v3.28.0
ac3afd5
Release v3.28.0 (2022-07-12)
- Overview
- Changelog
- Add a
labelproperty to audio, video, and text tracks - Adaptive content duration based on the current tracks
- DRM: Better handling of key ids absent from the Manifest
- RELOADING is now generally triggered asynchronously
- Detection of full segment Garbage Collection
- Better debugging experience and testing of complex streams
Overview
The v3.28.0 release has now been published to npm.
Though it is technically a minor release, in terms of semantic versioning, it only have few new features and mostly brings bug fixes and improvements:
- Tracks API now also optionally have a
labelstring attribute if it found one in the Manifest - A content's duration may now evolve in function of the current tracks chosen, to give a more precize one
- The
RELOADINGstate is now triggered mostly asynchronously to facilitate its handling - Media data completely garbage collected by the browser is now properly detected to avoid remaining very rare request loops
- TTML: more EBU-TT subtitles are now parsed, by considering the potential
ttXML namespace we may find in those files. - DASH: multiple small fixes have been added to raise compatibility with some peculiar MPD
- An issue has been fixed which made a set
maxVideoBufferSizeappear to be inaccurate in some situations. - DRM: If the key id is not found in the Manifest file, it may be parsed directly from the media data itself, to unlock advanced features with such contents.
- Multiple other fixes and improvements (you can find the changelog at the bottom of this release note).
Changelog
Features
- Add
labelto audio, video and text track APIs (such asgetAvailableAudioTracks) which gives a human-readable description of the corresponding track, if available in the Manifest [#1105, #1109] - Automatically set the LogLevel to
"DEBUG"if a global__RX_PLAYER_DEBUG_MODE__constant is set totrue, to simplify debugging [#1115]
Bug fixes
- Use the first compatible codec of the current AdaptationSet when creating a SourceBuffer [#1094]
- DASH/DRM: Fix potential infinite rebuffering when a KID is not announced in the MPD [#1113]
- DRM: Fix quality fallback when loading a content whose license has been cached under an extended
singleLicensePersetting and when starting (and staying) with a quality whose key id is not in it [#1133] - DASH: Avoid infinite loop due to rounding errors while parsing multi-Periods MPDs [#1111, #1110]
- After a
RELOADINGstate, stay inPAUSEDif the media element was paused synchronously before the side-effect which triggered the reloading (usually coming from the API) was perform [#1132] - Fix issue with
maxVideoBufferSizesetting which could lead to too much data being buffered [#1125] - Prevent possibility of requests loops and infinite rebuffering when a pushed segment is always completely and immediately garbage collected by the browser [#1123]
- DASH: Fix potential rare memory leak when stopping the content after it has reloaded at least once [#1135]
- Directfile: Properly announce the audio track's
audioDescriptionaccessibility attribute in directfile mode on Safari [#1136] - DASH: Fix issues that could arise if a segment is calculated to start at a negative position [#1122]
- DASH: Fix possibility of wrong segments being requested when a SegmentTimeline in a given Period (whose Period@end is set) had an S@r set to
-1at its end [#1098] - DASH: If the first
<S>has its S@t attribute not set, make as if it is set to0[#1118]
Other improvements
- TTML: Add support for percent based thickness for textOutline in TTML Subtitles [#1108]
- If seeking after the last potential position, load last segments before ending [#1097]
- Improve TypeScript's language servers auto import feature with the RxPlayer by better redirecting to the exported type [#1126]
- The duration set on the media element is now only relative to the current chosen tracks (it was previously relative to all potential track). This allows to seek later when switching e.g. to a longer video track [#1102]
- Errors coming from an HTMLMediaElement now have the browser's error message if it exists [#1112]
- TTML: Better handle EBU-TT subtitles by handling the
ttXML namespace in our TTML parser [#1131] - DRM: Information on persisted DRM sessions are now automatically updated to their last version when possible [#1096]
- Only log values which are relatively inexpensive to stringify to reduce the difference between debugging sessions and what is usually seen in production [#1116]
Add a label property to audio, video, and text tracks
Current track labeling
To choose between several audio, video or text tracks, an application had previously only access to its key characteristics: its language (for audio and text tracks), codecs, accessibility features, resolution of its qualities (for video tracks) etc.
