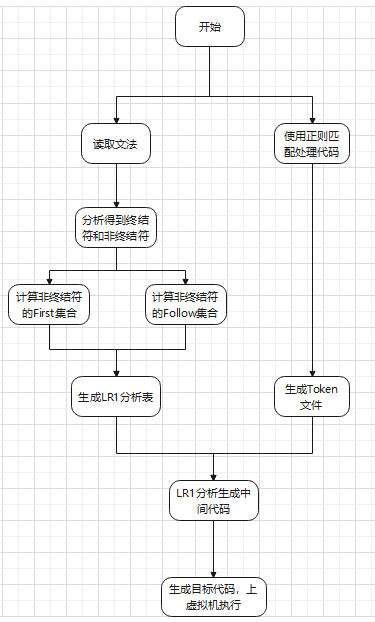
将项目文件克隆到本地,在主程序 PL0Compiler 中,首先执行函数生成所有代码的词法分析结果和语法、语义分析结果,
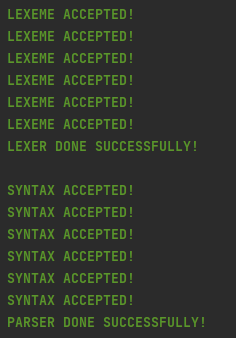
应该会有如下输出:
然后,修改参数 parser_output_file_ 执行你的目标程序,例如,想要执行文件 PL0_code0.out,则修改:
parser_output_file_ = os.path.join(parser_output_dir, "PL0_code0.out")
然后执行:
应该会有如下结果:
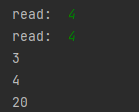
它读入两个数,将其分别输出,并输出一个数 20。
如果你想要生成 LR1 分析表的可视化 UI,执行如下函数:

它应该会有如下输出:
├── PL0Compiler
├── Lexer // 词法分析器
│ ├── LexerInput // 词法分析输入文件,保存的是PL0源代码
│ │ ├── PL0_code0.in // 可以自定义后缀为.in的PL0代码
│ │ ├── PL0_code1.in
│ │ ├── PL0_code2.in
│ │ ├── PL0_code3.in
│ │ ├── PL0_code4.in
│ ├── LexerOutput // 词法分析输出文件,保存的是Token序列
│ │ ├── PL0_code0.out
│ │ ├── PL0_code1.out
│ │ ├── PL0_code2.out
│ │ ├── PL0_code3.out
│ │ ├── PL0_code4.out
│ ├── __init__.py
│ ├── GenToken.py // 生成Token文件的关键函数
│ ├── main.py // 执行以从输入文件夹中读取所有.in文件输出到.out文件
├── Parser // 语法分析器
│ │ ├── LR1Table // 根据文法文件生成LR1分析表
│ │ │ ├── grammars // 文法定义,你可以自己定义文法和代码生成你的LR1分析器
│ │ │ │ ├── grammar.pl0
│ │ │ ├── __init__.py
│ │ │ ├── Grammar.py // 根据文法定义的文件来生成文法对象
│ │ │ ├── LR1Table.py // 构造LR1分析表
│ │ │ ├── LR1TableUI.py // 可视化LR1分析表
│ │ │ ├── GenTable.py // 返回LR1分析表和UI
│ │ │ ├── main.py // 执行以生成LR1分析表的UI
│ │ ├── LR1Analysis // 根据LR1分析表对词法分析的结果进行语法分析
│ │ │ ├── __init__.py
│ │ │ ├── Procedure.py // 过程对象,包含一些嵌套关系的处理
│ │ │ ├── LR1Parser.py // LR1分析器
│ │ │ ├── main.py // 执行以对文法分析的结果进行语法分析,输出中间代码
│ │ ├── ParserOutput // 语法分析的输出结果
│ │ │ ├── PL0_code0.out
│ │ │ ├── PL0_code1.out
│ │ │ ├── PL0_code2.out
│ │ │ ├── PL0_code3.out
│ │ │ ├── PL0_code4.out
│ │ ├── __init__.py
├── Simulator // 虚拟机,执行语法分析生成的中间代码
│ │ │ ├── __init__.py
│ │ │ ├── Machine.py // 定义处理中间代码的方法
| │ │ ├── main.py // 执行以处理中间代码,相当于执行PL0代码
├── __init__.py
├── utils.py // 定义了各输入、输出文件夹的目录,若修改路径请务必修改此文件夹
├── main.py // 执行以对目标文件依次执行词法分析、语法分析、中间代码执行
├── README.md // 相关说明
整个项目中有一些全局使用的变量,它们需要被多次使用,如果分散在各个文件夹中定义,会使功能调试和拓展变得相当困难。因此,将它们定义在根路径下的文件 utils.py 中, 具体包括以下项目:
-
根路径定义:
def get_project_path(): """得到项目路径""" project_path = os.path.join( os.path.dirname(__file__) ) return project_path ‘ root_path = get_project_path() -
词法分析器输入文件定义 :
lexer_input_dir = os.path.join(root_path, "Lexer", "LexerInput") -
词法分析器输出文件定义 :
lexer_output_dir = os.path.join(root_path, "Lexer", "LexerOutput") -
文法输入文件定义:
grammar_file = os.path.join(root_path, "Parser", "LR1Table", "grammars", "grammar2.pl0") -
语法分析器输出文件定义:
parser_output_dir = os.path.join(root_path, "Parser", "ParserOutput") -
栈区空间定义:
call_init_offset = 3在过程调用时,首先在栈中开辟三个空间,存放静态链SL、动态链DL(B)和返回地址RA(P)。
-
中间代码定义:
class Command: def __init__(self, cmd: str, level: int, num: int): self.cmd = cmd self.level = level self.num = num -
中间代码生成器定义:
class Logger: def __init__(self, path: str): self.f = open(path, 'w') self.total_line = 0 self.commands = [] def flush(self): for item in self.commands: self.f.write(item.cmd + ' ' + str(item.level) + ' ' + str(item.num) + '\n') def insert(self, cmd: str, level: int, num: int): self.commands.append(Command(cmd, level, num)) self.total_line += 1 -
