC秘钥的安全性等同于3072位的RSA秘钥。
-
TODO
TODO
在内外环境中通过跳板机登录到线上主机。
2FA - Two-factor authentication,用于加强登录验证
常用做法是 登录密码 + 手机验证码(或者令牌Key,类似于与网银的 USB key)
- 【《双因素认证(2FA)教程》】(http://www.ruanyifeng.com/blog/2017/11/2fa-tutorial.html)
- 《【分享】腾讯业务系统监控的修炼之路》
- 监控的方式:主动、被动、旁路(比如舆情监控)
- 监控类型: 基础监控、服务端监控、客户端监控、 监控、用户端监控
- 监控的目标:全、快、准
- 核心指标:请求量、成功率、耗时
- 《开源还是商用?十大云运维监控工具横评》
- Zabbix、Nagios、Ganglia、Zenoss、Open-falcon、监控宝、 360网站服务监控、阿里云监控、百度云观测、小蜜蜂网站监测等。
- 《监控报警系统搭建及二次开发经验》
- 《ELKB日志收集系统搭建》《ELK日志收集系统搭建》《日志收集系统》
- Beats日志搬运工。安装在每台需要收集日志的服务器上,将日志发送给Logstash进行处理。Filebeat配置安装
- LogStash把没条日志解析成每个字段LogStash配置安装
- ElasticSearch全文搜索日志 ElasticSearch全文搜索引擎《索引搜索查询及增删改查》《ElasticSearch权威指南》
- Kibana是ElasticSearch全文搜索图形化界面 Kibana安装
- 《FileBeat+kafka进行日志实时传输》
- kafka教程
- logrotate日志切割
- 《RPC概述》
- 远程调用程序并返回
- 《分布式RPC框架性能大比拼dubbo、motan、rpcx、gRPC、thrift的性能比较》
- 《Dubbo官网》《Dubbo实现原理简单介绍》
- 《Thrift官网》《Thrift详解》
- 《Grpc官网》《RPC原理介绍》
- 《几张图帮你理解 docker 基本原理及快速入门》
- 镜像,容器。一个镜像可以建立多个容器,一个容器最多127层。
- 《docker核心技术与实现》
- 《docker教程》
- 项目实例
- TODO
- 《持续集成是什么?》
- 合并;交付;测试;部署;
- 《8个流行的持续集成工具》
- 《使用Jenkins进行持续集成》
- 《Ansible基础配置和企业级项目实用案例》
- 批量系统配置、批量程序部署、批量运行命令等功能
- 《Ansible中文权威指南》
- 《自动化运维工具——puppet详解(一)》
- 《Chef 的安装与使用》
- 《VPS的三种虚拟技术OpenVZ、Xen、KVM优缺点比较》
- 《KVM详解,太详细太深入了,经典》
- 《KVM 虚拟机安装详解》
- 《Xen虚拟化基本原理详解》
- 《开源Linux容器 OpenVZ 快速上手指南》
-
- too many open files (解决方案:ulimit -n; nginx配置events同级 worker_rlimit_nofile 15360;)
- apr_socket_recv:Operation timed out (解决方法:ab加上-k 开启keepAlive)
- apr_socket_connect(): Operation already in progress (解决方法:apache/conf/extra/httpd-mpm.conf 修改 ThreadsPerChild)
- apr_socket_recv: Connection reset by peer (54)
- setsockopt(TCP_NODELAY) failed (22: Invalid argument) while keepalive
-
- jmeter
- 《全链路压测》
- 资源服务监控《20个命令行工具监控》
- 《单元测试》
- 单元测试可以有效地测试某个程序模块的行为,是未来重构代码的信心保证。
- 单元测试的测试用例要覆盖常用的输入组合、边界条件和异常。
- 单元测试代码要非常简单,如果测试代码太复杂,那么测试代码本身就可能有bug。
- 单元测试通过了并不意味着程序就没有bug了,但是不通过程序肯定有bug。
- 《简单说明CGI和动态请求是什么》
- CGI,fastCGI
- php-cgi,php-fpm
- web-server,php-fpm,zend引擎,CGI脚本
- 《架构师技能修炼图》
- 《微服务架构设计》《微服务架构选型》
- API网关,RESTFUL,微服务
- 《RESTFUL API架构》
- 《API网关》
- kong
- 项目实例
- TODO