If they had to display a track choice to the user, applications usually then derived a name from these characteristics.
For example, french closed captions could be proposed as "French [CC]", a dolby digital + italian audio track as "Itialian [Dolby Digital +]", and so on.

Screenshot: one of the user interfaces used at Canal+ for french users. The various audio and text tracks' names proposed there are actually entirely derived from the tracks main characteristics such as the language and accessibility features.
All this works pretty well but this system have some limitations. For example, different tracks could have the same exposed characteristics in which case they would have the same name.
Moreover, it severely limits the information you can give to the final user to only those exposed characteristics. What if you want to indicate that an audio track of some sport game only contain stadium noise for example?
The DASH <Label> element
The DASH-IF IOP, a DASH standard we follow, comes to the rescue by authorizing setting a Label element on the corresponding <AdaptationSet>, which contains a description of what the track is about. This is explicitely done to provide a description of the track to the user in the final user interface.

Example of Label elements on multiple text AdaptationSets, generally signalling how the track choice should be worded.
This is not limited to DASH either. For example HLS also has a NAME attribute for roughly the same thing (though only DASH's Label is handled for now).
In the RxPlayer API
Now, if <Label> elements are present in a DASH MPD, the RxPlayer will provide a label property through its various tracks API:
-
In track objects of the
getAvailableAudioTracks,getAvailableVideoTracksandgetAvailableTextTracksmethods, to know the label of all the current track choices -
As property of the object that may be returned by the
getVideoTrack,getAudioTrackandgetTextTrackmethod, to know the label of the currently-chosen track -
As property of track objects of the linked
availableAudioTracksChange,availableTextTracksChange,availableVideoTracksChange,audioTrackChange,textTrackChangeandvideoTrackChangeevents.

Output of a
getAvailableTextTrackscall in the Chrome inspector's console after playing the content linked to the previously's pictured MPD
In cases where no <Label> element is present on the corresponding <AdaptationSet>, the label property may either not be defined on the track objects or set to undefined.
As any DASH feature, this is available both with our default JavaScript DASH parser and with our WebAssembly-powered one.
Note: This feature has been primarily developed by outside contributors, only the WebAssembly (Rust) version having been developed by one of the core RxPlayer maintainers (@alaamoum) later.
Thanks a lot to @johnhollen and @stephanterning for it, it's always very pleasing to us to see new external contributions.
Adaptive content duration based on the current tracks
The duration property
The <video> and <audio> HTML elements have a duration property which returns the presumed last position that can be reached by playback.
This value is often used to provide the last position in a UI timeline, and is also the maximum time on which seeking is possible.

Screenshot: to the left, a media timeline which shows here that we're playing the first second and that we can seek everywhere from 0 seconds to 2 minutes.
To the right, the RxPlayer API that can be used to know that upper bound. BothgetVideoDuration()(the duration set on the<video>element) andgetMaximumPosition()(the maximum position on which you should be able to seek), should in most cases be equal. Here both indicating a maximum position of 120 seconds, which is 2 minutes.
An evolving concept
The browser does not know in advance how much media data will be pushed, so it does not initially know which duration should be set.
For this reason, the RxPlayer has to provide this information itself, Whewhich it deduces from the Manifest file, before beginning playback when still in the LOADING player state.
After pushing some audio and video media data, if the end of that data exceeded the duration initially-set by the RxPlayer, the browser automatically raises the duration by the difference.
Finally, once the actual last audio and video data is pushed, the RxPlayer calls the endOfStream API, which among other things automatically updates again the duration to the last position for which there's both audio and video data.
output_raising.mp4
Video: Example of an inexact duration being initially set on the video element. We can see that we thought the content would end at 12 minutes and 5 seconds. The duration is automatically raised by the browser when audio and video media data higher than this duration is pushed. We can see it happening several times here progressively as media data is pushed.
