

BytePS is a high performance and general distributed training framework. It supports TensorFlow, Keras, PyTorch, and MXNet, and can run on either TCP or RDMA network.
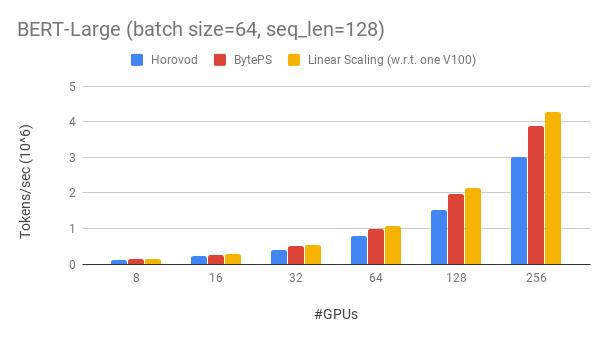
BytePS outperforms existing open-sourced distributed training frameworks by a large margin. For example, on BERT-large training, BytePS can achieve ~90% scaling efficiency with 256 GPUs (see below), which is much higher than Horovod+NCCL. In certain scenarios, BytePS can double the training speed compared with Horovod+NCCL.
- BytePS paper has been accepted to OSDI'20. The code to reproduce the end-to-end evaluation is available here.
- Support gradient compression.
- v0.2.4
- Fix compatibility issue with tf2 + standalone keras
- Add support for tensorflow.keras
- Improve robustness of broadcast
- v0.2.3
- Add DistributedDataParallel module for PyTorch
- Fix the problem of different CPU tensor using the same name
- Add skip_synchronize api for PyTorch
- Add the option for lazy/non-lazy init
- v0.2.0
- Largely improve RDMA performance by enforcing page aligned memory.
- Add IPC support for RDMA. Now support colocating servers and workers without sacrificing much performance.
- Fix a hanging bug in BytePS server.
- Fix RDMA-related segmentation fault problem during fork() (e.g., used by PyTorch data loader).
- New feature: Enable mixing use of colocate and non-colocate servers, along with a smart tensor allocation strategy.
- New feature: Add
bpslaunchas the command to launch tasks. - Add support for pip install:
pip3 install byteps
We show our experiment on BERT-large training, which is based on GluonNLP toolkit. The model uses mixed precision.
We use Tesla V100 32GB GPUs and set batch size equal to 64 per GPU. Each machine has 8 V100 GPUs (32GB memory) with NVLink-enabled. Machines are inter-connected with 100 Gbps RDMA network. This is the same hardware setup you can get on AWS.
BytePS achieves ~90% scaling efficiency for BERT-large with 256 GPUs. The code is available here. As a comparison, Horovod+NCCL has only ~70% scaling efficiency even after expert parameter tunning.
With slower network, BytePS offers even more performance advantages -- up to 2x of Horovod+NCCL. You can find more evaluation results at performance.md.
How can BytePS outperform Horovod by so much? One of the main reasons is that BytePS is designed for cloud and shared clusters, and throws away MPI.
MPI was born in the HPC world and is good for a cluster built with homogeneous hardware and for running a single job. However, cloud (or in-house shared clusters) is different.
This leads us to rethink the best communication strategy, as explained in here. In short, BytePS only uses NCCL inside a machine, while re-implements the inter-machine communication.
BytePS also incorporates many acceleration techniques such as hierarchical strategy, pipelining, tensor partitioning, NUMA-aware local communication, priority-based scheduling, etc.
We provide a step-by-step tutorial for you to run benchmark training tasks. The simplest way to start is to use our docker images. Refer to Documentations for how to launch distributed jobs and more detailed configurations. After you can start BytePS, read best practice to get the best performance.
Below, we explain how to install BytePS by yourself. There are two options.
pip3 install byteps
You can try out the latest features by directly installing from master branch:
git clone --recursive https://github.com/bytedance/byteps
cd byteps
python3 setup.py install
Notes for above two options:
- BytePS assumes that you have already installed one or more of the following frameworks: TensorFlow / PyTorch / MXNet.
- BytePS depends on CUDA and NCCL. You should specify the NCCL path with
export BYTEPS_NCCL_HOME=/path/to/nccl. By default it points to/usr/local/nccl. - The installation requires gcc>=4.9. If you are working on CentOS/Redhat and have gcc<4.9, you can try
yum install devtoolset-7before everything else. In general, we recommend using gcc 4.9 for best compatibility (how to pin gcc). - RDMA support: During setup, the script will automatically detect the RDMA header file. If you want to use RDMA, make sure your RDMA environment has been properly installed and tested before install (install on Ubuntu-18.04).
Basic examples are provided under the example folder.
To reproduce the end-to-end evaluation in our OSDI'20 paper, find the code at this repo.
Though being totally different at its core, BytePS is highly compatible with Horovod interfaces (Thank you, Horovod community!). We chose Horovod interfaces in order to minimize your efforts for testing BytePS.
If your tasks only rely on Horovod's allreduce and broadcast, you should be able to switch to BytePS in 1 minute. Simply replace import horovod.tensorflow as hvd by import byteps.tensorflow as bps, and then replace all hvd in your code by bps. If your code invokes hvd.allreduce directly, you should also replace it by bps.push_pull.
Many of our examples were copied from Horovod and modified in this way. For instance, compare the MNIST example for BytePS and Horovod.
BytePS also supports other native APIs, e.g., PyTorch Distributed Data Parallel and TensorFlow Mirrored Strategy. See DistributedDataParallel.md and MirroredStrategy.md for usage.
BytePS does not support pure CPU training for now. One reason is that the cheap PS assumption of BytePS do not hold for CPU training. Consequently, you need CUDA and NCCL to build and run BytePS.
We would like to have below features, and there is no fundamental difficulty to implement them in BytePS architecture. However, they are not implemented yet:
- Sparse model training
- Fault-tolerance
- Straggler-mitigation
-
[OSDI'20] "A Unified Architecture for Accelerating Distributed DNN Training in Heterogeneous GPU/CPU Clusters". Yimin Jiang, Yibo Zhu, Chang Lan, Bairen Yi, Yong Cui, Chuanxiong Guo.
-
[SOSP'19] "A Generic Communication Scheduler for Distributed DNN Training Acceleration". Yanghua Peng, Yibo Zhu, Yangrui Chen, Yixin Bao, Bairen Yi, Chang Lan, Chuan Wu, Chuanxiong Guo. (Code is at bytescheduler branch)