AcroMUSASHI Stream-ML(Machine Learning Library) は、AcroMUSASHI Stream をベースとした、オンライン機械学習を行うためのライブラリです。AcroMUSASHI Stream-MLを利用することで、機械学習の処理をStorm上でリアルタイムで動作させることができます。
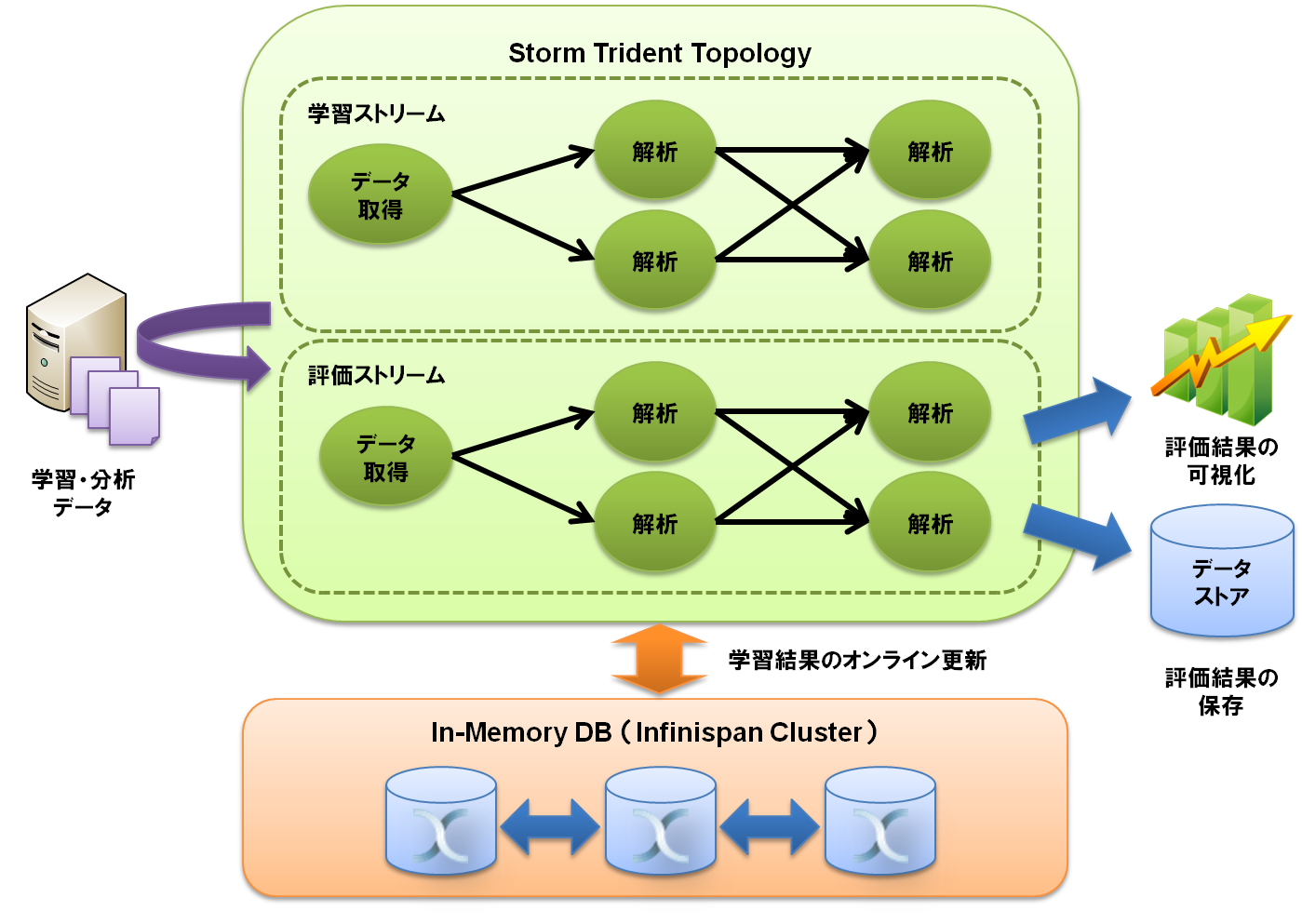
AcroMUSASHI Stream-ML は、StormのTrident機能を利用して実現しています。
Tridentに関しては、Trident tutorialを参照してください。
AcroMUSASHI Stream-ML ではInfinispanを学習データのキャッシュ先として用いています。Infinispanはメモリ上でデータを保持する分散KVSデータグリッドで、データへの高速なアクセスが可能です。
Infinispanのインストール方法/利用方法についてはInfinispanの利用方法を確認してください。
acromusashi-stream-ml を用いて開発を行うためには、Mavenのビルド定義ファイルであるpom.xmlに以下の内容を記述してください。
<dependency>
<groupId>jp.co.acroquest.acromusashi</groupId>
<artifactId>acromusashi-stream-ml</artifactId>
<version>0.2.3</version>
</dependency>現在は、以下のアルゴリズムをサポートしています。
acromusashi.stream.ml.clustering.kmeans パッケージ配下のコンポーネントを使用することでK-meansアルゴリズムを用いたクラスタリングを行うことができます。
ここでは、学習ストリームとしてファイルから点データを読み込み、評価ストリームからクラスタリング結果を返す例を示します。
// 学習データ読込Spoutを初期化
WatchTextBatchSpout spout = new WatchTextBatchSpout();
// 学習データの配置パスを設定
spout.setDataFilePath("/opt/acromusashi-stream-ml/kmeans/");
// 学習データファイルのベース名称を設定
spout.setBaseFileName("KMeansModel.txt");
// Creatorを初期化
KmeansCreator creator = new KmeansCreator();
// 学習データ生成時の区切り文字を設定
creator.setDelimeter(",");
// InfinispanStateFactoryを初期化
InfinispanKmeansStateFactory stateFactory = new InfinispanKmeansStateFactory();
// In-Memory DBのホストを設定
stateFactory.setServers("192.168.0.1:11222;192.168.0.2:11222;192.168.0.3:11222");
// In-Memory DB上のキャッシュ名称を設定
stateFactory.setCacheName("KMeansCache");
// 学習データのマージ間隔を設定
stateFactory.setMergeInterval(3600);
// In-Memory DB上での学習データの保持期間を設定
stateFactory.setLifespan(86400);
// Updaterを初期化
KmeansUpdater updater = new KmeansUpdater();
// In-Memory DB上のベース名称を設定
updater.setStateName("KMeans");
// クラスタ数を設定
updater.setClusterNum(4);
// 1データ処理するごとに追加処理を行うDataNotifierを設定
DebugLogPrinter<KmeansResult> resultPrinter = new DebugLogPrinter<>("KmeansResult=");
updater.setDataNotifier(resultPrinter);
// 1バッチ処理するごとに追加処理を行うBatchNotifierを設定
DebugLogPrinter<KmeansDataSet> modelPrinter = new DebugLogPrinter<>("KmeansDataSet=");
updater.setBatchNotifier(modelPrinter);
// StateQueryを初期化(In-Memory DB上のベース名称を設定)
KmeansQuery kmeansQuery = new KmeansQuery(stateBaseName);
TridentTopology topology = new TridentTopology();
// 学習Stream
// 以下の順でTridentTopologyにSpout/Functionを登録する。
// 1.TextReadBatchSpout:指定されたファイルを読み込み、1行を1メッセージとして送信
