詳しい解説はここに載せています。 https://qiita.com/TanakaTakeshikun/items/141ab84b91f33d21f03c
どうも、田中です。 会話する相手が欲しいけどいない時間帯やコーディングしている最中に音声で質問したいときありますよね(きっと僕だけじゃないはず) そこで、タイトルにある通りDiscordでAI(ChatGPT)とボイスチャンネルでずんだもんの音声で会話できるBOTを作ってみようと思います。 GCPやOpenAIのAPIは無料枠があるので今回の記事では基本無料で出来るものとなっています。
無料枠を超える場合は利用料金が発生するのでご注意ください。 また、バージョンにより、この記事とは違う部分が出てくるかもしれませんので、ご注意ください。
今回は僕の得意なJSを使用して書きたいと思います。 APIはDiscord API、Google Cloud Speech API、ChatGPT API、VOICEVOX APIの4つのAPIを使用していきたいと思います。 GCPのKeyFile発行やDiscordのTokenの発行、ChatGPTのKeyの発行方法は以下の記事をお読みください。
- GCP KeyFile発行方法
- Discord Token発行方法
- ChatGPT Key発行方法 また、VOICEVOXをダウンロードする必要があります。以下のサイトからダウンロードを行ってください。
- VOICEVOX WebSite
VOICEVOXが起動していない場合、APIにアクセスができず、音声合成に失敗します。
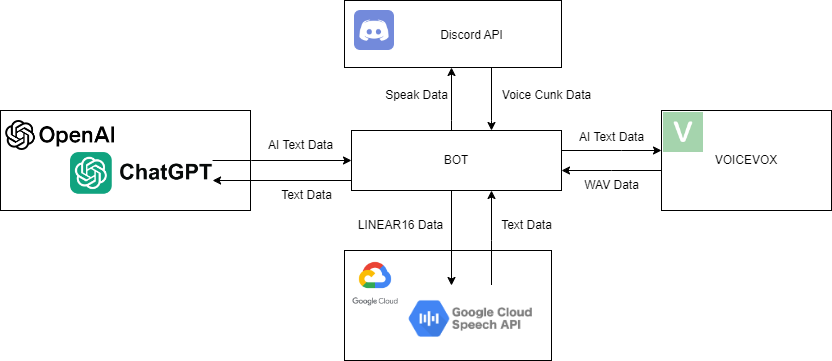
- Dicord APIよりボイスチャンネルのユーザーのボイスのCunk Dataを受け取る。
- LINEAR16に変換して、GCDのSTTにデータを渡す。
- テキストデータが返ってくるので、OpenAIのChatGPTにテキストデータを渡す。
- 回答が返ってくるので、テキストデータをVOICEVOXに送る。
- WAV Dataが返ってくるので、Discord APIに送る。 といった感じです。
Windows:11
NodeJS:19.2.0
Discord.js:14.13.0
@discordjs/opus:0.9.0
@discordjs/voice:0.16.0
@google-cloud/speech:6.0.2
axios:1.5.1
openai:4.13.0
tweetnacl:1.0.3
wav-converter:1.0.0
Sample Package Install Command
npm install [email protected] @discordjs/[email protected] @discordjs/[email protected] @google-cloud/[email protected] [email protected] [email protected] [email protected] [email protected]詳細・DockerfileはGitHubをご覧ください。 Repository
コードを見る
/**
* @constant setting
* @type {{
* rec: {
* SampleRate: number, // 録音のサンプリングレート (Hz)
* ByteRate: number, // 録音のバイトレート (bps)
* MinDataSize: number, // 録音の最小サイズ (byte)
* duration: number // 録音の最大時間 (ms)
* },
* google: {
* keyfile: string, // Google Cloud Platform のキーファイルパス
* projectId: string, // Google Cloud Platform のプロジェクト ID
* MinText: number // Google Speech-to-Text の最小認識テキストの長さ
* },
* voicevox: {
* host: string, // VoiceVox のホスト名
* TextSize: number, // VoiceVox の生成テキストの最大文字数
* speaker: number // VoiceVox の話者ID
* },
* discord: {
* token: string // Discord ボットのトークン
* },
* OpenAi: {
* ApiKey: string, // OpenAI の API キー
* MaxToken: number, // OpenAI の生成テキストの最大文字数
* SystemPrompt: string // AIのキャラ設定
* }
* }}
* @description 設定値。
*/
const setting = {
rec: {
SampleRate: 16000,
ByteRate: 1536000,
MinDataSize: 100000,
duration: 1000
},
google: {
keyfile: 'Key JSON',
projectId: 'Project ID',
MinText: 3
},
voicevox: {
host: 'http://127.0.0.1:50021',
TextSize: 40,
speaker: 3
},
discord: {
token: 'Your Discord Bot Token'
},
OpenAi: {
ApiKey: 'OpenAI API Key',
MaxToken: 500,
SystemPrompt: '小さな女の子'
}
};
//ModuleImport
const { Client, GatewayIntentBits, ActivityType } = require('discord.js');
const { OpusEncoder } = require('@discordjs/opus');
