CEHR-BERT is a large language model developed for the structured EHR data, the work has been published at https://proceedings.mlr.press/v158/pang21a.html. CEHR-BERT currently only supports the structured EHR data in the OMOP format, which is a common data model used to support observational studies and managed by the Observational Health Data Science and Informatics (OHDSI) open-science community. There are three major components in CEHR-BERT, data generation, model pre-training, and model evaluation with fine-tuning, those components work in conjunction to provide an end-to-end model evaluation framework. The CEHR-BERT framework is designed to be extensible, users could write their own pretraining models, evaluation procedures, and downstream prediction tasks by extending the abstract classes, see click on the links for more details. For a quick start, navigate to the Get Started section.
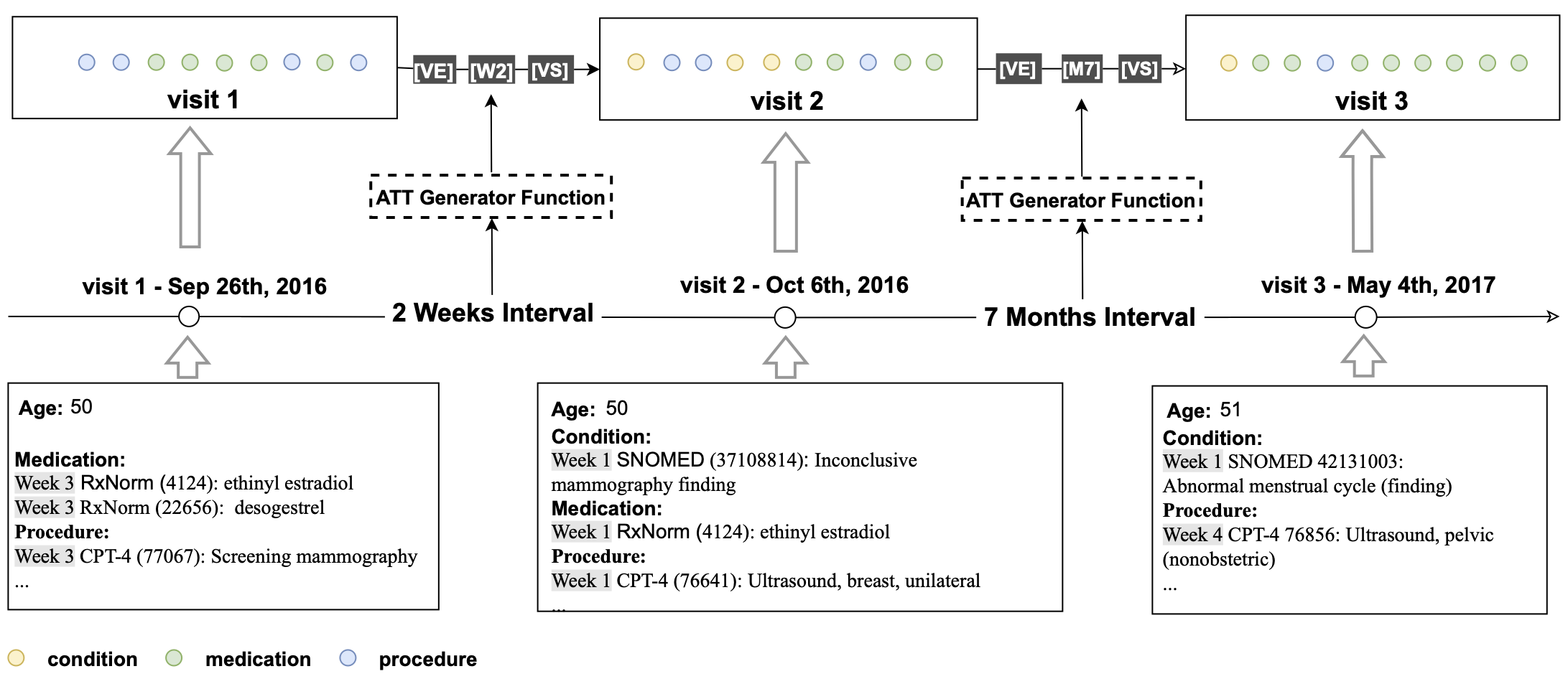
For each patient, all medical codes were aggregated and constructed into a sequence chronologically.
In order to incorporate temporal information, we inserted an artificial time token (ATT) between two neighboring visits
based on their time interval.
The following logic was used for creating ATTs based on the following time intervals between visits, if less than 28
days, ATTs take on the form of
- beyond 365 days then a LT (Long Term) token is inserted. In addition, we added two more special tokens — VS and VE to represent the start and the end of a visit to explicitly define the visit segment, where all the concepts associated with the visit are subsumed by VS and VE.