// 2.KmeansCreator:受信したメッセージで受信した文字列を区切り文字で分割し、各要素をdoubleの配列としてKMeansの点を生成し、送信
// 3.KmeansUpdater:受信したKMeansの点のリストを用いて学習モデルを更新し、Infinispanに保存する
TridentState kmeansState = topology.newStream("TextReadBatchSpout", spout)
.each(new Fields("text"), creator, new Fields("kmeanspoint"))
.partitionPersist(stateFactory, new Fields("kmeanspoint"), updater)
.parallelismHint(parallelism);
// 評価Stream
// 1.DRPCStream:DRPCリクエストを受信し、その際に指定された引数をメッセージとして送信
// 2.KmeansCreator:受信したメッセージで受信した文字列を区切り文字で分割し、各要素をdoubleの配列としてKMeansの点を生成し、送信
// 3.KmeansQuery:受信したKmeansの点に対してクラスタリングを行い、下記の情報を結果としてDRPCクライアントに返信
// a.クラスタリングされたクラスタID
// b.クラスタリングされたクラスタIDの中心点
// c.投入したデータと中心点の距離
topology.newDRPCStream("KMeans")
.each(new Fields("args"), creator, new Fields("instance"))
.stateQuery(kmeansState, new Fields("instance"), kmeansQuery, new Fields("result"));
// Topology内でTupleに設定するエンティティをシリアライズ登録
this.config.registerSerialization(KmeansPoint.class);教師なし学習を行う主要なコンポーネントには、以下のようなものがあります。
| クラス | 説明 |
|---|---|
| KmeansCreator | テキストデータを変換し、K-meansクラスタリング用のエンティティに変換します。 |
| KmeansUpdater | K-meansクラスタリングの学習データをIn-Memory DBから取得して教師なし学習を行い、結果をIn-Memory DBに保存します。 |
| KmeansQuery | K-meansクラスタリングの学習データをIn-Memory DBから取得してクラスタリングを行い、結果を評価ストリームに返します。 |
acromusashi.stream.ml.anomaly.lof パッケージ配下のコンポーネントを使用することでLOFアルゴリズムを用いた外れ値検出を行うことができます。
ここでは、学習ストリームとしてファイルから点データを読み込み、評価ストリームから外れ値スコアの算出を行う例を示します。
// 状態マージ用設定生成
Map<String, Object> mergeConfig = new HashMap<>();
// 中間データ保持フラグを設定
mergeConfig.put(LofConfKey.HAS_INTERMEDIATE, true);
// K値を設定
mergeConfig.put(LofConfKey.KN, 10);
// 最大で保持する過去データ数を設定
mergeConfig.put(LofConfKey.MAX_DATA_COUNT, 300);
// 学習データ読込Spoutを初期化
TextReadBatchSpout spout = new TextReadBatchSpout();
// 学習データの配置パスを設定
spout.setDataFilePath("/opt/acromusashi-stream-ml/lof/");
// 学習データファイルのベース名称を設定
spout.setBaseFileName("LOFModel.txt");
// 学習データの再読み込みを行うかのフラグを設定
spout.setFileReload(true);
// 学習データのバッチサイズを設定
spout.setMaxBatchSize(100);
// Creatorを初期化
LofPointCreator creator = new LofPointCreator();
// 学習データ生成時の区切り文字を設定
creator.setDelimeter(",");
// InfinispanStateFactoryを初期化
InfinispanLofStateFactory stateFactory = new InfinispanLofStateFactory();
// In-Memory DBのホストを設定
stateFactory.setTargetUri("192.168.0.1:11222;192.168.0.2:11222;192.168.0.3:11222");
// In-Memory DB上のキャッシュ名称を設定