debug 模式定义
flag = "not_debug"如果 flag = "debug",则会在控制台进行相应的输出,否则不会进行任何输出。
词法单元在 python 中的出现形式为 list, 含有3个元素, 定义如下:
[KEY, VALUE, ATTACH]
其中,KEY 表示词法单元的键值,可以识别某一词法单元的类型,VALUE 为该词法单元的值,ATTACH 只对 KEY == IDENTIFIER 或 KEY == NUMBER 的词法单元有效,表示其具体的值,对于其它词法单元表示为 -1。
例如,语句 const a=10; 的词法单元如下:
['CONST', 'const', '-1']
['IDENTIFIER', 'id', 'a']
['EQUAL', '=', '-1']
['NUMBER', 'num', '10']
['SEMICOLON', ';', '-1']
语句 a:=b*3+2; 的词法单元如下:
['IDENTIFIER', 'id', 'a']
['ASSIGN', ':=', '-1']
['IDENTIFIER', 'id', 'b']
['TIMES', '*', '-1']
['NUMBER', 'num', '3']
['PLUS', '+', '-1']
['NUMBER', 'num', '2']
['SEMICOLON', ';', '-1']
在 python 中,可以直接使用正则表达式来匹配词法单元,而不需要逐个字符读入 PL/0 源代码,虽然没有体现状态机的思想,但是实际上也达成了 “用一种语言来翻译另一种语言” 的目的,这是 python 的语言特性决定的,如果用 C++ 就需要逐个字符匹配。
使用正则表达式需要注意匹配的顺序,例如应该先匹配关键字 const , while 等,才能匹配关键字 IDENTIFIER ,如果顺序乱了会将关键字匹配成变量。所用的正则表达式定义如下:
ASSIGN = r"(?P<ASSIGN>(:=){1})"
PLUS = r"(?P<PLUS>(\+){1})"
MINUS = r"(?P<MINUS>(\-))"
TIMES = r"(?P<TIMES>(\*))"
DIVIDE = r"(?P<DIVIDE>(\/))"
NEQUAL = r"(?P<NEQUAL>(#))"
LESS_OR_EQUAL = r"(?P<LESS_OR_EQUAL>(<={1}))"
GREATER_OR_EQUAL = r"(?P<GREATER_OR_EQUAL>(>={1}))"
LESS = r"(?P<LESS>(<{1}))"
GREATER = r"(?P<GREATER>(>{1}))"
EQUAL = r"(?P<EQUAL>(=){1})"
LEFT_PARENTHESES = r"(?P<LEFT_PARENTHESES>(\())"
RIGHT_PARENTHESES = r"(?P<RIGHT_PARENTHESES>(\)))"
SEMICOLON = r"(?P<SEMICOLON>(;))"
COMMA = r"(?P<COMMA>(,))"
DOT = r"(?P<DOT>(\.))"
CONST = r"(?P<CONST>(const))"
VAR = r"(?P<VAR>(var))"
PROCEDURE = r"(?P<PROCEDURE>(procedure))"
BEGIN = r"(?P<BEGIN>(begin))"
END = r"(?P<END>(end))"
ODD = r"(?P<ODD>(odd))"
IF = r"(?P<IF>(if))"
THEN = r"(?P<THEN>(then))"
CALL = r"(?P<CALL>(call))"
WHILE = r"(?P<WHILE>(while))"
DO = r"(?P<DO>(do))"
READ = r"(?P<READ>(read))"
WRITE = r"(?P<WRITE>(write))"
IDENTIFIER = r"(?P<IDENTIFIER>([a-zA-Z][a-zA-Z0-9]*))"
NUMBER = r"(?P<NUMBER>([0-9]+))"
匹配的代码定义为:
PATTERMS = [ASSIGN, PLUS, MINUS, TIMES, DIVIDE, GREATER_OR_EQUAL, LESS_OR_EQUAL, EQUAL, NEQUAL, LESS, GREATER,
LEFT_PARENTHESES, RIGHT_PARENTHESES, SEMICOLON, COMMA, DOT, CONST, VAR, PROCEDURE, BEGIN,
END, ODD, IF, THEN, CALL, WHILE, DO, READ, WRITE, IDENTIFIER, NUMBER]
patterns = re.compile("|".join(PATTERMS))
{} 表示出现0次或多次, [] 表示出现一次或不出现;
PL/0 语言文法的 BNF 表示如下:
<程序> -> <分程序>
<分程序> -> [<常量说明部分>][<变量说明部分>][<过程说明部分>]<语句>
<常量说明部分> -> CONST<常量定义>{ ,<常量定义>};
<常量定义> -> <标识符>=<无符号整数>
<无符号整数> -> <数字>{<数字>}
<变量说明部分> -> VAR<标识符>{ ,<标识符>};
<标识符> -> <字母>{<字母>|<数字>}
<过程说明部分> -> <过程首部><分程序>;{<过程说明部分>}
<过程首部> -> procedure<标识符>;
<语句> -> <赋值语句>|<条件语句>|<当型循环语句>|<过程调用语句>|<读语句>|<写语句>|<复合语句>|<空>
<赋值语句> -> <标识符>:=<表达式>
<复合语句> -> begin<语句>{;<语句>}<end>
<条件> -> <表达式><关系运算符><表达式>|odd<表达式>
<表达式> -> [+|-]<项>{<加减运算符><项>}
<项> -> <因子>{<乘除运算符><因子>}
<因子> -> <标识符>|<无符号整数>|(<表达式>)
<加减运算符> -> +|-
<乘除运算符> -> *|/
<关系运算符> -> =|#|<|<=|>|>=
<条件语句> -> if<条件>then<语句>
<过程调用语句> -> call<标识符>