const { createAudioResource, getVoiceConnection, joinVoiceChannel, createAudioPlayer, EndBehaviorType } = require('@discordjs/voice');
const WavConverter = require('wav-converter');
const speech = require('@google-cloud/speech');
const axios = require('axios');
const OpenAI = require('openai');
const DiscordClient = new Client({
intents: [GatewayIntentBits.Guilds, GatewayIntentBits.GuildVoiceStates], rest: 60000
});
//変数設定
let waiting = false;
//GoogleClient設定
const GoogleClient = new speech.SpeechClient({
projectId: setting.google.ProjectId,
keyFilename: setting.google.KeyFileName
});
//OpenAiApi設定
const OpenAiApi = new OpenAI({
apiKey: setting.OpenAi.ApiKey
});
/**
* @function DecodeOpus
* @description Opus ストリームを PCM データに変換します
* @param {OpusStream} OpusStream Opus ストリーム
* @returns {Promise<ArrayBuffer>} PCM データの ArrayBuffer
*/
const DecodeOpus = async OpusStream => {
return new Promise(resolve => {
const opusDecoder = new OpusEncoder(setting.rec.SampleRate, 1, {
bitrate: setting.rec.ByteRate,
});
const pcmData = opusDecoder.decode(OpusStream);
resolve(pcmData);
});
};
/**
* @function RecordingDataProcessing
* @description 録音データをWavに変換します。
* @param {ReadableStream} stream 録音データのストリーム
* @returns {Promise<Buffer>} 処理された録音データの Buffer
*
* @example
* const stream = new ReadableStream();
* const ProcessedData = await RecordingDataProcessing(stream);
*
* @see ReadableStream
* @see WavConverter.encodeWav
*/
const RecordingDataProcessing = async stream => {
const PcmDataArray = await Promise.all(stream);
stream = [];
const ConcatenatedBuffer = Buffer.concat(PcmDataArray);
if (Buffer.from(ConcatenatedBuffer).length <= setting.rec.MinDataSize) return;
const EncodeData = WavConverter.encodeWav(ConcatenatedBuffer, {
numChannels: 1,
sampleRate: setting.rec.SampleRate,
byteRate: setting.rec.ByteRate
});
return EncodeData;
};
/**
* @function GoogleSTT
* @description Google Speech-to-Text APIを使用してWAVデータをテキストに変換します
* @param {Buffer} WavData WAVデータ
* @returns {Promise<string>} 変換されたテキスト
*
* @example
* const wavData = fs.readFileSync('recording.wav');
* const transcription = await GoogleSTT(wavData);
*
* @see GoogleClient.recognize
* @see setting.google.MinText
*/
const GoogleSTT = async WavData => {
const request = {
config: {
encoding: 'LINEAR16',
sampleRateHertz: setting.rec.SampleRate,
languageCode: 'ja-JP'
},
audio: {
content: WavData
}
};
const [response] = await GoogleClient.recognize(request);
const transcription = response.results.map(result => result.alternatives[0].transcript).join('\n');
if (transcription.length <= setting.google.MinText) return;
return transcription;
};
/**
* @function OpenAi
* @description OpenAIを使用して、テキストを生成します
* @param {string} transcript 入力テキスト
* @returns {Promise<string>} 生成されたテキスト
*
* @example