Once 12:14 is reached, which is the true end of the content, we can see that the duration is not raising anymore.
The seemingly simple task of "guessing" which duration to put initially is actually quite arduous.
For example, the global duration that may be announced in the Manifest might not exactly reflect the true duration of the content. Also, we may have differences in the duration of the various video and audio tracks (some tracks might provide more content than others).
All those issues might lead to an imprecise duration, that would not only be visible on the UI timeline but also cause problem when seeking close to the end.
So what should we do?
Previous duration handling
A web platform limitation to keep in mind when defining a solution is that we can only play the intersection of video and audio media data. This means that audio without video and video without audio for the same position usually won't be playable [1].
The RxPlayer integrates that notion and thus, before this release, considered the minimum between all audio and video tracks as the initial duration of the content.
This is what seemed the safest strategy:
- There's a really low risk of being able to seek after the last playable position (there's still one, because the track duration information we rely on may still be a little imprecise)
- The duration would not lower when the content ends, but could raise if the actual video and audio tracks' are both higher than the minimum duration previously chosen. Progressively raising the duration when playing toward its end is arguably less "awkward" (less unexpected) than lowering it once the true end is reached.
output_lowering.mp4
Video: What could happen if we took the opposite strategy of setting directly the highest potential duration. Here we see that the video's duration is originally guessed as 12 minutes and 24 seconds (let's imagine that this the duration of the longest available track). We can see it directly lowers at its true 12:14 duration once the last audio and video media data is pushed (thanks to the browser's
endOfStreamAPI). This strategy was not taken to prevent seeking issues and because it seemed less "natural" than progressively raising it.
[1] If we want to get pedantic here, this is not strictly true. With a video track "shorter" than the audio track, we could for example reload the content without any video buffer, like an audio-only content, right when reaching the end of the video. This will let us be able to play the remaining audio data, but the switch would sadly lead to some visible reloading time.
The issue with that strategy
However that solution was not perfect:
- If a single, rarely used, audio or video track was much shorter than the others, the duration would be initially completely wrong.
- if the actually-chosen audio and video tracks combination had a higher duration, it would not be possible to seek toward the end until the corresponding media data has been loaded.
Even if we're talking about differences in the scale of milliseconds, it would still probably mean multiple frames of video content. Because some of RxPlayer's applications are used in contexts where per-frame navigation is important, this difference was meaningful to us.
output_seek.mp4
Video: exaggerated example of a video whose duration was guessed as 11:40 instead of 12:14 for the currently-playing tracks. Here, we try initially to seek at 725 seconds (12 minutes and 5 seconds) but the browser actually seek at 11:40 instead (700 seconds) because it cannot seek higher than the duration.
Only once media data is actually pushed after 12:05, can we begin to seek at that position (the second seek performed).
What changed
Sadly, we cannot really know for sure the precise duration of the content according to the browser before the media data has actually being pushed. Still, we could do better to limit the aforementioned issues.
The solution found in the v3.28.0 is to now only consider the minimum duration between the current audio and video tracks to define the global duration of the content, instead of all audio and video tracks, and to adaptively update it when either is updated.
This also means that the duration may change after changing the video and/or audio tracks.
output_track_duration.mp4
Video: Example switching from a first audio track with 2 minutes and 14 seconds of content to a second one with only 2 minutes and 4 seconds of content. We can see the duration updates adaptively as the new audio track is switched to.
It should be noted that we still have to set it to the minimum between the current audio and video tracks (and not e.g. the maximum) due to only being able to play the intersection for both buffers. If playing supplementary video or audio data that might remain after that minimum is important to you, we're currently thinking about providing solutions for that.
DRM: Better handling of key ids absent from the Manifest
The key id
Some of the RxPlayer advanced DRM (Digital Rights Management) features, such as the singleLicensePer and fallbackOn properties of the keySystems loadVideo options, rely heavily on the concept of "key id".