<当型循环语句> -> while<条件>do<语句>
<读语句> -> read(<标识符>{ ,<标识符>})
<写语句> -> write(<标识符>{,<标识符>})
<字母> -> a|b|c…x|y|z
<数字> -> 0|1|2…7|8|9
将其抽象为机器方便处理的表示形式如下:
PROG -> SUBPROG
SUBPROG -> CONST VARIABLE PROCEDURE M_STATEMENT STATEMENT
M_STATEMENT -> ^
CONST -> CONST_ ;
CONST -> ^
CONST_ -> const CONST_DEF
CONST_ -> CONST_ , CONST_DEF
CONST_DEF -> ID = UINT
UINT -> num
VARIABLE -> VARIABLE_ ;
VARIABLE -> ^
VARIABLE_ -> var ID
VARIABLE_ -> VARIABLE_ , ID
ID -> id
PROCEDURE -> PROCEDURE_
PROCEDURE -> ^
PROCEDURE_ -> PROCEDURE_ PROC_HEAD SUBPROG ;
PROCEDURE_ -> PROC_HEAD SUBPROG ;
PROC_HEAD -> procedure ID ;
STATEMENT -> ASSIGN
STATEMENT -> COND
STATEMENT -> WHILE
STATEMENT -> CALL
STATEMENT -> READ
STATEMENT -> WRITE
STATEMENT -> COMP
STATEMENT -> ^
ASSIGN -> ID := EXPR
COMP -> COMP_BEGIN end
COMP_BEGIN -> begin STATEMENT
COMP_BEGIN -> COMP_BEGIN ; STATEMENT
COND -> if CONDITION then M_COND STATEMENT
M_COND -> ^
CONDITION -> EXPR REL EXPR
CONDITION -> odd EXPR
EXPR -> PLUS_MINUS ITEM
EXPR -> EXPR PLUS_MINUS ITEM
EXPR -> ITEM
ITEM -> FACTOR
ITEM -> ITEM MUL_DIV FACTOR
FACTOR -> ID
FACTOR -> UINT
FACTOR -> ( EXPR )
PLUS_MINUS -> +
PLUS_MINUS -> -
MUL_DIV -> *
MUL_DIV -> /
REL -> =
REL -> #
REL -> <
REL -> <=
REL -> >
REL -> >=
CALL -> call ID
WHILE -> while M_WHILE_FORE CONDITION do M_WHILE_TAIL STATEMENT
M_WHILE_FORE -> ^
M_WHILE_TAIL -> ^
READ -> READ_BEGIN )
READ_BEGIN -> read ( ID
READ_BEGIN -> READ_BEGIN , ID
WRITE -> WRITE_BEGIN )
WRITE_BEGIN -> write ( ID
WRITE_BEGIN -> WRITE_BEGIN , ID
| 序号 | 代码 | 说明 |
|---|---|---|
| 1 | OPR 0 0 | 过程结束标识 |
| 2 | OPR 0 1 | 单目运算符:- |
| 3 | OPR 0 2 | + |
| 4 | OPR 0 3 | - |
| 5 | OPR 0 4 | * |
| 6 | OPR 0 5 | / |
| 7 | OPR 0 6 | odd |
| 8 | OPR 0 8 | eq |
| 9 | OPR 0 9 | neq |
| 10 | OPR 0 10 | < |
| 11 | OPR 0 11 | >= |
| 12 | OPR 0 12 | > |
| 13 | OPR 0 13 | <= |
| 14 | OPR 0 14 | write |
| 15 | OPR 0 15 | read |
| 16 | INI 0 volume | 初始化空间,volume为3+var个数 |
| 17 | JMP 0 ADD | 无条件跳转到ADD |
| 18 | LOD LEV OFFSET | 间址取数 |
| 19 | STO LEV OFFSET | 间址存数 |
| 20 | LIT 0 NUM | 取立即数 |
| 21 | JPC 0 ADD | if或while的真出口 |
| 22 | CALL LEV OFFSET | 过程调用 |
词法分析器的代码定义在文件 PL0Compiler/Lexer 中,运行 main.py 会将输入文件夹内的所有 PL0 代码全部进行词法分析,并输出到同级文件夹 LexerOutput 中。词法分析使用了前文提到的正则匹配方法,你也可以自己定义代码,并修改所用的正则匹配式生成相应的词法分析文件。
词法单元包括三个值,token_type,token_value 和 attach。对于大部分词素,都只需要用到前两个属性,例如词素 while 的 type == 'WHLIE', value == 'whlie',但是对于变量名和数字则有特殊,因为它们除了有词法类型、词法值之外,还有对应的字面值,例如词素 var a; 中,词素 a 的词法单元是 [IDENTIFIER id a] ,词素类型及其词法值的匹配关系如下:
mapping = dict()
mapping["ASSIGN"] = ":="
mapping["PLUS"] = "+"
mapping["MINUS"] = "-"
mapping["TIMES"] = "*"
mapping["DIVIDE"] = "/"
mapping["EQUAL"] = "="
mapping["NEQUAL"] = "#"
mapping["LESS"] = "<"
mapping["LESS_OR_EQUAL"] = "<="
mapping["GREATER"] = ">"
mapping["GREATER_OR_EQUAL"] = ">="
mapping["LEFT_PARENTHESES"] = "("
mapping["RIGHT_PARENTHESES"] = ")"
mapping["SEMICOLON"] = ";"
mapping["COMMA"] = ","
mapping["DOT"] = "."