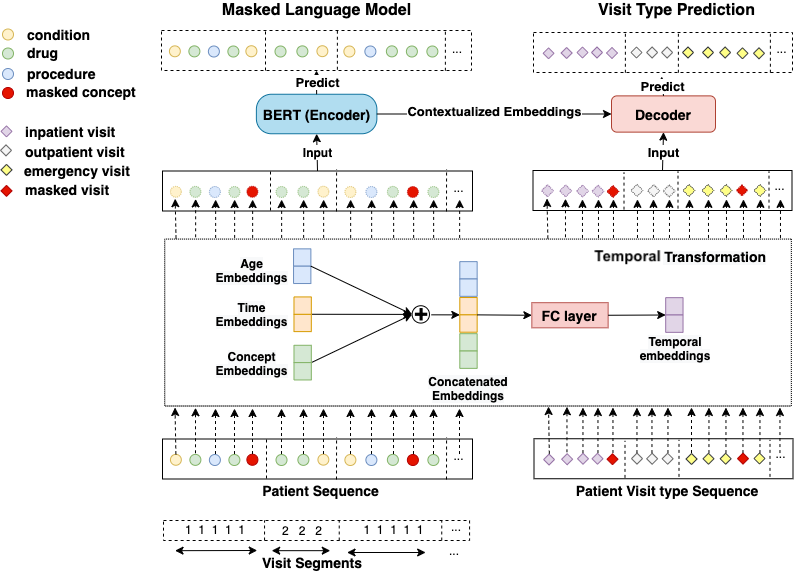
Overview of our BERT architecture on structured EHR data. To distinguish visit boundaries, visit segment embeddings are added to concept embeddings. Next, both visit embeddings and concept embeddings go through a temporal transformation, where concept, age and time embeddings are concatenated together. The concatenated embeddings are then fed into a fully connected layer. This temporal concept embedding becomes the input to BERT. We used the BERT learning objective Masked Language Model as the primary learning objective and introduced an EHR specific secondary learning objective visit type prediction.
The project is built in python 3.10, and project dependency needs to be installed
Create a new Python virtual environment
python3.10 -m venv .venv;
source .venv/bin/activate;Build the project
pip install -e .[dev]Download jtds-1.3.1.jar into the spark jars folder in the python environment
cp jtds-1.3.1.jar .venv/lib/python3.10/site-packages/pyspark/jars/Instructions for Use with MEDS
1. Convert MEDS to the meds_reader database
If you don't have the MEDS dataset, you could convert the OMOP dataset to the MEDS using meds_etl. We have prepared a synthea dataset with 1M patients for you to test, you could download it at omop_synthea.tar.gz
tar -xvf omop_synthea.tar .Convert the OMOP dataset to the MEDS format
pip install meds_etl==0.3.6;
meds_etl_omop omop_synthea synthea_meds;Convert MEDS to the meds_reader database to get the patient level data
meds_reader_convert synthea_meds synthea_meds_reader --num_threads 4mkdir test_dataset_prepared;
mkdir test_synthea_results;
python -m cehrbert.runners.hf_cehrbert_pretrain_runner sample_configs/hf_cehrbert_pretrain_runner_meds_config.yamlWe created a spark app to download OMOP tables from SQL Server as parquet files. You need adjust the properties
in db_properties.ini to match with your database setup.
PYTHONPATH=./: spark-submit tools/download_omop_tables.py -c db_properties.ini -tc person visit_occurrence condition_occurrence procedure_occurrence drug_exposure measurement observation_period concept concept_relationship concept_ancestor -o ~/Documents/omop_test/We have prepared a synthea dataset with 1M patients for you to test, you could download it at omop_synthea.tar.gz
tar -xvf omop_synthea.tar ~/Document/omop_test/We order the patient events in chronological order and put all data points in a sequence. We insert artificial tokens VS (visit start) and VE (visit end) to the start and the end of the visit. In addition, we insert artificial time tokens (ATT) between visits to indicate the time interval between visits. This approach allows us to apply BERT to structured EHR as-is. The sequence can be seen conceptually as [VS] [V1] [VE] [ATT] [VS] [V2] [VE], where [V1] and [V2] represent a list of concepts associated with those visits.
PYTHONPATH=./: spark-submit spark_apps/generate_training_data.py -i ~/Documents/omop_test/ -o ~/Documents/omop_test/cehr-bert -tc condition_occurrence procedure_occurrence drug_exposure -d 1985-01-01 --is_new_patient_representation -ivIf you don't have your own OMOP instance, we have provided a sample of patient sequence data generated using Synthea
at sample/patient_sequence in the repo. CEHR-BERT expects the data folder to be named as patient_sequence
mkdir test_dataset_prepared;
mkdir test_results;
python -m cehrbert.runners.hf_cehrbert_pretrain_runner sample_configs/hf_cehrbert_pretrain_runner_config.yamlIf your dataset is large, you could add --use_dask in the command above
If you don't have your own OMOP instance, we have provided a sample of patient sequence data generated using Synthea
at sample/hf_readmissioon in the repo
PYTHONPATH=./:$PYTHONPATH spark-submit spark_apps/prediction_cohorts/hf_readmission.py -c hf_readmission -i ~/Documents/omop_test/ -o ~/Documents/omop_test/cehr-bert -dl 1985-01-01 -du 2020-12-31 -l 18 -u 100 -ow 360 -ps 0 -pw 30 --is_new_patient_representationmkdir test_finetune_results;
python -m cehrbert.runners.hf_cehrbert_finetune_runner sample_configs/hf_cehrbert_finetuning_runner_config.yamlIf you have any questions, feel free to contact us at [email protected]
Please acknowledge the following work in papers
Chao Pang, Xinzhuo Jiang, Krishna S. Kalluri, Matthew Spotnitz, RuiJun Chen, Adler Perotte, and Karthik Natarajan. "Cehr-bert: Incorporating temporal information from structured ehr data to improve prediction tasks." In Proceedings of Machine Learning for Health, volume 158 of Proceedings of Machine Learning Research, pages 239–260. PMLR, 04 Dec 2021.