tn是desert(沙漠之鹰)和tan共同开发的一种用于匹配,转写和抽取文本的语言(DSL)。并为其开发和优化了专用的编译器。基于递归下降方法和正则表达式,能解析自然文本并转换为树和字典,识别时间,地址,数量等复杂序列模式。 github地址:https://github.com/ferventdesert/tnpy
语法介绍
字符串分析和处理几乎是每个员程序必备的工作,简单到分割类似"1,2,3,4"这样的字符串,稍微复杂一些如字符串匹配,再复杂如编译和分析SQL语法。字符串几乎具有无穷的表达能力,解决字符串问题,就解决了计算机90%的问题。
虽然字符串处理如此深入人心,但当分割字符时,本来都是按照逗号分割的,突然出现分号,程序就可能出错。再如日期处理,每个程序员肯定都对各种奇怪诡异的时间表达方式感到头疼,处理起来非常费时。这些功能,几乎只能以硬编码实现。它们是与外界交互的最底层模块,然而却如此脆弱。
- 如何将”一百二十三“转换为数字?
- 如何将”2013年12月14日“识别为时间并转换为时 间类型?
- 如何分析一个XML或JSON文件?
正则表达式虽提供了强大的匹配功能,成为必备的工具,但它有不少局限,我们扩展了正则表达式引擎,使之能力大大增强。 在线演示:http://www.desertlambda.com:81/extracttext.html
基本上程序员都读过“30分钟学会正则表达式”这篇文章吧?最后没几个人能在30分钟内就读完它。不过相信我,TN引擎只需要15分钟就可以学会。
详细的语法说明在这里:
TN可以实现文本的匹配,转写和信息抽取,可以理解为模板引擎的逆运算。简单的操作用正则表达式更方便,但不少问题是正则无法解决的。这时就需要使用TN了。
TN的解释器有Python,C#和C三种版本。C#版本已经不再维护。使用C#或Java等语言的,建议使用IronPython或Jython进行跨语言编译。
tnpy是tn的Python解释器,Python良好的可读性让代码写起来非常方便,代码不超过1000行,单文件,无第三方库依赖。推荐使用Python3。
tn是解释型语言,需要编写规则文件,并使用tnpy加载,再对文本进行处理。
首先我们先编写一个最简单的规则文件learn,内容如下:
#%Order% 1
hello= ("你好");
接着,执行下面的python代码:
from src.tnpy import RegexCore
core = RegexCore('../rules/learn')
matchs=core.Match('领导你好!老婆你好');
for m in matchs:
print('match',m.mstr, 'pos:',m.pos)
引入tnpy命名空间,之后从learn规则文件初始化引擎,匹配该文本:
success load tn rules:../rules/learn
match 你好 pos: 2
match 你好 pos: 7
上面输出了文本的匹配结果和位置。当然这一点正则也能做到。
如果我们匹配的是领导你好,老婆您好,并想把所有的你好和您好,都转写为hello。
为此我们添加hello2和hello3两个子规则:
hello2= $(hello)| ("您好");
#%Order% 1
hello3= $(hello2) : (//:/hello/);
hello2引用了刚才的hello规则,同时添加了“您好”。
hello3是主规则,负责将将hello2匹配的内容都转写为hello
($代表引用一条规则,|表示将几个规则并列排列,匹配最长的那个规则,:代表转写。)
执行下面的代码:`
print(core.Rewrite('领导你好!老婆您好'));
结果为:
领导hello!老婆hello
如果我们想替换顺序,把“你好”放在前面呢?可以这样写:
people= ("老婆") | ("领导");
#%Order% 1
reorder= $(people) $(hello3) : $2 $1;
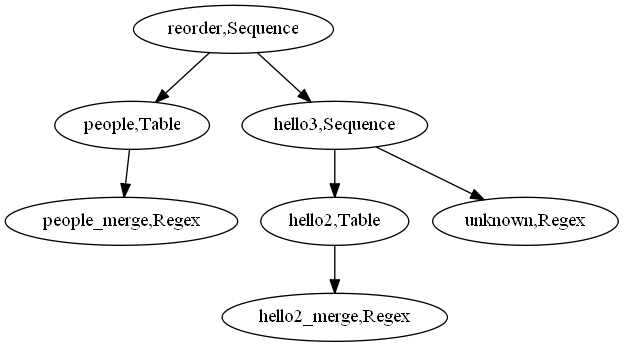