mapping["CONST"] = "const"
mapping["VAR"] = "var"
mapping["PROCEDURE"] = "procedure"
mapping["BEGIN"] = "begin"
mapping["END"] = "end"
mapping["ODD"] = "odd"
mapping["IF"] = "if"
mapping["THEN"] = "then"
mapping["CALL"] = "call"
mapping["WHILE"] = "while"
mapping["DO"] = "do"
mapping["READ"] = "read"
mapping["WRITE"] = "write"
mapping["IDENTIFIER"] = "id"
mapping["NUMBER"] = "num"
一个词法单元的结构定义如下:
class Token:
def __init__(self, token_type, token_value, attach):
self.token_key = token_type
self.token_value = token_value
self.attach = attach
def __str__(self):
return "{type: %s id: %s num: %s}" % (self.token_key, self.token_value, self.attach)
词法分析过程通过循环解析出 PL0 代码路径下的所有源文件,依次将它们读入,然后对每一行代码使用正则表达式匹配生成 Token 列表,并写入到目标输出文件中。
代码文件的命名应该符合 *.in 的格式,输出词法文件会自动命名为 *.out 。
语法分析过程可以使用自顶向下的递归子程序法,根据语法要求生成语法树,也可以使用自底向上的 LL 分析或 LR 分析,本项目中采用的是 LR1 分析,因为这种分析方法更有挑战性。
文法对象定义在文件 Grammar.py 中,成员如下:
class Grammar:
def __init__(self, grammar_str):
self.grammar_str = '\r'.join(filter(None, grammar_str.splitlines()))
self.grammar = {}
self.start = None
self.terminals = set()
self.nonterminals = set()
对于给定的文法,先分割出每一行,对每一行解析出产生式的头和体,产生式的头自动添加到非中介符号中。然后,对于产生式体,再根据其大小写来解析终结符和非终结符,终结符使用小写,非终结符使用大写。
LR1 分析表定义在文件 LR1Table 中,类 LR1Table 接受一个文法对象 G,对该文法生成 LR1 分析表。语法分析过程只和语法定义有关,因此对于任何一个文法,都可以生成一张 LR1 分析表,你可以在文件 grammars/. 下定义自己的文法,并为它生成一张可视化的分析表,例如,对于如下的文法:
S -> E + i
E -> F * F
F -> T + T
E -> i
T -> ^
修改文法路径,运行 main.py ,可以为它生成如下一张 LR1 分析表:
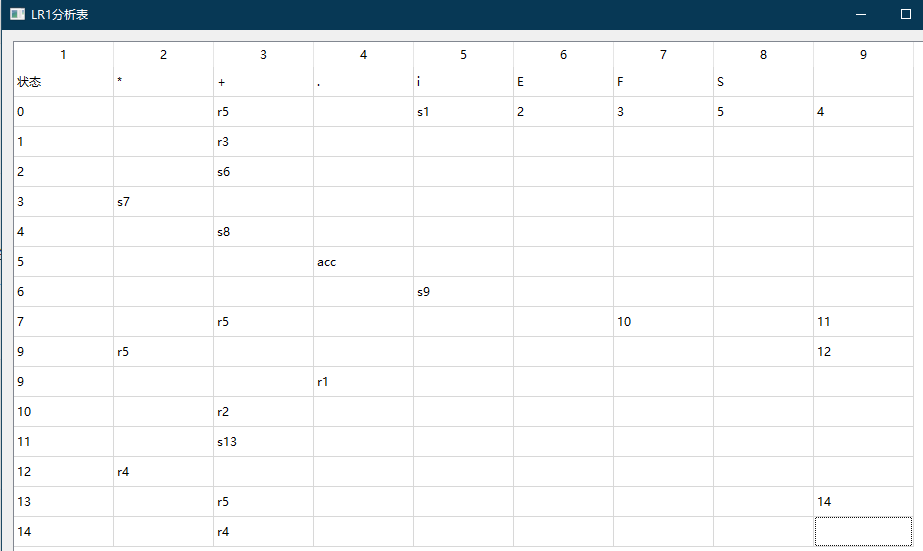
需要注意的是,文法定义中 -> 的两边需要有空格,一个单词隔一个空格。
在对象 LR1Table 中,先将传入的文法规范化,即去除掉符号 | (如果有的话),将文法加入一个产生式,构造扩展文法,然后为文法计算 first 集合和 follow 集合,根据文法对象构造项目集规范族,然后根据 first 集合、follow 集合和项目集规范族来递归地构造 LR1 分析表。
LR1Table 的定义如下:
class LR1Table:
def __init__(self, G):
# 扩展文法
self.G_prime = Grammar(f"{G.start}' -> {G.start}\n{G.grammar_str}")
# 开始符号的长度 + 1
self.max_G_prime_len = len(max(self.G_prime.grammar, key=len))
self.G_indexed = []
# 语法规范化,去除 |
for head, bodies in self.G_prime.grammar.items():
for body in bodies:
self.G_indexed.append([head, body])
# 求 first follow 集合
self.first, self.follow = first_follow(self.G_prime)
# 构建项目集规范族
self.Collection = self.LR1_items(self.G_prime)
# 构建LR1分析表
self.action = sorted(list(self.G_prime.terminals)) + ['.']
self.goto = sorted(list(self.G_prime.nonterminals - {self.G_prime.start}))
self.parse_table_symbols = self.action + self.goto
self.parse_table = self.LR1_construct_table()
文件 ./PL0Compiler/Parser/LR1Analysis/main 中执行了语法分析的具体逻辑,其伪代码如下:
lr1_parser = LR1分析器
input_file = 词法分析输出文件
output_file = 语法分析输出文件
line = input_file.readline()
while line:
# 按行处理词法单元
token = get_token_from_input_file(line)
lr1_parser.process_token(value, token, logger)
line = input_file.readline()
函数 process_token 的伪代码如下:
cmd = 根据LR1分析表得到动作
if cmd == 'acc':
语法分析成功
return True
if not cmd:
语法分析失败
print("\033[0;31m", "ERROR: ", token_, " ", cmd, "\033[0m")
exit(-1)
elif cmd[0] == 's':
执行移入操作
elif cmd[0] == 'r':
执行规约操作
else:
执行goto操作
在语法分析阶段,只需要机械地读入每一个 Token,然后根据 LR1 分析表得到下一步应该执行的操作,维护好状态栈和符号栈并最终到达 LR1 分析表的 acc 状态即可分析成功,如果有语法错误会进行相应的输出,在此阶段不需要对语义进行分析,也即不需要根据代码语义来维护中间代码。
语法分析的调用过程在文件 LR1Parser 中,它维护一个状态栈和符号栈,根据生成的 LR1 分析表来处理词法文件,如果最终定位到表中的 acc 项,则说明分析成功,在每一个阶段都会执行相应的错误输出,目前本代码对一些错误流有了输出提示并会终止代码,但并不是所有的语法错误都能给出提示,可以在此基础上进行拓展,完善本 PL/0 分析器。
