https://tianchi.aliyun.com/competition/entrance/532118/information
题目大纲 2011年,阿里基于开源数据库HBase构建了分布式半结构化存储系统Ali-HBase,服务于淘宝历史订单等大数据场景,经过多年的双十一历练,沉淀了高可用、高扩展等众多特性。随后,为了进一步优化HBase,阿里云瑶池正式推出云原生多模数据库Lindorm,相比于Ali-HBase,其在跨机房、性能成本、索引、SQL等方面获得全面增强,支撑着支付宝账单、手淘消息、阿里客服等关键业务,为阿里巴巴核心业务提供支撑。
近年来,随着阿里数字化能力服务实体经济的趋势,作为阿里云创新产品的Lindorm不断升级,为工业互联网、车联网等产业数字化升级融入了多种创新技术,支持宽表、时序、文本、对象、流、时空等多种数据的统一访问和融合处理,兼容SQL、HBase/Cassandra/S3、TSDB、HDFS、Solr、Kafka等多种标准接口和无缝集成三方生态工具。作为云原生多模数据库,Lindorm是日志、监控、广告、出行、社交、风控等场景的首选数据库,也逐渐成为互联网、车联网、制造、金融等领域头部客户的首选。
本次比赛以 Lindorm 服务新能源汽车行业的数字化转型为背景,参赛者需要基于指定代码工程设计并实现一个简易版的数据库存储引擎,用于实现对海量新能源汽车上报的数据进行高效读写与存储。
评测逻辑 初赛评测方向 初赛要求实现一个基于本地文件系统读写的数据库存储引擎,评测程序将会模拟业务系统对选手实现的数据库存储引擎进行读写访问。选手需要实现一个简化、高效的存储引擎,可以在限定的接口能力范围内支持海量数据集的写入以及并发数据查询。具体的接口会定义在提供的 CodeBase 工程代码中。
评测程序会基于参赛选手提交的代码进行构建,并加载选手的程序调用协定的写入接口,将测试用的数据集进行写入最终统计写完指定数目所用的时间。在数据写入后重启系统后测算落盘后的文件大小从而计算压缩比。之后通过并发的方式基于给定的时间范围和检索条件调用查询接口持续查询数据,并统计平均查询耗时。 运行结束时将根据先前统计出的 写入耗时、数据压缩比、平均查询耗时 给出一个评分,并基于评分进行排名。
整个评测的流程概要如下:

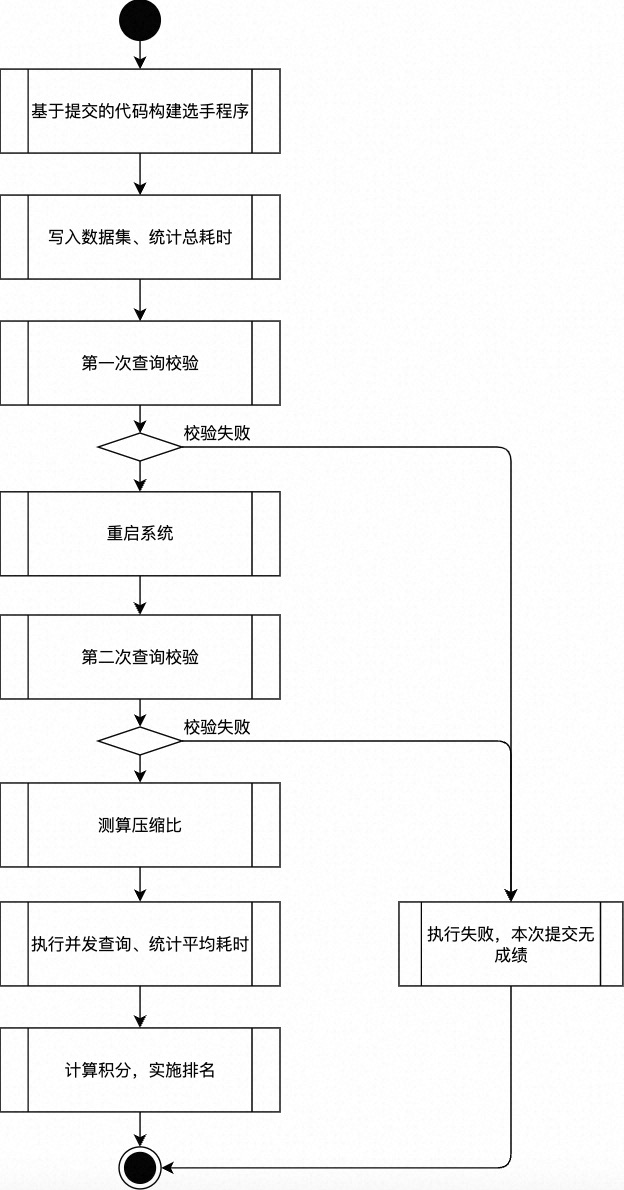{kind=link}
复赛评测方向 复赛的评测过程基本与初赛保持一致,但是会在以下层面进行扩展,从而进一步考察选手所实现的存储引擎的性能与功能。
数据多样性的扩展 在复赛中生成的数据会结合实际车联网场景的常见需求,对数据的多样性进行扩展,以求贴合实际需要。同时在数据规模上也进行了扩大。
数据查询阶段的扩展 查询将不仅仅查询原始数据,而是在初赛的查询场景基础上添加更加复杂的查询场景,通过并发来压测其性能。 新增的两个查询场景分别是(详细查询接口定义,可参见后文提供的代码模版):
指定车辆在大范围时间跨度内数据的聚合查询。
指定车辆在指定时间范围内包含条件过滤的降采样查询。
选手程序目标 参赛选手所实现的简易版数据库存储引擎需要满足以下要求:
