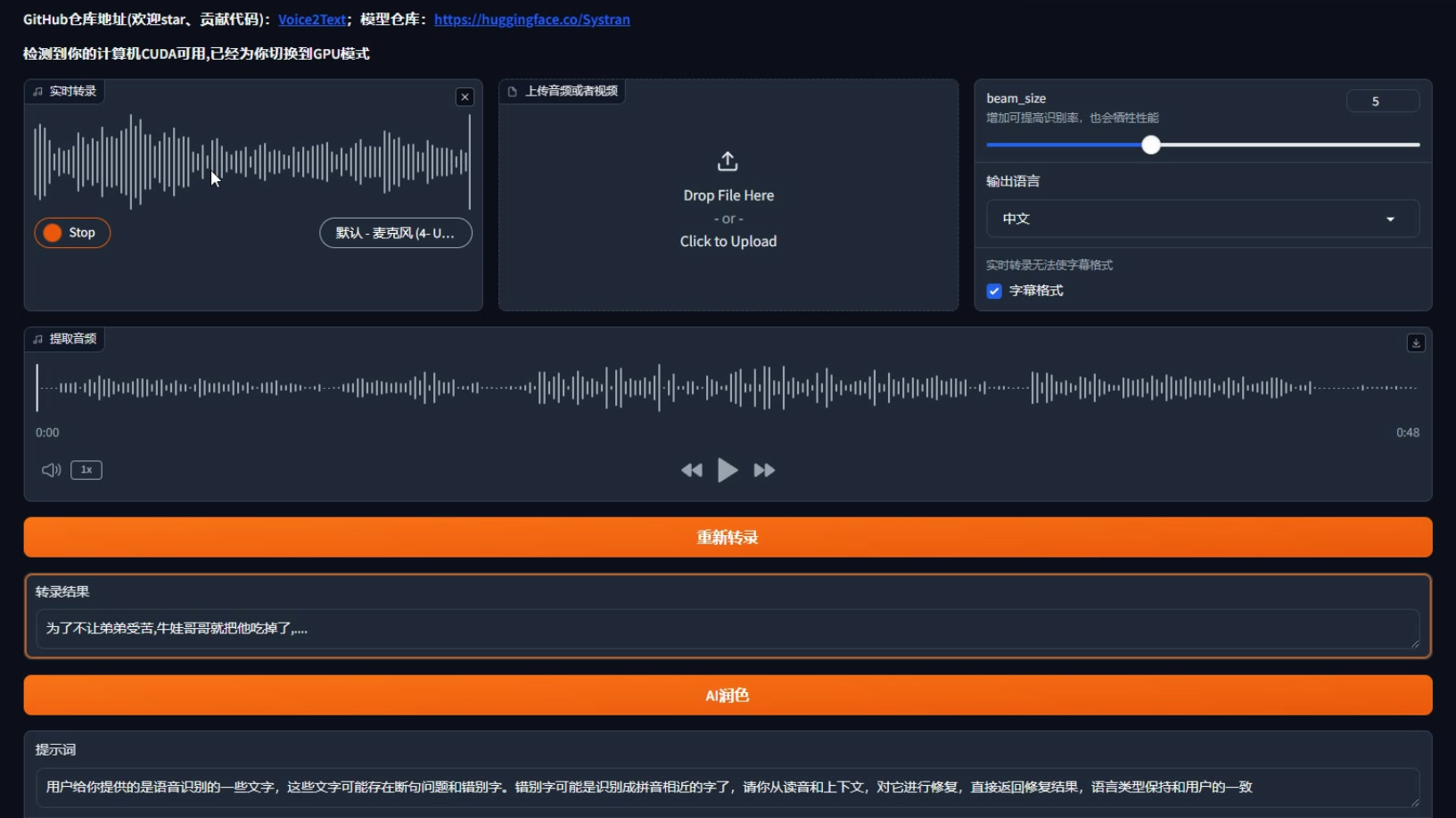
Voice2Text is a voice-to-text application based on OpenAI Whisper, supporting audio, video, and real-time speech-to-text.
- Download the package Voice2Text-pkg.rar and unzip it.
- Go to the model repository to download the faster-whisper-large-v2 model and place it in the models folder.
- Double-click
run.baton Windows orrun.shon Linux/Mac to run. - If you want to use a GPU, download and install CUDA12 yourself (the same applies to Method 2).
-
Clone the repository.
git clone https://github.com/caiwuu/Voice2Text cd ./Voice2Text -
Create a Python virtual environment.
conda create -p ./env python==3.11.9 conda activate ./env
-
Install the dependencies.
pip install -r requirements.txt
-
Download the model into the models folder from the repository: https://huggingface.co/Systran. The default model is faster-whisper-large-v2; you can change the model name in the code for other models.
-
Start the application.
python webUI.py