语法分析器和语义分析器同属于一个对象 LR1Parser,区别是语法分析只调用了其中的一个模块,语义分析还需要根据词法单元和状态栈确定所用产生式,根据产生式来维护中间代码。
在语法分析的规约阶段执行语义分析,因为只有此时会涉及到产生式和翻译规则的映射,在规约时自底向上进行翻译。
语义分析器的对象定义如下:
class LR1Parser:
def __init__(self, grammar_file_):
# 记录过程调用
self.procedure = Procedure()
self.procedure.add_procedure("_global", 0)
# LR1分析对象
self.lr1_table = LR1Table(Grammar(open(grammar_file).read()))
# LR1分析表
self.parse_table = self.lr1_table.parse_table
# 记录生成的地址
self.global_address_counter = 0
# 状态栈
self.state_stack = [0]
# 符号栈
self.symbol_stack = []
# 输入栈
self.readable_stack = []
在对符号进行规约时,根据 LR1 分析表可以得到所用产生式,根据产生式来定义翻译规则。
假如语句为 const a = 10, b = 20; 所用产生式为:
CONST -> CONST_ ;
CONST_ -> CONST_1 , CONST_DEF1
CONST_1 -> const CONST_DEF2
CONST_DEF1 -> ID = UINT
CONST_DEF2 -> ID = UINT
定义自底向上的翻译规则为:
-
CONST_DEF -> ID = UINT
符号栈栈顶的词法单元为 [id = num],为当前过程保存 const 值,key = stack[top-3].attach,val = stack[top - 1].attach,然后弹出[= num],stack = stack[:-2],栈顶为 [id];
-
CONST_ -> const CONST_DEF
符号栈栈顶的词法单元为 [const id],弹出[id],stack = stack[:-1],栈顶为 [const];
-
CONST_ -> CONST_1 , CONST_DEF1
符号栈栈顶的词法单元为 [const , id],弹出[, id],stack = stack[:-2],栈顶为 [const];
-
CONST -> CONST_ ;
符号栈栈顶的词法单元为 [const ;],弹出[const ;],stack = stack[:-2],栈顶为 [],const 语句分析完毕。
假如语句为 var a, b; 所用产生式为:
VARIABLE -> VARIABLE_ ;
VARIABLE_ -> VARIABLE_ , ID
VARIABLE_ -> var ID
定义自底向上的翻译规则为:
-
VARIABLE_ -> var ID
符号栈栈顶的词法单元为 [var id],弹出[id],stack = stack[:-1],栈顶为 [var];
-
VARIABLE_ -> VARIABLE_ , ID
符号栈栈顶的词法单元为 [var , id],弹出[, id],stack = stack[:-2],栈顶为 [var];
-
VARIABLE -> VARIABLE_ ;
符号栈栈顶的词法单元为 [var ;],弹出[var ;],stack = stack[:-2],栈顶为 [],const 语句分析完毕。
假如语句为:
procedure p1;
procedure p2;
begin
end;
begin
end;
所用产生式为:
PROCEDURE -> PROCEDURE_
PROCEDURE_ -> PROCEDURE_1 PROC_HEAD1 SUBPROG1 ;
PROCEDURE_1 -> PROC_HEAD2 SUBPROG2 ;
PROC_HEAD1 -> procedure ID1 ;
PROC_HEAD2 -> procedure ID2 ;
定义自底向上的翻译规则为:
-
PROC_HEAD -> procedure ID ;
将过程信息写入过程表中,包括过程名字和所在深度。
栈顶的词法单元为 [procedure id ;],stack = stack[:-3],栈顶为 [];
-
PROCEDURE_ -> PROC_HEAD SUBPROG ;
栈顶的词法单元为 [;],stack = stack[:-1],栈顶为 [];
-
PROCEDURE_ -> PROCEDURE_ PROC_HEAD SUBPROG ;
栈顶的词法单元为 [;],stack = stack[:-1],栈顶为 [];
-
PROCEDURE -> PROCEDURE_
栈顶的词法单元为 [begin end],stack = stack[:-2],栈顶为 [],PROCEDURE 语句分析完毕。
假设语句为 a := 10 所用产生式为:
ASSIGN -> ID := EXPR
翻译规则为:
-
ASSIGN -> ID := EXPR
赋值语句右边的值通过规约计算出, 将其赋给变量。需要先寻找变量定义的层次,key = stack[top - 3].attach,找到其定义所属的过程后,生成一条中间代码:
STO level offsetlevel 是过程所嵌套的深度,是为了定位目标过程,offset 是过程中变量的地址。
然后,栈顶的词法单元为 [id := num],stack = stack[:-3],栈顶为 [],ASSIGN 语句分析完毕。
思路为:读取到一个 begin 后,就把 [begin] pop 掉, 规约为状态 COMP_BEGIN,之后每遇到一条带 ; 的语句,就通过产生式规约为 COMP_BEGIN, 直到遇到一条不带 ; 的语句,通过产生式规约为 COMP,如果 ; 之后是end, 则所用产生式为 STATEMENT -> ^。
-
COMP_BEGIN -> begin STATEMENT
栈顶的词法单元为 [begin],stack = stack[:-1],栈顶为 [];
-
COMP_BEGIN -> COMP_BEGIN ; STATEMENT
栈顶的词法单元为 [;],stack = stack[:-1],栈顶为 [];
-
COMP -> COMP_BEGIN end
栈顶的词法单元为 [end],stack = stack[:-1],栈顶为 [],COMP 语句分析完毕。
FACTOR 产生优先级最高的元素,可以是一个变量,一个常数,或一个括号表达式。
-
FACTOR -> ID
首先,需要从当前过程的变量表中去寻找 stack[top - 1].attach 的定义,然后获取该变量的值,生成一条中间代码:
LIT 0 valueLIT 表示 LOAD INT,0 无意义,value 表示变量值;
-
FACTOR -> UINT
直接生成一条中间代码:
LIT 0 stack[top - 1].attach表示直接装入常量的字面值。
-
FACTOR -> ( EXPR )
去除括号, 只留下 EXPR,栈顶为 [( EXPR )],pop 后栈顶为 [EXPR]。