基于提供的 CodeBase 工程进行实现。实现的存储引擎也需要实现指定接口以实现与评测程序的交互(详细的接口定义可参见提供的代码工程)
存储引擎支持数据按“表”进行组织,其中入库的数据集模型满足以下要求:
唯一标识 timestamp 指标 1 指标 2 ...... 指标 60 车辆标识码 1 时间戳 1 值 1 值 1 ...... 值 1 车辆标识码 2 时间戳 2 值 2 值 2 ...... 值 2 车辆标识码 3 时间戳 3 值 3 值 3 ...... 值 3 以上数据均为虚拟数据。
车辆唯一标识是一个字符串类型作为入库数据对象的唯一标识。
时间戳是一个以 8 字节整型数表示的 Unix 时间戳(语义精确到毫秒)。
指标的类型有以下三种可能:
不定长度的字符串类型。
8 字节浮点数类型。
4 字节整数类型。
评测程序将数据写入前会将写入数据集的 Schema 信息(包含表名、标签名、字段名及类型)通过建表接口传给存储引擎。存储引擎需要实现的写入接口需要能够支持满足 Schema 信息条件的数据集写入。
在评测程序测试查询之前会进行重启操作,存储引擎需要能够将写入的数据落盘到本地存储上。
存储引擎还需要基于 CodeBase 中定义的查询接口实现数据的检索查询能力。
选手编写的程序实现除了 CodeBase 中给定的 Dependency 之外,无法依赖任何其他第三方 Dependency。
赛题规则及提交说明 参赛流程 enter image description here
赛题规则 评测统一运行在下述运行环境:
操作系统: Alibaba Cloud Linux 2
机器规格:8vCPU + 8GB 内存 + 500GB 本地盘 (ESSD PL0))
参赛程序语言限定 参赛选手可任选下述一个代码模版下载,并进行赛题实现。
Java 代码模版:lindorm-tsdb-contest-java.zip
C++代码模版: lindorm-tsdb-contest-cpp.zip
提交说明 提交评测时需要将整个工程打成 zip 包上传,评测程序将会构建整个工程生成对应的库文件并加载使用。
每组选手每天最多只能提交3次任务。
排名规则 测试程序执行完一次任务后会记录三个指标:
写入 TPS( Written rows per second)
四种查询场景分别测得的 QPS(Queried rows per second)
数据压缩率
打分程序会基于上述三个指标 结合数据集大小、存储引擎将数据落盘后实际所占存储大小进一步计算以下指标:
写入 TPS(Rows per second)
查询 QPS(Queries per second)
之后结合实际存储大小(成本)进行归一化处理得出一个单位存储成本上的写入查询综合评分作为选手成绩。测试平台会基于选手提交任务所跑出的分值取历次最好成绩记录在排行榜上。
作弊说明 如果发现有作弊行为,且取消参赛资格。以下情况均会被视作作弊:
Hack 修改了评测程序
使用 CodeBase 工程定义之外的依赖库
落盘的数据文件使用了要求路径以外的路径,从而影响了压缩率统计