Those are small identifiers for a given key that is needed for decryption. The RxPlayer can only use that identifier to be able to refer to a key, because it doesn't know the key itself, which is handled at a lower level for security reasons (as a side-note, in more secure cases, keys might even be handled by a Trusted Execution Environment or "TEE", which allows to run hardware decryption on the CPU in total isolation of even the operating system).
Moreover, many contents today have multiple keys for a given content, for example, to ask for more copy protection guarantees before playing a higher video quality.
In that context, key ids are very important to not only link qualities to their corresponding keys but to also find out which keys are usable from those that are not. Without it, it is very difficult to fallback from undecipherable qualities, as we wouldn't be able to easily link a key declared as unusable by the lower level API to the corresponding quality.

Image: Representation of 4 key id for four different types of media of the same content. Because some keys might be usable and some not (for example, 4k keys might not be usable on some computers or phones due to a low trust in its hardware) the RxPlayer has to be able to automatically fallback from unusable keys. This is generally done by using each key's key ID.
When no key id is found in the Manifest
For this to work, the RxPlayer only previously extracted that data from the Manifest.
If it doesn't find it (which is relatively rare, as e.g. it is required in the DASH-IF IOP), the RxPlayer will still know that some key is unusable, but wouldn't be easily able to detect which quality/Representation this key is linked to.

Schema: if a key id is announced to be not usable but the RxPlayer doesn't know what that key is used for, it might not know what to do about it, which may in turn lead to infinite rebuffering or playback errors.
Previous versions of the RxPlayer still has some code to try to stay resilient in that situation.
One of those logic was the object of a regression in the last v3.27.0 which is fixed with that release, though there's another more important evolution in this release: the RxPlayer will now extract the key id directly from the media's metadata if it find it.
Extracting the key id directly from media metadata
When the RxPlayer is buffering media data, it is actually "pushing" to the browser compressed video and audio stored inside a file called the "container" file.
The most known of those container format and the most used, is commonly referred as the "mp4" format.

Image: Representation of the inner content of some mp4 file. It is a hierarchical structure of individual subdivision of metadata and data called "box" or "atom".
Here for example, "ftyp" and "pssh" are boxes, each with there own grammar and semantic.
Though its inner metadata and data is mostly used by the browser and its underlying media decoders, the RxPlayer also read some of that metadata to obtain precize information on the content it tries to play. For example, time information is read from it to improve the player's garbage-collection detection mechanism.
Some encryption-related metadata also exists.
There is the case of the "pssh" box for example, which generally contains metadata in some proprietary format and is used to generate license requests. Though it does generally contains the key id, the RxPlayer chose not to parse it and just treat it as a blob of unreadable data because the format is proprietary.
But that's not the only metadata containing the key id. The "tenc" box which may be found deeper in the whole file structure also contains the key id. Better, its format is completely specified and stable.
Because the key id is a crucial information in some scenario, the RxPlayer will now read the key id directly from media data if it isn't found in the Manifest. The consequence of doing that depends a lot on which options/features of the RxPlayer are used, but will generally result in better support of encrypted contents whose key id are not found in the Manifest.
RELOADING is now generally triggered asynchronously
The RELOADING state
The RxPlayer introduced the new RELOADING player state back at the v3.6.0 release in 2018.
This state - which may only happen in some situations using newer APIs (to not break semantic versioning guarantees) - usually lead to a brief black screen (the "reloading" phase) during which many API become temporarily unusable.
One of the frequent situations where this state is actually used in real applications is typically when updating or disabling the video track.
output_reloading.mp4
Video:
RELOADINGstep, represented here with a spinner (and awkwardly by changing the video element's dimensions here, as our demo page doesn't force a given height) triggered by disabling the video track.