- 《说说如何实现可扩展性的大型网站架构》
- 分布式+异步任务
- 分布式要求:负载均衡,失效转移,高效远程调用,整合异构系统,版本控制,实时监控
- 《可扩展性设计之数据切分》
- 垂直切分,水平切分,联合切分
- 垂直切分缺点: join表分页搜索需要程序完成;事务处理复杂;
- 水平切分缺点: 维护数据变复杂;切分无具体标准;
- 切分与整合带来的问题:分布式事务;跨节点join(全局表,冗余,数据组装);跨节点合并分页排序(先排序分页,再数据组装);
- 《分布式事务一致性问题》《分库分表事务一致性》《保证分布式系统数据一致性的6种方案》
- 提供回滚接口
- 《本地消息表》
- 非事务MQ
- 事务MQ
-
- 可扩展:水平扩展、垂直扩展。 通过冗余部署,避免单点故障。一主多从。
- 隔离:避免单一业务占用全部资源。避免业务之间的相互影响 2. 机房隔离避免单点故障。
- 解耦:降低维护成本,降低耦合风险。减少依赖,减少相互间的影响。
- 限流:遇到突发流量时,保证系统稳定。
- 降级:紧急情况下释放非核心功能的资源。牺牲非核心业务,保证核心业务的高可用。
- 熔断:异常情况超出阈值进入熔断状态,快速失败。减少不稳定的外部依赖对核心服务的影响。
- 自动化测试:通过完善的测试,减少发布引起的故障。
- 灰度发布:灰度发布是速度与安全性作为妥协,能够有效减少发布故障。
-
《关于高可用的系统》
- 数据不丢,就必需要持久化;服务高可用,就必需要有备用;复制,就会有数据一致性
- 《软/硬件负载均衡产品 你知多少?》《转!!负载均衡器技术Nginx和F5的优缺点对比》
- 硬件,软件负载均衡
- 《负载均衡的几种算法》
- 轮流;比例;优先权; 最小连接;响应最快;服务器性能模式;观察模式 请求数响应时间;
- 《DNS做负载均衡》
- 配置简单;生效慢。
- 《NGINX做负载均衡》
- 成本低。主要适用web应用。
- 《借助LVS+Keepalived实现负载均衡》
- 支持到OSI四层,性能较高
- 《HAProxy用法详解 全网最详细中文文档》《Haproxy+Keepalived+MySQL实现读均衡负载》《rabbitmq+haproxy+keepalived实现高可用集群搭建》
- HAProxy性能和LVS差不多。
- 《谈谈高并发系统的限流》
- 计数器:通过滑动窗口计数器,控制单位时间内的请求次数,简单粗暴。
- 漏桶算法:固定容量的漏桶,漏桶满了就丢弃请求,比较常用。
- 令牌桶算法:固定容量的令牌桶,按照一定速率添加令牌,处理请求前需要拿到令牌,拿不到令牌则丢弃请求,或进入丢队列,可以通过控制添加令牌的速率,来控制整体速度。Guava 中的 RateLimiter 是令牌桶的实现。
- Nginx 限流:通过 limit_req 等模块限制并发连接数。
-
- 雪崩效应原因:硬件故障、程序Bug、缓存击穿、用户大量请求。
- 雪崩的对策:限流、改进缓存模式(缓存预加载、同步调用改异步)、自动扩容、降级。
- Hystrix设计原则:
- 资源隔离:Hystrix通过将每个依赖服务分配独立的线程池进行资源隔离, 从而避免服务雪崩。
- 熔断开关:服务的健康状况 = 请求失败数 / 请求总数,通过阈值设定和滑动窗口控制开关。
- 命令模式:通过继承 HystrixCommand 来包装服务调用逻辑。
-
- 主要策略:失效瞬间:单机使用锁;使用分布式锁;不过期;
- 热点数据:热点数据单独存储;使用本地缓存;分成多个子key;
-
《“异地多活”多机房部署经验谈》《异地多活(异地双活)实践经验》《依赖治理、灰度发布、故障演练,阿里电商故障演练系统的设计与实战经验》
-
《【大型网站技术实践】初级篇:搭建MySQL主从复制经典架构》《MySQL主从复制(Master-Slave)实践》
- 一主n从;自动同步数据。
- 《永不失联!如何实现微服务架构中的服务发现》
- 客户端服务发现模式:客户端直接查询注册表,同时自己负责负载均衡。Eureka 采用这种方式。
- 服务器端服务发现模式:客户端通过负载均衡查询服务实例。
- 《SpringCloud服务注册中心比较:Consul vs Zookeeper vs Etcd vs Eureka》
- 《基于Zookeeper的服务注册与发现》
- 《从分布式一致性谈到CAP理论、BASE理论》
- 一致性分类:强一致(立即一致);弱一致(可在单位时间内实现一致,比如秒级);最终一致(弱一致的一种,一定时间内最终一致)
- CAP:一致性、可用性、分区容错性(网络故障引起)
- BASE:Basically Available(基本可用)、Soft state(软状态)和Eventually consistent(最终一致性)
- BASE理论的核心思想是:即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。