ITEM 是一个次优先级的元素,可以是一个 FACTOR,或乘除表达式。
-
ITEM -> FACTOR
栈顶为一个值,无需操作;
-
ITEM -> ITEM MUL_DIV FACTOR
根据 stack[top - 2].KEY 获取词法单元的类型,可能是 TIMES 或 DIVIDE;
如果是 TIMES,生成一条中间代码:
OPR 0 4OPR 表示 OPERATOR,0 无意义,4 表示乘法操作符;
如果是 DIVIDE,生成一条中间代码:
OPR 0 5OPR 表示 OPERATOR,0 无意义,5 表示除法操作符;
EXPR 是一个优先级最低的元素,可以是一个 ITEM,或加减表达式。
-
EXPR -> ITEM
栈顶为一个值,无需操作;
-
EXPR -> EXPR PLUS_MINUS ITEM
根据 stack[top - 2].KEY 获取词法单元的类型,可能是 PLUS 或 MINUS;
如果是 PLUS ,生成一条中间代码:
OPR 0 3OPR 表示 OPERATOR,0 无意义,3 表示加法操作符;
如果是 MINUS,生成一条中间代码:
OPR 0 2OPR 表示 OPERATOR,0 无意义,2 表示减法操作符;
-
EXPR -> PLUS_MINUS ITEM
单目运算符,用于表示负数,根据 stack[top - 2].KEY 获取词法单元的类型,可能是 PLUS 或 MINUS;
如果是 MINUS,标识负数,生成一条中间代码:
OPR 0 1OPR 表示 OPERATOR,0 无意义,1 表示取负操作符;
如果是 PLUS,什么也不做。
然后,pop 掉栈顶的 + 或 - 符号,stack = stack[:-1]。
-
CALL -> call ID
执行函数调用时,需要先在当前深度下寻找已定义的函数,如果没有,去到自己的父函数中寻找可调用的函数,直到到达根函数。
如果找到合适的函数调用,生成一条中间代码:
CALL LEV_DIFF ADD全局代码的深度是 0,main 函数与和 main 函数平行的函数深度是 1,假设在 main 函数中定义了函数 p1,则 p1 的深度是 2。
LEV_DIFF 是当前过程与目标过程的层次差,如果当前过程调用了内部定义的子过程,则 LEV_DIFF = 0;如果调用了同级过程,则 LEV_DIFF = 1(查表时去父过程的表中查找);如果调用了父过程,则 LEV_DIFF = 2。
过程的地址通过产生式
M_STATEMENT -> ^更新,由于是自底向上的,每当一个过程规约结束后,其中间地址也生成完了,可以回填下一个函数的起始地址。例如,有如下 PL/0 代码:
var a; procedure s; begin a:=12; end; procedure p; procedure p1; procedure p2; begin a:=10; end; procedure p3; begin call s; end; begin call p3; end; begin call p1; write(a); end; begin call p; end.它的函数名与入口地址的映射关系为:
pnam = s padd = 1 pnam = p2 padd = 5 pnam = p3 padd = 9 pnam = p1 padd = 12 pnam = p padd = 15 pnam = _global padd = 20
-
READ -> READ_BEGIN )
栈顶的词法单元为 [)],stack = stack[:-1],栈顶为 [];
-
READ_BEGIN -> read ( ID
栈顶的词法单元为 [read ( id],根据 stack[-1].ATTACH 获取词法单元的值,它就是要写入的变量名,查找到其地址后,生成两条中间代码:
OPR 0 16 STO level offsetOPR 表示 OPERATOR,0 无意义,16 表示读操作符;
level 是过程所嵌套的深度,是为了定位目标过程,offset 是过程中变量的地址。
在执行时,会根据读操作符从输入流读取一个数字,插入到栈顶,然后接着 STO 指令会将其赋给目标变量。
栈顶的词法单元为 [read ( id],stack = stack[:-3],栈顶为 [],分析成功;
-
READ_BEGIN -> READ_BEGIN , ID
和上条产生式的操作一样,可以递归地读入变量。
-
WRITE -> WRITE_BEGIN )
栈顶的词法单元为 [)],stack = stack[:-1],栈顶为 [];
-
WRITE_BEGIN -> write ( ID
栈顶的词法单元为 [write ( id],根据 stack[-1].ATTACH 获取词法单元的值,它就是要输出的变量名或立即数,查找到其地址后,如果是立即数,生成两条中间代码:
LIT 0 VALUE OPR 0 14VALUE 是立即数的值;
OPR 表示 OPERATOR,0 无意义,14 表示写操作符;
如果是变量,生成两条中间代码:
LOD level offsetLOD 是间接寻址,需要根据嵌套深度和偏移量去查找变量的值。
栈顶的词法单元为 [write ( id],stack = stack[:-3],栈顶为 [],分析成功;
-
WRITE_BEGIN -> WRITE_BEGIN , ID
和上条产生式的操作一样,可以递归地输出变量。
-
COND -> if CONDITION then M_COND STATEMENT
此时栈顶为 [if id then JMP],整个 if 已处理完毕,可以回填假出口,假出口的地址就是当前的 curplace ,回填完毕后将栈顶四个元素全部 pop 掉,栈顶为空,if 分析完毕;
-
M_COND -> ^
生成两条中间代码:
JPC 0 curplace + 2 JMP 0 -1JPC 表示条件跳转,真出口为 curplace + 2,如果条件判断为真就从真出口执行,否则就顺序执行,JMP -1 表示假出口,假出口等待条件判断的结果回填。
然后,在符号栈中插入一条词法单元语句:
['NUMBER', 'JMP', 'curplace']curplace 是当前中间代码的指针,它用于回填时寻找目标地址。
**NOTE:**此时表达式已经被规约为 CONDITION ,因此相应的中间代码已经生成,指令
JPC 0 curplace + 2的上一条指令是操作符,再上两条指令是操作符关联的两个式子,在虚拟机中会计算表达式的值为 true 还是 false,然后选择相应的出口跳转。 -
CONDITION -> EXPR REL EXPR
栈顶元素为 [id op id],通过 stack[top - 2] 获得操作符的值,根据操作符的种类生成不同的中间代码:
操作符 中间代码 = OPR 0 8 # OPR 0 9 < OPR 0 10 <= OPR 0 13 > OPR 0 12 >= OPR 0 11 然后 pop 掉栈顶的 [op id],栈顶元素为 [id];
-
CONDITION -> odd EXPR
生成一条中间代码:
OPR 0 6然后 pop 掉栈顶的 [id],栈顶元素为 [odd];