stateFactory.setTableName("LOFCache");
// 学習データのマージ間隔を設定
stateFactory.setMergeInterval(300);
// In-Memory DB上での学習データの保持期間を設定
stateFactory.setLifespan(3600);
// 状態マージ用設定を設定
stateFactory.setMergeConfig(mergeConfig);
// LofUpdaterを初期化
LofUpdater updater = new LofUpdater();
// データを受信した際に学習モデルの常時アップデートを行うかのフラグを設定
updater.setAlwaysUpdateModel(false);
// 中間データ保持フラグを設定
updater.setHasIntermediate(true);
// データを受信した際に学習モデルのアップデートを行う間隔を設定
updater.setUpdateInterval(100);
// K値を設定
updater.setKn(10);
// 判定を行う際に必要となる最小データ数を設定
updater.setMinDataCount(10);
// 最大で保持する過去データ数を設定
updater.setMaxDataCount(300);
// In-Memory DB上のベース名称を設定
updater.setStateName("Lof");
// 1データ処理するごとに追加処理を行うDataNotifierを設定
LofResultPrinter printer = new LofResultPrinter(threshold);
updater.setDataNotifier(printer);
// 1バッチ処理するごとに追加処理を行うBatchNotifierを設定
LofModelPrinter modelPrinter = new LofModelPrinter();
updater.setBatchNotifier(modelPrinter);
// StateQueryを初期化(In-Memory DB上のベース名称、K値、中間データ保持フラグを設定)
LofQuery lofQuery = new LofQuery("Lof", 10, true);
TridentTopology topology = new TridentTopology();
// 学習Stream
// 以下の順でTridentTopologyにSpout/Functionを登録する。
// 1.TextReadBatchSpout:指定されたファイルを読み込み、1行を1メッセージとして送信
// 2.LofPointCreator:受信したメッセージで受信した文字列を区切り文字で分割し、各要素をdoubleの配列としてLOFの点を生成し、送信
// 3.LofUpdater:受信したLOFの点のリストを用いて学習モデルを更新し、Infinispanに保存する
TridentState lofState = topology.newStream("TextReadBatchSpout", spout)
.each(new Fields("text"), creator, new Fields("lofpoint"))
.partitionPersist(stateFactory, new Fields("lofpoint"), updater)
.parallelismHint(parallelism);
// 評価Stream
// 1.DRPCStream:DRPCリクエストを受信し、その際に指定された引数をメッセージとして送信
// 2.LofPointCreator:受信したメッセージで受信した文字列を区切り文字で分割し、各要素をdoubleの配列としてLOFの点を生成し、送信
// 3.LofQuery:受信したLOFの点に対してスコア算出を行い、結果をDRPCクライアントに返信
topology.newDRPCStream("lof")
.each(new Fields("args"), creator, new Fields("instance"))
.stateQuery(lofState, new Fields("instance"), lofQuery, new Fields("result"));
// Topology内でTupleに設定するエンティティをシリアライズ登録
this.config.registerSerialization(LofPoint.class);
this.config.registerSerialization(Date.class);外れ値検出を行う主要なコンポーネントには、以下のようなものがあります。
| クラス | 説明 |
|---|---|
| LofPointCreator | テキストデータを変換し、LOF判定用のエンティティに変換します。 |
| LofUpdater | LOFの学習データをIn-Memory DBから取得して外れ値検出を行い、結果をIn-Memory DBに保存します。 |
| LofQuery | LOFの学習データをIn-Memory DBから取得して外れ値検出を行い、結果を評価ストリームに返します。 |