* const transcript = '今日はいい天気ですね。';
* const text = await OpenAi(transcript);
*
* @see OpenAiApi.chat.completions.create
* @see setting.voicevox.TextSize
*/
const OpenAi = async transcript => {
const ChatCompletion = await OpenAiApi.chat.completions.create({
model: 'gpt-3.5-turbo',
max_tokens: setting.OpenAi.MaxToken,
messages: [{ role: 'system', content: setting.OpenAi.SystemPrompt }, { role: 'user', content: `指示:必ず日本語で回答をしてください。\n内容:${transcript}` }],
});
const result = ChatCompletion?.choices[0]?.message?.content;
if (!result) return;
const text = result.slice(0, setting.voicevox.TextSize);
return `${text}`;
};
/**
* @function ReadData
* @description VoiceVoxを使用して、テキストを音声に変換します
* @param {string} text 変換するテキスト
* @returns {Promise<Stream>} 変換された音声のストリーム
*
* @example
* const text = '今日はいい天気ですね。';
* const stream = await ReadData(text);
*
* @see axios
* @see setting.voicevox
*/
const ReadData = async text => {
const audio_query = await axios.post(`${setting.voicevox.host}/audio_query?text=${text}&speaker=${setting.voicevox.speaker}`, {
headers: { 'Content-Type': 'application/json' }
});
const synthesis_response = await axios.post(`${setting.voicevox.host}/synthesis?speaker=${setting.voicevox.speaker}`, audio_query.data, { headers: { 'Content-Type': 'application/json', 'accept': 'audio/wav' }, 'responseType': 'stream' });
if (!synthesis_response.data) return;
return synthesis_response.data;
};
/**
* @function StopProcess
* @description 処理を停止します
* @param {string} text 停止のメッセージを表示します
*
* @example
* const text = '処理を停止しました。';
* await StopProcess(text);
*/
const StopProcess = async text => {
waiting = false;
console.log(text);
};
//DiscordClient
DiscordClient.once('ready', async () => {
DiscordClient.user.setPresence({ activities: [{ name: `会話`, type: ActivityType.Streaming }] });
await DiscordClient.application.commands.set([{ name: 'join', description: 'ボイスチャンネルに接続' }], '');
console.log(`Logged in as ${DiscordClient.user.tag}`);
});
DiscordClient.on('interactionCreate', async interaction => {
if (interaction.commandName === 'join') {
const VoiceChannel = interaction.member.voice.channel;
if (!VoiceChannel) return interaction.reply('ボイスチャンネルに接続してください');
const connection = joinVoiceChannel({
channelId: VoiceChannel.id,
guildId: VoiceChannel.guild.id,
adapterCreator: VoiceChannel.guild.voiceAdapterCreator
});
await interaction.reply('接続しました。');
const player = createAudioPlayer();
connection.subscribe(player);
connection.receiver.speaking.on('start', userId => {
let stream = [];
const audio = connection.receiver.subscribe(userId, {
end: {
behavior: EndBehaviorType.AfterSilence,
duration: setting.rec.duration
}
});
//DataEvent
audio.on('data', chunk => {