首先用记下代码表分配位置(下一条指令位置),作为循环的开始位置。然后处理while语句中的条件表达式生成相应代码把结果放在栈顶,然后生成条件转移 JPC 指令(遇 0 转移),转移地址未知暂时填0,并记录 JPC 指令的位置。然后调用语句处理过程处理do语句后面的语句或语句块。do后的语句处理完后,最后生成一条无条件跳转指令JMP,跳转到循环开始位置。当前代码表分配的位置就应该是上面的JMP指令的转移位置。通过前面记录下的 JPC 指令的位置,把它的跳转位置改成当前的下一条指令的位置。
-
WHILE -> while M_WHILE_FORE CONDITION do M_WHILE_TAIL STATEMENT
首先,从 stack[-4].ATTACH 得到 whlie 循环的入口地址,然后插入一条中间代码:
JMP 0 VALUE确保循环能够顺利执行;
然后,需要根据当前指令的生成情况回填假出口,通过 stack[-1].ATTACH 获得假出口指令的地址,然后在指令序列中回填修改,最后将栈顶的 5 个元素全部 pop 掉,保持栈顶为 [],这样当前 whlie 语句就分析完毕。
-
M_WHILE_FORE -> ^
在栈中插入一条词法元素:
[NUMBER while_head curplace]它是为了保存 while 的入口地址,在while 结束时插入一条语句跳转到此,从条件判断开始执行,保证 while 能够循环执行。
-
生成两条中间代码:
JPC 0 curplace + 2 JMP 0 -1然后插入一条词法元素用于回填地址:
NUMBER while_tail JMP中间代码的第一条是真出口,第二条是假出口,其回填逻辑和 if 是一样的。
生成的目标代码是一种假想栈式计算机的汇编语言,其格式为(OP,LEV,OFFSET),其中 OP 为功能码,LEV 代表层次差,ADD 代表位移量。语法分析开始后,首先产生第一条指令jmp指令,准备跳转到主程序的开始位置,由于当前还没有知到主程序究竟在何处开始,所以 JMP 的目标暂时填为0。
虚拟机的定义如下:
class Machine:
def __init__(self, code_: [str]):
self.codes = [(x.split(" ")[0].lower(),
int(x.split(" ")[1]),
int(x.split(" ")[2])) for x in code_]
self.stack = []
self.init_counter = []
self.pc = 0
self.base_register = 0
self.codes 是语义分析产生的中间代码,self.stack 中保存的是栈入口,结构体为 StackEntry 模拟了栈内存的分配,self.pc = 0 模拟了程序计数器,按指令顺序来执行目标代码,self.base_register 是基址寄存器,指向当前过程调用所分配的空间在栈中的起始地址,self.init_counter 保存了为每一个过程分配的静态区大小,当过程返回时需要将内存回收。
栈的定义如下:
class StackEntry:
def __init__(self, num: int, hint: str):
self.value = num
self.hint = hint
虚拟机的方法 step 执行一条中间代码,维护自身的栈区和相应的寄存器,根据不同的代码有不同的分析流程,如下定义:
self.pc = cmd[2]
直接修改 pc 寄存器的值到目标指令的地址;
tmp_base = self.base_register
for i in range(cmd[1]):
tmp_base = self.stack[tmp_base].value
self.stack.append(StackEntry(self.stack[tmp_base + cmd[2]].value, 'LOD'))
首先保存当前过程调用所分配的空间在栈中的起始地址,然后根据嵌套的层数到父过程中以及偏移量取变量的值;
tmp_base = self.base_register
for i in range(cmd[1]):
tmp_base = self.stack[tmp_base].value
# 到达目标level后, 根据offset去找变量的地址, 把右值赋给左值
self.stack[tmp_base + cmd[2]] = self.stack[-1]
self.stack[tmp_base + cmd[2]].hint = 'STO'
# pop掉栈顶的右值, 只保存变量的地址
self.stack = self.stack[:-1]
首先保存当前过程调用所分配的空间在栈中的起始地址,然后根据嵌套的层数到父过程中以及偏移量取变量的值;取到后完成赋值操作,pop 掉赋的值;
self.stack.append(StackEntry(cmd[2], 'LIT'))
立即数寻址,直接将立即数添加到栈顶;
if self.stack[-1].value == 0:
self.pc = cmd[2]
self.stack.pop()
如果栈顶元素是 0,就跳转到真出口,否则就不跳转,需要把栈顶的条件表达式 pop 掉;
tmp_base = self.base_register
for i in range(cmd[1]):
tmp_base = self.stack[tmp_base].value
# 静态链,指向定义该过程的直接外过程运行时数据段的基地址
self.stack.append(StackEntry(tmp_base, 'SL'))
# 动态链,指向调用该过程前正在运行过程的数据段的基地址B
self.stack.append(StackEntry(self.base_register, 'DL'))
# 返回地址,记录调用该过程时目标程序的断点
self.stack.append(StackEntry(self.pc, 'RA'))
# 返回地址表入口地址
self.base_register = len(self.stack) - 3
self.pc = cmd[2]
首先保存当前过程调用所分配的空间在栈中的起始地址,然后根据嵌套的层数到父过程中,将静态链和动态链以及返回地址保存好,然后将 pc 直接指向跳转的地址;
for i in range(cmd[2]):
self.stack.append(StackEntry(0, 'INI'))
self.init_counter.append(cmd[2])
根据初始化指令的参数为栈分配空间,并更新 init_counter 的值,方便过程返回时回收空间;
if self.base_register == 0 and self.stack[self.base_register].value == 0:
print("\033[1;32m", "Executed Seccessfully!", "\033[0m")
exit(0)
self.pc = self.stack[self.base_register + 2].value
self.base_register = self.stack[self.base_register + 1].value
self.stack = self.stack[:-self.init_counter[-1]]
self.init_counter.pop()
self.stack = self.stack[:-3]