Behind the RELOADING step, what actually happens is a complete reset of media buffers linked to the media element (<video> or <audio>) - more specifically by re-creating a MediaSource instance. The RxPlayer generally performs this operation when there's no other real solution, such as when removing the video buffer.
Previous behavior
Before this release, RELOADING operations were directly and synchronously triggered on operations which necessitated it.
To take the example of video track disabling or switching, the RxPlayer would most likely switch to the RELOADING state right after disableVideoTrack or setVideoTrack was called.
The fact that it happened synchronously led to poorly-understood behaviors and unnecessary complexity for application developers.
We even have an anecdote about it: months ago, two teams developing two separate applications at Canal+ relying on the RxPlayer encountered the same issue roughly around the same time. They both were attempting to update the video track first and then either the audio or text track. The video setting part worked, but the text or audio track was not updated.
In their point of view, it was totally an RxPlayer bug because their code, which basically did things like player.setVideoTrack(videoId); player.setAudioTrack(audioId); was to them too simple to be at fault.
output_reload_before.mp4
Video: Example in a previous version where we want to both disable the video and text track, for example to enable an "audio-only" mode.
A weird error is thrown when we disable the text track because the RxPlayer entered in aRELOADINGstate synchronously after disabling the video track, and track operations are not permitted under that state.
We thus end up with a text track still being displayed after the reload.
We initially answered that they should always check the state of the RxPlayer immediately before setting a track - or even perhaps better, always check the current track choices immediately before setting one.
But we knew that this behavior was not natural and thus that there was something wrong here.
The final straw was when we noticed even more subtle issues, like the fact that reloading right synchronously after the RxPlayer changed to the PAUSED state, actually reloaded in the PLAYING state (and not... in the PAUSED state like it was just before).
This made us realize that the RELOADING state's behavior was too complex and that handling it perfectly in an application could easily become a nightmare.
Our solution: asynchronous RELOADING
To avoid most of those issues, we decided to always switch to the RELOADING state asynchronously after the cause that triggered it. This means that it should now be possible to combine synchronous track update operations without having to tediously check every possibilities between each API call.
output_reload_after.mp4
Video: New behavior. Now reloading operations are mostly performed asynchronously. Here this means that it becomes possible to synchronously disable the text track after the video track has been disabled, among many other actions that may lead to a reload.
Note: Technically, this asynchronous reloading operation is right now implemented by scheduling it as a JavaScript micro-task, as the goal was only to let all synchronous code execute before we actually trigger it.
Consequently. you should still be careful if you also are scheduling micro tasks on your side (such as awaiting an already resolved Promise). Thankfully, it seems to be idiomatic in JavaScript to re-check state after those, like after any other asynchronous operations.
Detection of full segment Garbage Collection
Request loops occurrences
In the v3.26.1 release, we introduced a mechanism to prevent most request loops, which is the name we give to a situation where the same media segment is requested in an infinite loop.
This happens usually when the corresponding media data, after being loaded by the RxPlayer, seems to have been partially or completely removed by the browser.

Screenshot: At the right, we can see that the video segment behind the
mp4-live-periods-h264bl_full-3.m4sURL is being requested in a loop.
This is actually because the same video segment is being directly removed by the browser just after being pushed, we can on that matter see on the bottom left less video data than audio data here due to that missing segment.
Usual reason: garbage collection detection
The browser includes a mechanism which automatically removes media data, usually to free memory, called "garbage collection" (it has many key differences to most other mechanisms with the same name, like ones generally used for JavaScript. One such difference is that reachable - i.e. still playable - media data may still be considered "collectable").
This mechanism is triggered totally silently by the browser.
Yet the RxPlayer need to guess when it is happening, If it didn't, the partially or completely removed segment would never be re-downloaded possibly leading to "holes" in the stream.

Screenshot: "holes" in the video buffer that may be encountered if garbage collected segments are not reloaded.
Yet, taking the opposite strategy of reloading all media data that seems to have been at least partially garbage collected also has a huge disadvantage: if the browser is systematically removing parts of a segment, the RxPlayer would be reloading that segment again and again in a loop.