const decodedChunk = DecodeOpus(chunk);
stream.push(decodedChunk);
});
//EndEvent
audio.on('end', async () => {
//dicord(RecordingDataProcessing)
if (waiting || !stream[0] || player.state.status === 'playing') return;
waiting = true;
console.log('録音データ処理開始');
const WavData = await RecordingDataProcessing(stream);
if (!WavData) return StopProcess('音声データ処理中断');
console.log('録音データ処理完了');
//GoogleSTT (voice=>text)
console.log('文字化開始');
const transcription = await GoogleSTT(WavData);
if (!transcription) return StopProcess('文字化中断');
console.log('文字化完了');
//BingAi(text=>text)
console.log('回答生成開始');
const text = await OpenAi(transcription);
if (!text) return StopProcess('回答生成中断');
console.log('回答生成完了');
//VOICEVOX(text=>wavbase64)
console.log('音声合成開始');
const AudioData = await ReadData(text);
if (!AudioData) return StopProcess('音声合成中断');
console.log('音声合成完了');
//discord(speak)
const VoiceChannel = getVoiceConnection(interaction.guildId);
if (!VoiceChannel) return waiting = false;
const resource = createAudioResource(AudioData);
player.play(resource);
VoiceChannel.subscribe(player);
audio.destroy();
StopProcess('すべての処理完了');
});
});
};
});
DiscordClient.login(setting.discord.token);
//例外処理
process.on('uncaughtException', error => {
console.error(error);
});各設定、関数について解説していきます。 知りたい箇所の関数名、変数名をクリックして詳細を確認してください。
詳しい返り値などはJSDOCで記述しているのでそちらをご覧ください。
rec
rec: {
SampleRate: 16000,
ByteRate: 1536000,
MinDataSize: 100000,
duration: 1000
}Discordから送られてきた音声データの加工に関する設定項目です。 DecodeOpus関数で使用しているプロパティです。
| Property | 解説 |
|---|---|
| SampleRate | SampleRateとは音声等のアナログ波形をデジタルデータにするために必要な処理であるサンプリングにおいて、単位時間あたりにサンプリングを採る頻度(単位はHz) |
| ByteRate | データの情報量を表す数値で、ビットレートの高さはデータの質(音質)の高さに比例します。(単位はbps) |
| MinDataSize | 検知をする最小のデータサイズです。小さくすることでより、検知しやすくなりますが、リソースを多く使用します。(単位はByte) |
| duration | 検知を終了する(endイベントが発火する)までの時間です。数値が高いほどデータサイズが大きくなりますが、一瞬の無音の時間などで録音が停止しなくなります。(単位はms) |
google: {
keyfile: 'Key JSON',
projectId: 'Project ID',
MinText: 3
}GoogleSTT関数で使用するプロパティです。
| Property | 解説 |
|---|---|
| keyfile | GCPで発行されるjson形式のファイルのファイルパスです。 詳しくはこちらをご覧ください。 Google Cloud Platform の鍵ファイルの作成 |
| projectId | GCPのSTTのプロジェクトがあるプロジェクトのIDです。 詳しくはこちらをご覧ください。 プロジェクトの作成と管理 |
| MinText | STTで生成された文字のうち検知する最小の文字数です。小さくすれば短い言葉でも検知しますが、ChatGPT APIを叩く回数が多くなります。 |
voicevox
voicevox: {
host: 'http://127.0.0.1:50021',
TextSize: 40,
speaker: 3
}ReadData関数で使用するプロパティです。
| Property | 解説 |
|---|---|
| host | VOICEVOX APIが動いてるhostです。ローカル環境で特に設定をしない場合はhttp://127.0.0.1:50021となります。外部でホスティングしてる場合はそのhostを指定してください。 |
| TextSize | 読み上げる最大文字数です。大きくするほど多くの文字を読みますが、VOICEVOXのリソースを多く使用します。 |
| speaker | VOICEVOXの話者IDを入れてください。話者IDの取得はVOICEVOXを起動した状態でVOICEVOXを起動しているhost/speakersにGETリクエストしてください。(3はずんだもんです。) |
discord
discord: {