该语句标志着一个过程调用的结束,如果是主过程结束,则基址寄存器和返回地址都是 0,表示虚拟机运行成功,可以正常退出,否则代表子过程的结束,需要做一些后处理,包括:
- 将
pc恢复到返回地址,下一步执行父过程中的断点; - 将基址寄存器恢复到父过程的基址寄存器;
- 栈空间回收,根据分配的空间大小回收相应的空间;
- 栈空间管理器的回收,弹出回收栈的栈顶元素;
- 静态链、动态链、返回地址这三个地址空间被释放,回到父过程执行剩下的代码。
self.stack[-1].value = -self.stack[-1].value
栈顶元素的值取负数。
self.stack[-2].value = self.stack[-2].value + self.stack[-1].value
self.stack.pop()
加法操作符,将栈顶的两个元素相加赋给栈的第二个元素,然后 pop 掉栈顶元素。
self.stack[-2].value = self.stack[-2].value - self.stack[-1].value
self.stack.pop()
减法操作符,将栈顶的第二个元素减栈顶元素赋给栈顶第二个元素,然后 pop 掉栈顶元素。
self.stack[-2].value = self.stack[-2].value * self.stack[-1].value
self.stack.pop()
乘法操作符,将栈顶的两个元素相乘赋给栈的第二个元素,然后 pop 掉栈顶元素。
self.stack[-2].value = self.stack[-2].value // self.stack[-1].value
self.stack.pop()
除法操作符,将栈顶的第二个元素除以栈顶元素赋给栈顶第二个元素,然后 pop 掉栈顶元素。
self.stack[-1].value = self.stack[-1].value % 2
self.stack[-1].value = 1 - self.stack[-1].value
判断栈顶元素是否为奇数,如果是,则将栈顶元素置 0,否则置 1。
self.stack[-2].value = self.stack[-2].value - self.stack[-1].value
self.stack.pop()
相等判断符,如果栈顶两元素相等,则将栈顶第二个元素置0,否则非0,然后 pop 掉栈顶元素。
self.stack[-2].value = self.stack[-2].value - self.stack[-1].value
if self.stack[-2].value != 0:
self.stack[-2].value = 0
elif self.stack[-2].value == 0:
self.stack[-2].value = 1
self.stack.pop()
不相等判断符,如果栈顶两元素不相等,则将栈顶第二个元素置0,否则非0,然后 pop 掉栈顶元素。
self.stack[-2].value = self.stack[-2].value - self.stack[-1].value
if self.stack[-2].value < 0:
self.stack[-2].value = 0
else:
self.stack[-2].value = 1
self.stack.pop()
< 判断符,如果栈顶第二个元素 < 栈顶元素,则将栈顶第二个元素置 0,否则置 1,然后 pop 栈顶元素。
self.stack[-2].value = - self.stack[-2].value + self.stack[-1].value
if self.stack[-2].value <= 0:
self.stack[-2].value = 0
self.stack.pop()
>= 判断符,如果栈顶第二个元素 >= 栈顶元素,则将栈顶第二个元素置 0,否则置 1,然后 pop 栈顶元素。
self.stack[-2].value = - self.stack[-2].value + self.stack[-1].value
if self.stack[-2].value < 0:
self.stack[-2].value = 0
else:
self.stack[-2].value = 1
self.stack.pop()
> 判断符,如果栈顶第二个元素 > 栈顶元素,则将栈顶第二个元素置 0,否则置 1,然后 pop 栈顶元素。
self.stack[-2].value = self.stack[-2].value - self.stack[-1].value
if self.stack[-2].value <= 0:
self.stack[-2].value = 0
self.stack.pop()
<= 判断符,如果栈顶第二个元素 <= 栈顶元素,则将栈顶第二个元素置 0,否则置 1,然后 pop 栈顶元素。
print(self.stack[-1].value)
self.stack.pop()
write 操作符,打印栈顶元素,然后 pop 掉。
print('now read:')
x = int(input())
self.stack.append(StackEntry(x, 'READ'))
print(self.stack)
read 操作符,输入一个 int 值,将其放到栈顶。
本项目基于 python 语言实现了一个 PL/0 语言的编译器,完成了词法分析、语法分析、语义分析、中间代码生成和虚拟机执行代码的操作,但是也存在几个功能亟待完善:
在词法分析阶段,有些词法错误是可以直接检查出来的,例如将 procedure 写成了 Procedure,将 const a = 3;; 写成了 const a := 3,这些比较明显的错误可以直接检测到并反馈给用户,避免耗费更多的时间来执行语法分析;
对于一个给定的语言文法,其 LR1 分析表是确定的,可以一次计算后将其存到某个文件里面,使用的时候直接读文件代替从头计算 LR1 分析表,这样可以节省很多时间;
本编译器中 LR1 分析器并不是对任何一个 S 文法都能正确分析的,其实现过程涉及到 PL/0 文法本身的约束,实际的 LR1 分析器应该对给定的任何 S 文法都能正确生成分析表;
本项目中中间代码的定义较为随意,可以仿照 x86 或 mips 指令集来定义本项目的中间代码和目标代码;
在本项目中,虚拟机执行的是中间代码,而不是将中间代码转换为目标代码,再执行目标代码,这是因为虚拟机的逻辑是自己定义的,其实现逻辑较为可控,这样做比较简洁,但可以考虑将此步扩展为执行目标代码;
本 PL/0 编译器的虚拟机就是 python 语言本身,其各种逻辑都是用户自定义的,但是真正的执行机涉及到多个寄存器、栈、时序逻辑的控制,没有体现出指令上物理机执行的逻辑;
执行代码时,真正的情况是需要为用户程序分配虚拟地址空间,陷入内核引起上下文切换,但这个模块的拓展需要对操作系统有深刻的理解;
理论上,在同一套中间代码的定义下,修改所需要编译的语言需要修改语义分析过程,因此应该能够方便地使用本编译器来编译其它语言,例如 C 语言,可以拓展编译 C 语言的功能。
从头实现一个编译器是一个非常漫长且耗时耗力的过程,阅读和学习现有的源代码是很好的学习方式,本项目也参考了很多现成的 PL0 编译器源代码,如果你实现了以上的某一个功能,请提交 PR,成为项目的贡献者,共同打造一个功能完善的编译器供后来的学习者学习!