![]()
![]()
![]()

OpsML is a comprehensive toolkit designed to streamline and standardize machine learning operations. It offers:
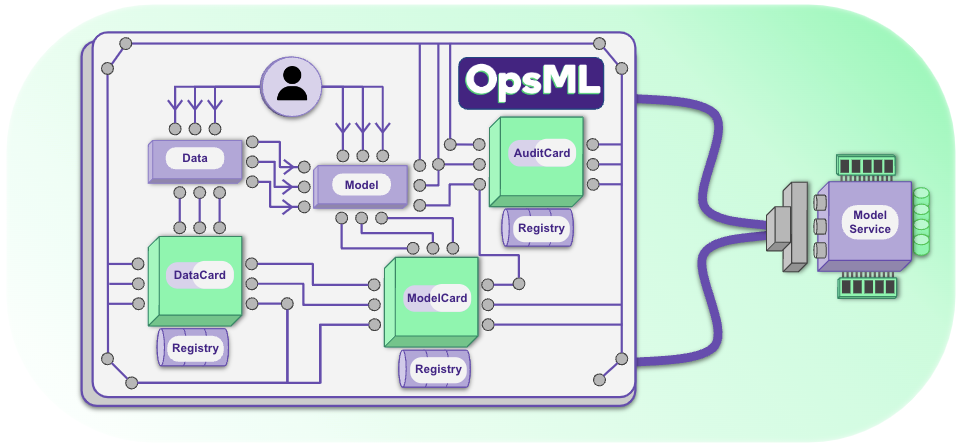
- Universal Registration System: A centralized platform for managing all ML artifacts.
- Standardized Governance: Implement consistent practices across data science and engineering teams.
- Artifact Lifecycle Management: Robust tracking, versioning, and storage solutions for all ML components.
- Reproducible Workflows: Establish repeatable patterns for ML project management.
- Cross-functional Compatibility: Bridge the gap between data science experimentation and production engineering.
- Version Control for ML: Apply software engineering best practices to machine learning artifacts.
- Metadata-Driven Approach: Enhance discoverability and traceability of models, datasets, and experiments.
This toolkit empowers teams to maintain rigorous control over their ML projects, from initial data preprocessing to model deployment and monitoring, all within a unified, scalable framework.
OpsML addresses a critical gap in the ML ecosystem: the lack of a universal standard for artifact registration and governance. Our experience with various open-source and proprietary tools revealed a persistent need to integrate disparate systems for effective artifact management and deployment. This led to the development of OpsML, a unified framework designed to streamline ML operations.
Key Features:
- Modular Architecture: Seamlessly integrates into existing ML pipelines and workflows.
- Card-based Artifact System: Implements a SQL-based registry for tracking, versioning, and storing ML artifacts (data, models, runs, projects). Think of it as
trading cards for machine learning. - Strong Type Enforcement: Ensures data integrity with built-in type checking for data and model artifacts.
- Extensive Library Support: Compatible with a wide range of ML and data processing libraries.
- Automated ML Ops:
- Auto-conversion to ONNX format
- Intelligent metadata generation
- Streamlined production packaging
- Out of the box model monitoring*
- Unified Governance Model: Provides a consistent framework for managing the entire ML lifecycle, from experimentation to production.
- Scalable Design: Accommodates growing complexity of ML projects and increasing team sizes.
OpsML aims to be the common language for ML artifact management, reducing cognitive overhead and enabling teams to focus on model development and deployment rather than operational complexities.
* OpsML is integrated with Scouter out of the box. However, a Scouter server instance is required to use this feature.Add quality control to your ML projects with little effort! With OpsML, data and models are added to interfaces and cards, which are then registered via card registries.
Given its simple and modular design, OpsML can be easily incorporated into existing workflows.
poetry add opsmlpip install opsmlSetup your local environment:
By default, OpsML will log artifacts and experiments locally. To change this behavior and log to a remote server, you'll need to set the following environment variables:
export OPSML_TRACKING_URI=${YOUR_TRACKING_URI}You can find more information on how to set up the tracking and storage uris here.
If running the example below locally, with a local server, make sure to install the server extra:
poetry add "opsml[server]"from sklearn.linear_model import LinearRegression
from opsml import CardInfo, CardRegistries, DataCard, ModelCard, PandasData, SklearnModel
from opsml.helpers.data import create_fake_data
# Setup
info = CardInfo(name="linear-regression", repository="opsml", contact="[email protected]")
registries = CardRegistries()
# Create and register DataCard
X, y = create_fake_data(n_samples=1000, task_type="regression")
X["target"] = y
data_interface = PandasData(
data=X,
data_splits=[
DataSplit(label="train", column_name="col_1", column_value=0.5, inequality=">="),
DataSplit(label="test", column_name="col_1", column_value=0.5, inequality="<"),
],
dependent_vars=["target"]
)
datacard = DataCard(interface=data_interface, info=info)
registries.data.register_card(card=datacard)
# Train model
data = datacard.split_data()
reg = LinearRegression().fit(data["train"].X, data["train"].y)
# Create and register ModelCard
model_interface = SklearnModel(
model=reg,
sample_data=data["train"].X,
task_type="regression"
)
modelcard = ModelCard(
interface=model_interface,
info=info,
to_onnx=True,
datacard_uid=datacard.uid
)
registries.model.register_card(card=modelcard)Now that OpsML is installed, you're ready to start using it!
It's time to point you to the official Documentation Website for more information on how to use OpsML
see Installation for more information on how to install OpsML in different environments.
OpsML is designed to work with a variety of ML and data libraries. The following libraries are currently supported:
| Name | Opsml Implementation |
|---|---|
| Pandas | PandasData |
| Polars | PolarsData |
| Torch | TorchData |
| Arrow | ArrowData |
| Numpy | NumpyData |
| Sql | SqlData |
| Text | TextDataset |
| Image | ImageDataset |
| Name | Opsml Implementation | Example |
|---|---|---|
| Sklearn | SklearnModel |
link |
| LightGBM | LightGBMModel |
link |
| XGBoost | XGBoostModel |
link |
| CatBoost | CatBoostModel |
link |
| Torch | TorchModel |
link |
| Torch Lightning | LightningModel |
link |
| TensorFlow | TensorFlowModel |
link |
| HuggingFace | HuggingFaceModel |
link |
| Vowpal Wabbit | VowpalWabbitModel |
link |
If you'd like to contribute, be sure to check out our contributing guide! If you'd like to work on any outstanding items, check out the roadmap section in the docs and get started 😃
Thanks goes to these phenomenal projects and people for creating a great foundation to build from!