token: 'Your Discord Bot Token'
},DiscordAPIに接続する際に使用するプロパティです。
| Property | 解説 |
|---|---|
| token | DiscordAPIに接続するためのTokenです。Discord Developerサイトより発行してください。詳しい発行手順はこちらをご覧ください。 DiscordのBot登録・設定・トークンの発行方法 |
OpenAI
OpenAi: {
ApiKey: 'Your OpenAI API Key',
MaxToken: 500,
SystemPrompt: '小さな女の子'
}OpenAi関数で使用されるプロパティです。
| 1 | 2 |
|---|---|
| ApiKey | OpenAIのサイトで作成したAPI Keyを入れてください 作成方法についてはこちらをご覧ください。 OpenAI API の API キーの取得 |
| MaxToken | ChatGPTを使用する際の最大トークン数を設定できます。 詳しい解説はこちらをご覧ください。 OpenAIのAPI料金の計算方法 |
| SystemPrompt | ChatGPTのシステムの設定分です。ユーザーが変えられない物なのでBOT独自の設定を追加できます。 |
DecodeOpus
const DecodeOpus = async OpusStream => {
return new Promise(resolve => {
const opusDecoder = new OpusEncoder(setting.rec.SampleRate, 1, {
bitrate: setting.rec.ByteRate,
});
const pcmData = opusDecoder.decode(OpusStream);
resolve(pcmData);
});
};2chのOpus ストリーム1chで指定のbitrateでPCMデータに変換します。
この際、2chにしてしまうと、この後のSTTの処理の際に2chに対応していないので怒られます。
RecordingDataProcessing
const RecordingDataProcessing = async stream => {
const PcmDataArray = await Promise.all(stream);
stream = [];
const ConcatenatedBuffer = Buffer.concat(PcmDataArray);
if (Buffer.from(ConcatenatedBuffer).length <= setting.rec.MinDataSize) return;
const EncodeData = WavConverter.encodeWav(ConcatenatedBuffer, {
numChannels: 1,
sampleRate: setting.rec.SampleRate,
byteRate: setting.rec.ByteRate
});
return EncodeData;
};Discordの音声ストリーミングの際に発火するdataイベントで得られるchunkデータを配列にしたものを処理し、配列を結合します。 その後、データサイズを比較して、指定したデータサイズ以下の場合は以降処理をしないようにします。
データサイズの指定を小さくすることで小さなデータでも処理されますがほとんどの場合、小さすぎるデータは雑音の場合が多いです。
その後、WavConverterというPackageを使用し、1chで指定のサンプルレートとバイトレートでエンコードします。 この際、レートが高いほうがこの後のSTTの認識が良いような気がします。(ただし、データサイズが大きくなります。)
GoogleSTT
const GoogleSTT = async WavData => {
const request = {
config: {
encoding: 'LINEAR16',
sampleRateHertz: setting.rec.SampleRate,
languageCode: 'ja-JP'
},
audio: {
content: WavData
}
};
const [response] = await GoogleClient.recognize(request);
const transcription = response.results.map(result => result.alternatives[0].transcript).join('\n');
if (transcription.length <= setting.google.MinText) return;
return transcription;
};GCPのSTT APIを利用し、LINEAR16形式で指定のサンプルレートで音声をテキストに変換します。
その後、単語事?配列になって帰ってくるのでmapですべて繋げてあげます。
この時に、指定した文字数以下の場合にはリソース、APIの使用回数削減のため以降処理をしないようにします。
私は日本人なのでlanguageCodeはja-JPしていますが、ほかの言語使用者用に作成する場合はlanguageCodeを変えれば認識するはずです。
STTは音声データの時間によって料金が変わります。詳しくはこちらをご覧ください。 Speech-to-Text の料金 (テスト用で使用する場合は無料枠を超えることはないと思います。)
使ってみて精度はなかなかいいと思います。
詳細はこちらをご覧ください。 Speech-to-Text リクエストの構成
OpenAi
const OpenAi = async transcript => {
const ChatCompletion = await OpenAiApi.chat.completions.create({
model: 'gpt-3.5-turbo',
max_tokens: setting.OpenAi.MaxToken,
messages: [{ role: 'system', content: setting.OpenAi.SystemPrompt }, { role: 'user', content: `指示:必ず日本語で回答をしてください。\n内容:${transcript}` }],