This is exactly the situation we were writing about earlier. To stop that from happening, the RxPlayer not only has a garbage collection mechanism, it also in parallel try to detect cases of systematic media data removal performed by the browser!
Detection of systematic data removal
This detection mechanism is simple: The RxPlayer calculates the time range media segments actually occupy right after it pushes them in the media buffer, and stores this information for later in a sort of history structure [1].
If later, it seems that the media segment had been at least partially garbage collected [2], the RxPlayer checks if the same segment had already been pushed before in that history.
If at least two entries exist in that history - meaning that the media data has been pushed at least two times - AND if both time, the garbage collected pattern in terms of time information (for example always the last 1.653 seconds) is very similar, the media data will not be loaded again and the corresponding hole will be skipped as soon as it is encountered.

Schema: Very simplified representation of what goes on here:
Some media data is requested, the RxPlayer estimates what its start and end will be.
The data is actually pushed to the browser. The RxPlayer can now know how much the buffer is filled by that data and compare it to what it expected. In this case, the data begins 1 second after what it expected, which may be a sign of garbage collection.
The RxPlayer reports how much the data filled the buffer in its own history
The RxPlayer then checks if for the same data, there are contiguous entries with similar start and end. If that's not the case, we retry loading the segment, if that was the case, the browser seems to be systematically removing data so the RxPlayer skips it instead.
[1] Rest assured, the history is relatively short lived to prevent huge memory usages when a sufficiently large amount of media data has been pushed.
[2] To note that garbage collection detection is actually not as simple as you might think. For example, the RxPlayer will directly read the content of mp4 and webm files to obtain generally more precise time information than what can be found in the Manifest. Some edge cases are also considered, such as special logic when a segment is just slightly offseted (when it both starts and ends a little later than what was expected once in the browser's buffer).
Remaining issue and fix
Sadly, we didn't profit from that mechanism if the media data was entirely ignored by the browser. This is because the history structure stored the actual time range a segment take. If it doesn't exist anymore, it doesn't take a time range at all, and thus did not exist in that history.

Schema: update of the previous schema if the whole segment seems apparently garbage collected. The previous time-focused way of dealing with systematic removal doesn't work here anymore.
Thankfully this situation is extremely rare, we only reproduced it once when doing advanced and non-representative proof of concepts [1]. Still it can happen and at such it is always better to handle that case inside the player.
The fix we brought was very simple: now another type of entry is added to the history when the corresponding media data is immediately and fully removed. And instead of comparing garbage collecting patterns to know if it should be requested again, the logic is to check that the segment has been fully removed the two last times it had been loaded.
[1] It appeared when we were cropping the majority of a media segment beginning from its start, by playing with a DASH's MPD presentationTimeOffset which lead to using the appendWindowStart API. My guess is that there were no intra-frame left the decoder could base itself from and just decided to drop the whole segment instead.
Important considerations with that fix
That modification completely fixes the issue, but raises the risk of false positives (media data wrongly assumed to be systematically removed). For example, is a media segment just has been fully removed two times in a row due to not having enough memory on the device to contain it, we may be skipping perfectly decodable data.
We have been relatively protected from this case with the previous logic, as there was a data removal pattern to check for, which may be slightly different when the media data is reloaded. But when the data is fully removed we do not have any such value to compare.
Still, we're only talking about theoretical cases which would be problematic in any cases (without this fix, a request loop would probably happen until enough data is freed). So we decided to continue with that fix, add an explanatory log when the corresponding case is encountered and even create a Troubleshooting page providing solutions for that situation (such as lowering the amount of media data that is pre-buffered) as well as others.
Better debugging experience and testing of complex streams
Two of the biggest subjects we worked on those last months are not really visible in that release, though it greatly impacted it.
RxPaired remote debugger
The RxPlayer is used at Canal+ on a large variety of devices: PC (web and application), phones, tablets, set-top boxes, game consoles, smart TVs, ChromeCast etc.