- 《分布式锁的几种实现方式~》
- 数据库;缓存;zookeeper;
- 《基于Zookeeper的分布式锁》
- 《jedisLock—redis分布式锁实现》
- 利用setnx
- 《Memcached 和 Redis 分布式锁方案》
- 利用 memcached 的 add(有别于set)操作,当key存在时,返回false。
例如:
- 广告相关实时统计;
- 推荐系统用户画像标签实时更新;
- 线上服务健康状况实时监测;
- 实时榜单;
- 实时数据统计。
- GOROOT,GOPATH,GOBIN
- src,bin,pkg
- go build; go install ; go get;
- 如果一个源码文件声明属于main包,并且包含一个无参数声明且无结果声明的main函数,那么它就是命令源码文件
- 库源码文件是不能被直接运行的源码文件,它仅用于存放程序实体,这些程序实体可以被其他代码使用
- internal
- 函数导出,访问权限
- var s string
- s := "name"
- 短变量声明
- 包级私有的、模块级私有的和公开的
- 在无需扩容时,append函数返回的是指向原底层数组的新切片,而在需要扩容时,append函数返回的是指向新底层数组的新切片。
- slice扩容 2倍,1.25倍。
- 底层数组不会被替换,直接生产新的数组
- container/list
- 通道不能一直阻塞
- goroutine执行完再退出
- goroutine泄漏
- channel关闭
- goroutine不能打开太多,应该有限制
- 对于同一个通道,发送操作之间是互斥的,接收操作之间也是互斥的
- 发送操作和接收操作中对元素值的处理都是不可分割的
- 发送操作在完全完成之前会被阻塞。接收操作也是如此
- Channels的发送操作将导致发送者goroutine阻塞,直到另一个goroutine在相同的Channels上执行接收操作
- 接收操作先发生,那么接收者goroutine也将阻塞,直到有另一个goroutine在相同的Channels上执行发送操作
- 当一个channel被关闭后,再向该channel发送数据将导致panic异常
- 当一个被关闭的channel中已经发送的数据都被成功接收后,后续的接收操作将不再阻塞,它们会立即返回一个零值
- 只需要关闭接受者goroutine
- range是安全接收的,它会判断是否关闭且没有收据接收。
- 只有在发送者所在的goroutine才会调用close函数
- 任何双向channel向单向channel变量的赋值操作都将导致该隐式转换,没有反向转换的语法
- 内部缓存队列是满的,那么发送操作将阻塞直到因另一个goroutine执行接收操作
- channel是空的,接收操作将阻塞直到有另一个goroutine执行发送操作而向队列插入元素。
- 可以保证go程执行完再退出(??)
- 循环时显式的将参数传给go程。
- wg.wait为什么要在go func(){}中
- for range channel当channel关闭且流干的时候才退出循环
- 同时都满足条件,会随机选择一个执行。是不是有bug
- Loop goto break
- 通过close广播,select去接收。
- 数据竞争会在两个以上的goroutine并发访问相同的变量且至少其中一个为写操作时发生。
- 三种方法避免数据竞争:不要去写变量;避免从多个goroutine访问变量;加锁;
- sync.Mutex互斥锁
- sync.RMutex读写锁
- 内存同步
- 不使用channel且不使用mutex这样的显式同步操作时,我们就没法保证事件在不同的goroutine中看到的执行顺序是一致的
- sync.once
- 保证loadIcons的变量能够对所有goroutine可见
- close(ch)会广播到每个goroutine
- 两种方式:加锁;channel ;
TODO
- 软件,硬件
- 系统软件;应用软件
- 汇编--机器语言-解释操作系统-微程序解释机器语言-执行机器语言
- 翻译程序两种:编译程序;解释程序;
- 运算器,存储器,控制器,输入输出
- 指令和数据相同地位存放在存储器,可按地址寻访。
- 指令和数据由二进制码表示
- 指令由操作码和地址码组成
- 指令是顺序存放的
- 以运算器为中心
- 现代计算机:MM+CPU+IO
- 数学建模;确定计算方法;编程序
- 控制器,存储器,运算器,输入,输出设备
TODO
- 计算机组成原理
- 编译原理和技术
- 操作系统原理与设计
- 数据结构算法基础
- 计算机组成原理实验
- 数据库系统及应用
- 并行计算
- 软件工程
- 计算机导论
- 计算机网络