acromusashi.stream.ml.anomaly.cf パッケージ配下のコンポーネントを使用することでChangeFinderアルゴリズムを用いた変化点検出を行うことができます。
ここでは、Apacheのログを解析し、レスポンスタイムの異常を検知する例を示します。
// TridentKafkaSpoutを初期化
// Kafkaの接続先ZooKeeperのサーバアドレスとZooKeeper上のパスを定義
ZkHosts zkHosts = new ZkHosts("192.168.0.1:2181,192.168.0.2:2181,192.168.0.3:2181", "/brokers");
// Kafka上のTopic(キュー名称)と利用者IDを定義
TridentKafkaConfig kafkaConfig = new TridentKafkaConfig(zkHosts, "ApacheLog", "ChangeFindTopology");
// デシリアライズ方式を設定
kafkaConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
OpaqueTridentKafkaSpout tridentKafkaSpout = new OpaqueTridentKafkaSpout(kafkaConfig);
// ApacheLogSplitFunctionを初期化
ApacheLogSplitFunction apacheLogSplitFunction = new ApacheLogSplitFunction();
// 読みこむ際の時刻フォーマットを指定
apacheLogSplitFunction.setDateFormatStr("yyyy-MM-dd'T'HH:mm:SSSZ");
// ChangeFindFunctionを初期化
ChangeFindFunction cfFunction = new ChangeFindFunction();
// 自己回帰モデルの次数「k」を設定
cfFunction.setArDimensionNum(4);
// オンライン忘却パラメータ「r」を設定
cfFunction.setForgetability(0.05d);
// 平滑化ウィンドウサイズ「T」を設定
cfFunction.setSmoothingWindow(5);
// 変化点として検出するスコア閾値を設定
cfFunction.setScoreThreshold(15.0d);
TridentTopology topology = new TridentTopology();
// 以下の順でTridentTopologyにSpout/Functionを登録する。
// 1.TridentKafkaSpout:KafkaからApacheログ(JSON形式)を取得
// 2.ApacheLogSplitFunction:受信したApacheログ(JSON形式)をエンティティに変換し、送信
// 3.ChangeFindFunction:受信したApacheログのレスポンスタイムを用いて変化点スコアを算出
// 4.ApacheLogAggregator:受信したApacheログの統計値を算出
// 5.ResultPrintFunction:受信した統計値をログ出力
topology.newStream("TridentKafkaSpout", tridentKafkaSpout).parallelismHint(parallelism)
.each(new Fields("str"), apacheLogSplitFunction, new Fields("IPaddress", "responseTime"))
.groupBy(new Fields("IPaddress"))
.each(new Fields("IPaddress", "responseTime"), cfFunction, new Fields("webResponse"))
.partitionAggregate(new Fields("webResponse"), new CombinerAggregatorCombineImpl(new ApacheLogAggregator()), new Fields("average"))
.each(new Fields("average"), new ResultPrintFunction(), new Fields("count"));
// Topology内でTupleに設定するエンティティをシリアライズ登録
this.config.registerSerialization(ApacheLog.class);変化点検出を行う主要なコンポーネントには、以下のようなものがあります。
| クラス | 説明 |
|---|---|
| ApacheLogSplitFunction | JSON形式で表されているApacheのログデータを取得し、Javaのオブジェクトに変換します。 |
| ChangeFindFunction | Apacheのログのレスポンスタイムに対して変化点検出を行います。 |
| ApacheLogAggregator | Apacheのログの統計を算出します。 |
This software is released under the MIT License, see LICENSE.txt.