It is thus a very frequent need to remotely debug the RxPlayer's behavior on a device from a PC/Mac.
Initially, we used Chrome's remote debugger (the browser can allow remote debugging through options, a websocket connection and a Chrome inspector page served from the device through a given port) or even Weinre in some cases.
However, those had a huge impact on the device's performance. Running Chrome's remote debugger on a chromecast for example totally changed the page's behavior (due to poor performance) and even made the application crashed when playing for more than a minute.
Because being able to inspect the RxPlayer's behavior on any device is very important to us, we decided to create our own lightweight "debugger" (it is much more minimalist than Chrome's and weinre), and is moreover specialized for debugging the RxPlayer, RxPaired.
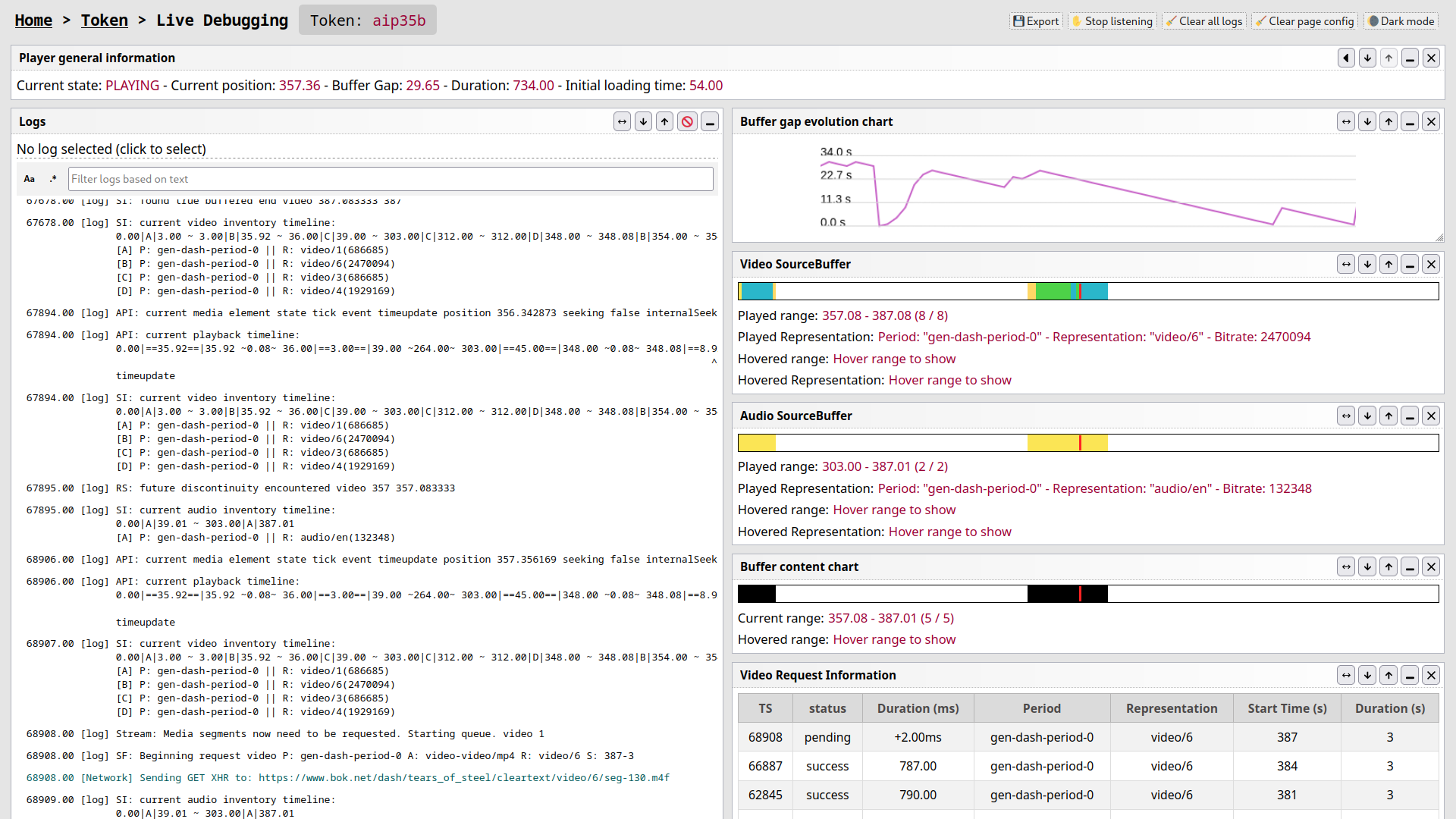
Screenshot: Screenshot of the RxPaired tool, more especially of the "inspector" page.