});
const result = ChatCompletion?.choices[0]?.message?.content;
if (!result) return;
const text = result.slice(0, setting.voicevox.TextSize);
return `${text}`;
};Open AIのAPIのChatGPTを利用して、STTで変換されたテキストを元に返答するテキストデータを作成します。
modelは僕自身あまりお金をかけたくないので、3.5にしていますがバージョンが上がった場合は適宜変えたほうがいいかと思います。
tokenについては設定の項目で触れているのでそちらをご覧ください。
roleはsystemとuserがあり、systemはuserより優先される設定です。また、いくつかの回答が返ってくるので、適当に0番目の回答を使用したいと思います。
また、返答がない場合には処理をしないようにします。
その後、生成された返答を指定の文字数以下になるようにします。
ReadData
const ReadData = async text => {
const audio_query = await axios.post(`${setting.voicevox.host}/audio_query?text=${text}&speaker=${setting.voicevox.speaker}`, {
headers: { 'Content-Type': 'application/json' }
});
const synthesis_response = await axios.post(`${setting.voicevox.host}/synthesis?speaker=${setting.voicevox.speaker}`, audio_query.data, { headers: { 'Content-Type': 'application/json', 'accept': 'audio/wav' }, 'responseType': 'stream' });
if (!synthesis_response.data) return;
return synthesis_response.data;
};指定したVOICEVOXのhostにaxiosでPOSTリクエストを送ります。 初めに、クエリを作成するためにテキストとspeakerID(もしかしたらいらないかもしれません)をPOSTします。 次に、返ってきたクエリとspeakerIDをPOSTするとWAVでデータが返ってきます。 他の形式のデータが欲しい場合はresponseTypeを変えれば変更することができます。
StopProcess
const StopProcess = async text => {
waiting = false;
console.log(text);
};処理が止めるときに呼び出す関数です。 waitingをfalseにして、処理待ちを開放します。
trueの場合は新規の処理を停止している状態です。
その後、consoleに止まった理由を表示します。
- moduleが入っている
- VOICEVOXが起動している
- VOICEVOXのhostが合っている
- GCPのkeyfileのパスが合っている
- GCPのプロジェクトIDがあっている(別のプロジェクトを見ていない)
- GCPの利用上限に達していない
- OpenAIのAPIの利用上限に達していない
- openAIのkeyが合っている
- DiscordのTokenが合っている
- Discord DevloperサイトでDiscord APIのIntentsが許可されている
- インターネットに接続されている
- 各module、OSなどのバージョンが対応している
- Discord上でマイクがONになっている
- 各APIが落ちていない
今回は、ぼっちでも安心な音声対話できるBOTを作ってみましたが、一番記事を書くのに時間がかかった気がします(笑) そして、いろいろな技術を使うことで自身のスキルアップにもつながったと思っています。(していてくれ) この記事に関して間違っている点や、説明不足な点をコメントで書いてくれると助かります。 また、わからないところや分かりにくいところ言ってもらえればできる限りお答えしようと思います。 受験頑張るぞー いいねとストックお願いします! GitHubの方もStarをお願いします! GitHub
記事の依頼もお待ちしております。
https://zenn.dev/ss_2013/articles/ab3dfd73513afb
https://www.g-angle.co.jp/blog/narration/bit-depth-sampling-rate-and-sound-quality/
https://cloud.google.com/resource-manager/docs/creating-managing-projects?hl=ja
https://platform.openai.com/docs/introduction
https://dot-blog.jp/news/discord-bot-token/
https://book.st-hakky.com/data-science/open-ai-create-api-key/
https://zenn.dev/umi_mori/books/chatbot-chatgpt/viewer/how_to_calculate_openai_api_prices
https://cloud.google.com/speech-to-text/pricing?hl=ja
https://cloud.google.com/speech-to-text/docs/speech-to-text-requests?hl=ja
https://old.discordjs.dev/#/docs/discord.js/main/general/welcome
参考になりました!ありがとうございます!