先用people定义如何描述老婆,领导,然后用reorder来修改顺序, 注意reorder是个顺序结构,people匹配老婆和领导,hello3匹配您好/你好,并将其转换为hello。 $2和$1修改了转写顺序,执行Rewrite后输出:
hello领导!hello老婆
我们把类似$(name1) $(name2)的结构,称为顺序表达式,把$(name1) | $(name2) 称为或表达式。
如果将刚才所有的规则绘制成图,则是下面的样子:
仅仅使用文本,表现力太差了。我们引入正则表达式来完成,正则表达式需要放在(//)中,注意和文本("")的区别。
如果要进行转写,则标注为(/match/:/rewrite/); 下面的表达式将所有的长空白符转换为一个空白符:
byte_det_space = (/ */://);
下面将所有字母转换为空白:
low_letter_to_null = (/[a-z]/ ://);
#或者下面:
low_letter= (/[a-z]/);
translate= $(low_letter) : ("");
觉得没有挑战?我们接着看下面的。
二十三如何转换为23?这种用普通的编程会比较困难。我们尝试用TN解决,会发现一点都不难。 先定义汉字的一二三到九转换为1-9,你肯定会写出这样的规则:
#定义0-9
int_1 = ("一" : "1");
int_0 =("零" : "0");
int_2 = ("二" : "2") | ("两" : "2");
int_3_9 = ("三" : "3") | ("四" : "4") | ("五" : "5") | ("六" : "6") | ("七" : "7") | ("八" : "8") | ("九" : "9");
int_1_9 = $(int_1) | $(int_2) | $(int_3_9) | (/\d/);
int_0_9 = $(int_0) | $(int_1_9);
int_del_0 = (/零/ : /0/) | (// : /0/);
int_0_9_null = $(int_del_0) | $(int_0_9);
之所以要把0,1,2分开写,是因为这些数有特殊情况,如两和二都代表2,需要在后面特殊处理。
上面的int_0_9_null规则,就可以把五七零二转写为5702。但没法处理二十三这样的情况。
再定义下面的规则,这样一十三可以转写为13
int_del_0 = (/零/ : /0/) | (// : /0/);
int_0_9_null = $(int_del_0) | $(int_0_9);
#定义10,十
int_1_decades = (/十/ : /1/) | (/一十/ : /1/);
再加上下面的规则,int_1_9_decades定义了十位数如何转写,而int_10_99定义了从十到九十九的转写规则。
int_10_99 = $(int_1_9_decades) $(int_0_9_null) | (/[1-9][0-9]/) ;
int_1_99 = $(int_1_9) | $(int_10_99) ;
int_01_99 = $(int_1_9) | $(int_10_99) | (/\d{1,2}/);
#%Order% 3
int_0_99 = $(int_0) | $(int_1_9) | $(int_10_99);
看看下面的例子:
print({r:core.Rewrite(r) for r in ['十','三十七','一十三','68']});
运行结果:
{'一十三': '13', '68': '68', '十': '10', '三十七': '37'}
是不是感到很神奇?三十七是如何被转写为37的?
仔细看规则,规则自底向上构造成了一棵规则树,in_0_99是整棵树的根节点。结构如下图:
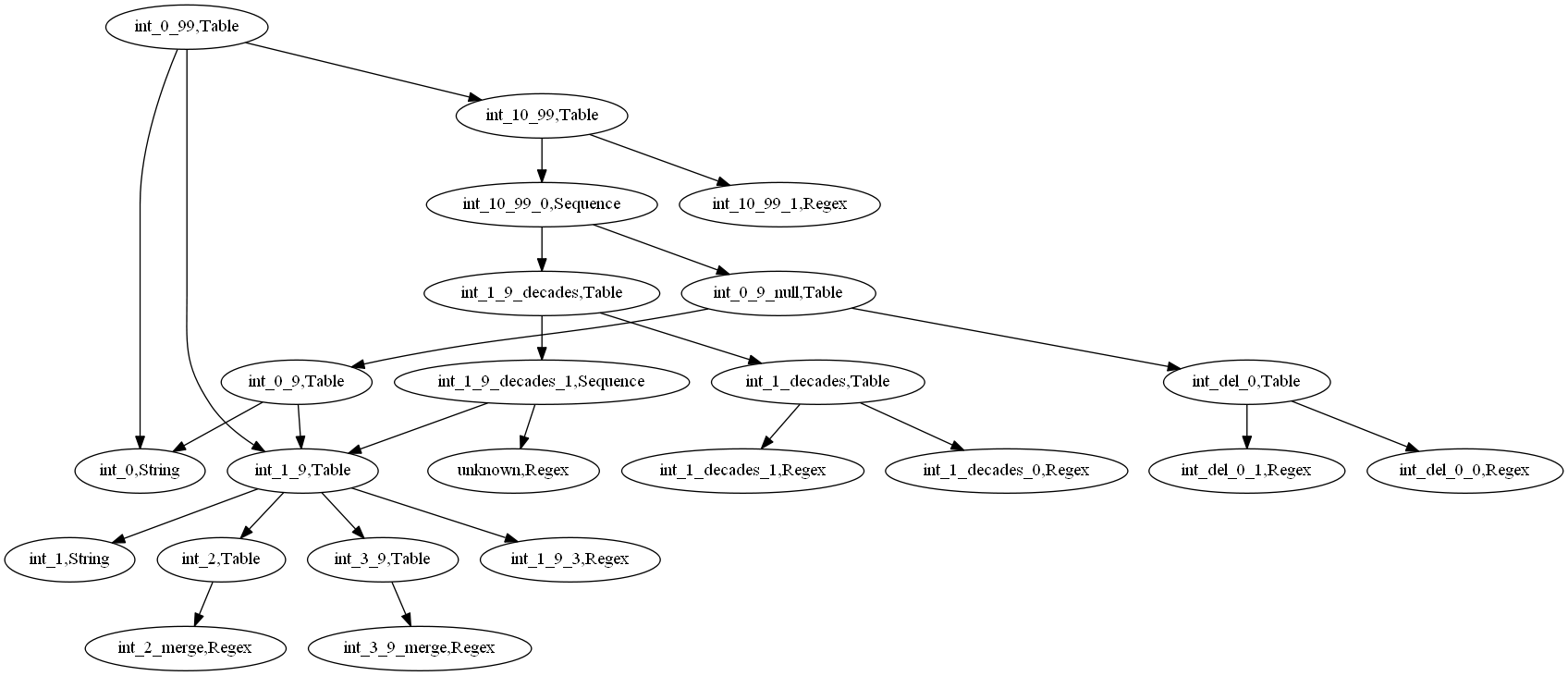
int_0_99,Table,Raw =三十七
int_0,String,Raw =三十七
int_0,String,NG
int_1_9,Table,Raw =三十七
int_1,String,Raw =三十七
int_1,String,NG