This project is actually divided in 3 parts:
- An inspector displaying logs and deducing various key metrics from those - it is also able to send instructions to the device
- a client which is the part on the device transferring logs in real time through a WebSocket connection and
- a server exchanging messages between the both of them.
At Canal+ we today run our own RxPaired server, which is already used by various teams at Canal+ to facilitate debugging. Especially, it helped us debug on various devices such as smart TVs, ChromeCast and UWP applications.
Despite being relatively minimalist, this tool still adds some key features such as the possibility to export and "replay" logs, the possibility to "time travel" to see metrics at the time a particular log was sent and the possibility to filter logs.
We plan to continue making evolution on it as long as it doesn't incur sensible influence (in terms of CPU usage, memory etc.) on the device.
To allow easier debugging through this tool and others, the RxPlayer now will automatically set its LogLevel to the most verbose "DEBUG" if it finds a globally-defined __RX_PLAYER_DEBUG_MODE__ property set to true (e.g. by setting it on the window).
rx-tester
Another key tool we worked on those last months have been an end-to-end testing environment (as well as tests), which for now are all sadly close-sourced.
It allows to easily tests real complex streams like those used at Canal+ and by our partners as well as easily run those tests on devices where it was previously hard to do so: smart TVs, game consoles, ChromeCast etc.

Screenshot: Rx-tester tests running on some device.
The RxPlayer already integrated some "integration" tests filling the same testing needs, but we were limited in some testing scenarios due to our limited resources and the fact that we are open-source.
Due to this openness, we couldn't just use real Canal+ live channels and VoDs, as those are encrypted, mostly expected to only be requested by subscribers and employees, and the proprietary license-requesting logic that it is associated to is not something we want to openly show.
That's why our own integration tests today just generate fake contents from very few real, locally-stored, segments by updating those (usually mp4) files on-the-fly on request through our own content server.
This method works but has the disadvantage of being complex (to understand, debug and update) and very time-consuming to create, especially for sufficiently complex situations: Even for live contents, where we might also need to include a dynamic Manifest generation logic. When talking about DRM, this becomes even more of a nightmare to test (some key systems are only on some devices, encrypted contents that are OK to be shared are not easy to find and ask for etc.).
Moreover, it only works where node.js is available, which is why our current integration tests are mostly written to run locally or on our CI. This does not reflect our current difficulties: as the player is used on more and more devices, we notice that a majority of issues seems to be related to compatibility with one device (or a few) in particular, which are most often not reproducible locally or on the CI environment.

Screenshot: the
tests/contentsdirectory, where our locally-generated contents are made
That's where rx-tester comes into play.
Its closed-source nature allows us to directly use Canal+'s proprietary logic to be able to test complex streams (multiple audio, text and sometimes video tracks, DRM, both live and VoD, multi-Period and mono-Period, different packagers etc.) with the RxPlayer, and it has been specifically written to be able to be easily testable on any device on which the RxPlayer can run.
Thanks to it, we already found some issues, like the one which triggered the need to make the RELOADING state mostly asynchronous (one of the previous chapter).
Sadly it is for now closed-sourced, though we plan to open-source what can be (the tests themselves and the frameworks part) in the medium to long term.