This repository has been archived by the owner on Mar 12, 2023. It is now read-only.
Benefits of Cask DRE
Prior to Cask DRE, it was traditional lifecycle of SDLC for enabling transformation rules for data processing.
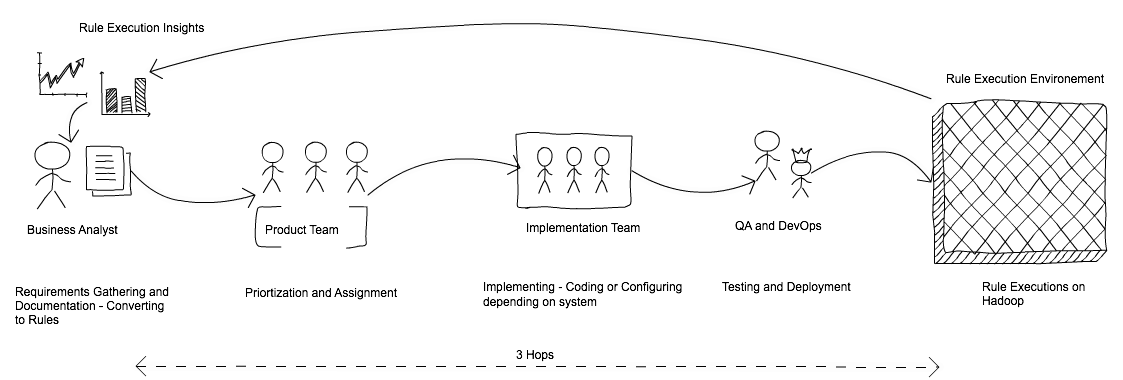
Introduction of Cask Distributed Rules Engine into the Hadoop eco-system brings the Technical Business Analyst more closer to processing and be involved directly in the ingestion process or policy enforcements on the data being processed.
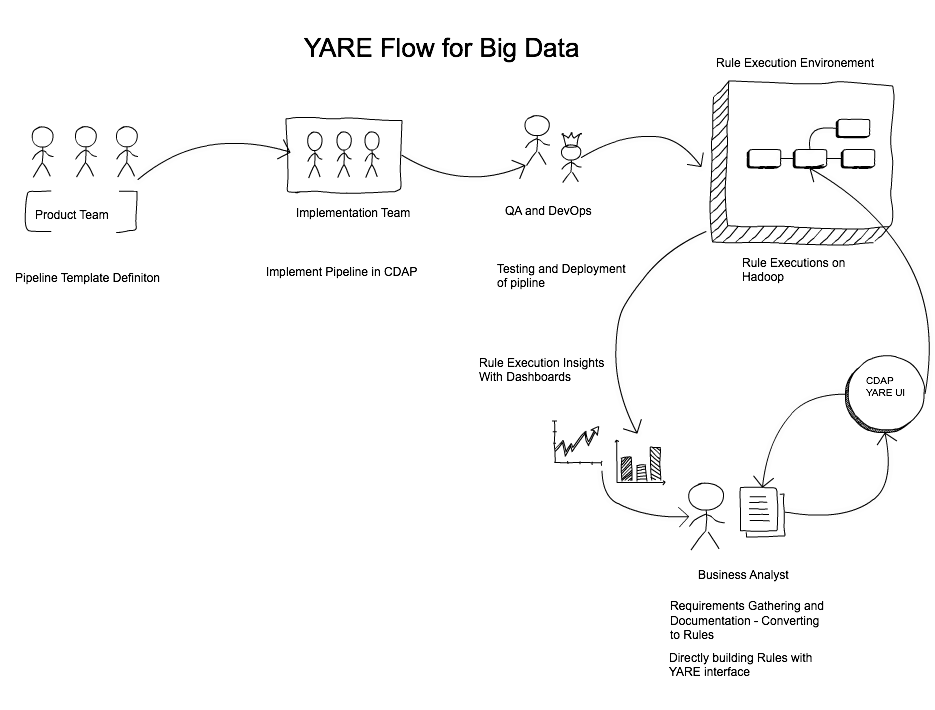
Additional benefits of using Cask DRE in your big data environment.
-
Non-Programmers who want to analyze big data
- Declarative language support, easy to under for non-programmers.
- Easy-to-verify Rules.
- They serve as documentation for policies and transformations.
- Don't need to write code.
- Use the provided user interface to write rules and manage them.
-
One-time infrastructure setup
- Rules are plug and play.
-
Centralization of knowledge
- Allows you to create a knowledge base that is executable in your big data environment.
- Provides single-point of truth for all policies and transformation needs.
-
Logic and Data Separation
- Allows frequent change requests, one can add new rules without having to modify the existing rules.
- Data can reside on your Hadoop cluster, Cloud Storage or even traditional databases, rules for transforming them are separated.
- Enables easy re-use of rules across Big Data and Traditional Data stores.
-
Speed and Scalability
- Processing large dataset.
- Scaling horizontally as you cluster or data grows.
- Support Realtime and Batch workloads.
-
Tool Integration
- Available as a library to integrate with JBoss, WebLogic, Spring
- Integrate with SQL tools through CDAP provided JDBC driver with SQL clients.