int_2,Table,Raw =三十七
int_2_merge,Regex,Raw =三十七
int_2_merge,Regex,NG
int_2,Table,NG
int_3_9,Table,Raw =三十七
int_3_9_merge,Regex,Raw =三十七
int_3_9_merge,Regex,Match=三
int_3_9,Table,Match=三
int_1_9_3,Regex,Raw =三十七
int_1_9_3,Regex,NG
int_1_9,Table,Match=三
int_10_99,Table,Raw =三十七
int_10_99_0,Sequence,Raw =三十七
int_1_9_decades,Table,Raw =三十七
int_1_decades,Table,Raw =三十七
int_1_decades_0,Regex,Raw =三十七
int_1_decades_0,Regex,Match=十
int_1_decades_1,Regex,Raw =三十七
int_1_decades_1,Regex,NG
int_1_decades,Table,Match=十
int_1_9_decades_1,Sequence,Raw =三十七
int_1_9,Table,Raw =三十七
int_1_9,Table,Buff =三
unknown,Regex,Raw =十七
unknown,Regex,Match=十
int_1_9_decades_1,Sequence,Match=三十
int_1_9_decades,Table,Match=三十
int_0_9_null,Table,Raw =七
int_del_0,Table,Raw =七
int_del_0_0,Regex,Raw =七
int_del_0_0,Regex,NG
int_del_0_1,Regex,Raw =七
int_del_0_1,Regex,Match=
int_del_0,Table,Match=
int_0_9,Table,Raw =七
int_0,String,Raw =七
int_0,String,NG
int_1_9,Table,Raw =七
int_1,String,Raw =七
int_1,String,NG
int_2,Table,Raw =七
int_2_merge,Regex,Raw =七
int_2_merge,Regex,NG
int_2,Table,NG
int_3_9,Table,Raw =七
int_3_9_merge,Regex,Raw =七
int_3_9_merge,Regex,Match=七
int_3_9,Table,Match=七
int_1_9_3,Regex,Raw =七
int_1_9_3,Regex,NG
int_1_9,Table,Match=七
int_0_9,Table,Match=七
int_0_9_null,Table,Match=七
int_10_99_0,Sequence,Match=三十七
int_10_99_1,Regex,Raw =三十七
int_10_99_1,Regex,NG
int_10_99,Table,Match=三十七
int_0_99,Table,Match=三十七
引擎从文本的左向右,沿着规则树寻找最长的文本,如果在一个顺序表达式上的任何一步失败,那么整个顺序表达式被抛弃。或表达式会遍历每个子表达式,直到发现最长的那个,返回结果。具体的匹配原理,以及优化,会在专门的文章中介绍。
自然而然的,知道怎么定义三十七,就可以定义五百三十七,那不过是int_1_9_hundreds+int_0_99(这个已经定义过了)。
int_1_9_hundreds = $(int_1_9) ("百" : "");
int_100_999 = $(int_1_9_hundreds) ("" : "00") | $(int_1_9_hundreds) $(int_10_99);
int_1_999 = $(int_1_99) | $(int_100_999);
int_1_999可以处理类似五百三十七这样的问题!
进而,我们可以处理几千,几万,这个延伸到万以后,就可以自然而然地衍生出亿,万亿的表达。
如何处理负数?这还不简单!
signed_symbol0 = ("正" : "") | ("负" : "-") | ("正负" : "±") | ("\+" : "+") | ("\-" : "-") | ("±" : "±") ;
signed_symbol = $(signed_symbol0) | $(null_2_null);
接下来,我们默认正整数为integer_int,那么,整数(包含正负)就是:
integer_signed = $(signed_symbol) $(integer_int)
沿着刚才的路,我们自然而然地能定义分数,但仅仅是转写还不够,遇到三分之一,我们不仅要将其处理为1/3,还要计算出它的值,这就涉及到属性抽取。也就是把信息从文本中提取为字典。
分数,不过是整数+分之+整数,可以定义成下面的形式:
fraction_cnv_slash = ("分之" : "/");
fraction2 = ("/" : "/");
percent_transform= ("%" : "100") | ("‰" : "1000");
#%Type% DOUBLE
#%Property% Denominator,,Numerator| Numerator ,, Denominator | Denominator ,, Numerator
#%Order% 101
fraction = $(integer_int_extend) $(fraction_cnv_slash) $(integer_int) : $3 $2 $1
| $(integer_int) $(fraction2) $(integer_int)
| $(pure_decimal) ("" : "/") $(percent_transform);
这个有点复杂,但容我慢慢讲解。分数有三种情况,如刚才的三分之一,或是1/3,或是30%。分别对应上面fraction规则的三个子规则。仔细地看上面的规则,不难理解。
值得注意的是Property这个标签,该标签定义了如何抽取信息。也是用竖线分隔,每个名称对应下面的一个子规则,为空的直接跳过。那么”十三分之二十四“中,“十三”就对应Numerator, 而“二十四”对应Denominator。来测试一下:
print(core.Extract('十三分之二十四',entities=[core.Entities['fraction']]))
我们用Extract函数来抽取文本,返回的是一个字典,entites是可选参数,我们限制只用fraction规则来匹配,获得输出:
[{'Numerator': '24', '#rewrite': '24/13', '#type': 'fraction',
'#match': '十三分之二十四', 'Denominator': '13', '#pos': 3}]
是不是很赞?
有一种需求还没谈到,将所有的大写字母转换为小写字母,你可能会想定义26个字符串规则,并用或表达式来拼接起来吧?这样太费事了。我们可以直接这样:
low_to_up_letter = (/[A-Z]/) : "str.lower(mt)";
[A-Z]匹配了所有的大写字母,将匹配结果送到后半段的转写,内置的解释器会执行那段python代码,将其转换为小写,mt代表前面表达式的匹配串,rt代表转写串。好在[A-Z]不执行转写,可以认为mt==rt.
这是在转写过程中嵌入python的例子,还能在匹配时嵌入转写:
foo = "findsecret" : "print(mt)";
前面的findsecret函数负责在字符串中找到“神秘文本”,后面的转写代码打印出来,并将原始的字符返回…
我相信你没有,因为读懂那个匹配规则的日志文件,就需要最少五分钟,但如果你有编译原理和正则基础的话,还是能很快理解的。而从零开发这个引擎,到反复优化和完善,花了一年之久。
定义了各种数字之后,我们就能很快地定义时间,日期,电话号码,地址…而你看到的只是TN语言的冰山一角。
-
它能够分析文本的模式,解析诸如ABCABC这样的序列,从而发现这是一个重复模式。
-
不仅能够顺序匹配,还能逆向,甚至乱序匹配,这就能够抽取类似“学校的校训”这样的问题。
-
规则可以调用自身,配合脚本,因此能够实现递归下降解析。例如30行代码实现xml解析,或20行规则实现自然语言计算器。
-
规则可以嵌入脚本,甚至动态生成代码,因此,甚至在理论上,TN能够自己编译自己。
-
TN还能做一个简单的SQL解释器,或是中文英文的简单互相翻译的工具。
是不是已经激动地颤抖了?唯一限制你能力的就是你的想象力。本博客将会进一步发布一系列有关tn的内容,包括高级语法, tn优化等。
感兴趣的可以联系作者