머신러닝 스터디 week2


- Cost를 최소화하는 방법은?


- 그림을 보면 cost(W)가 최소인 지점을 기준으로 오른쪽은 기울기가 양수, 왼쪽은 기울기가 음수이다.
- 따라서 W에서 기울기를 빼주면, 결국 W가 점차 cost(W)가 최소가 되는 지점으로 움직이는것을 알 수 있다.
- GradientDescent 알고리즘을 사용할 때 기울기에 곱해주는 상수
- 빼주는 기울기 값이 너무 크게 되면 다음과 같은 문제가 발생한다.
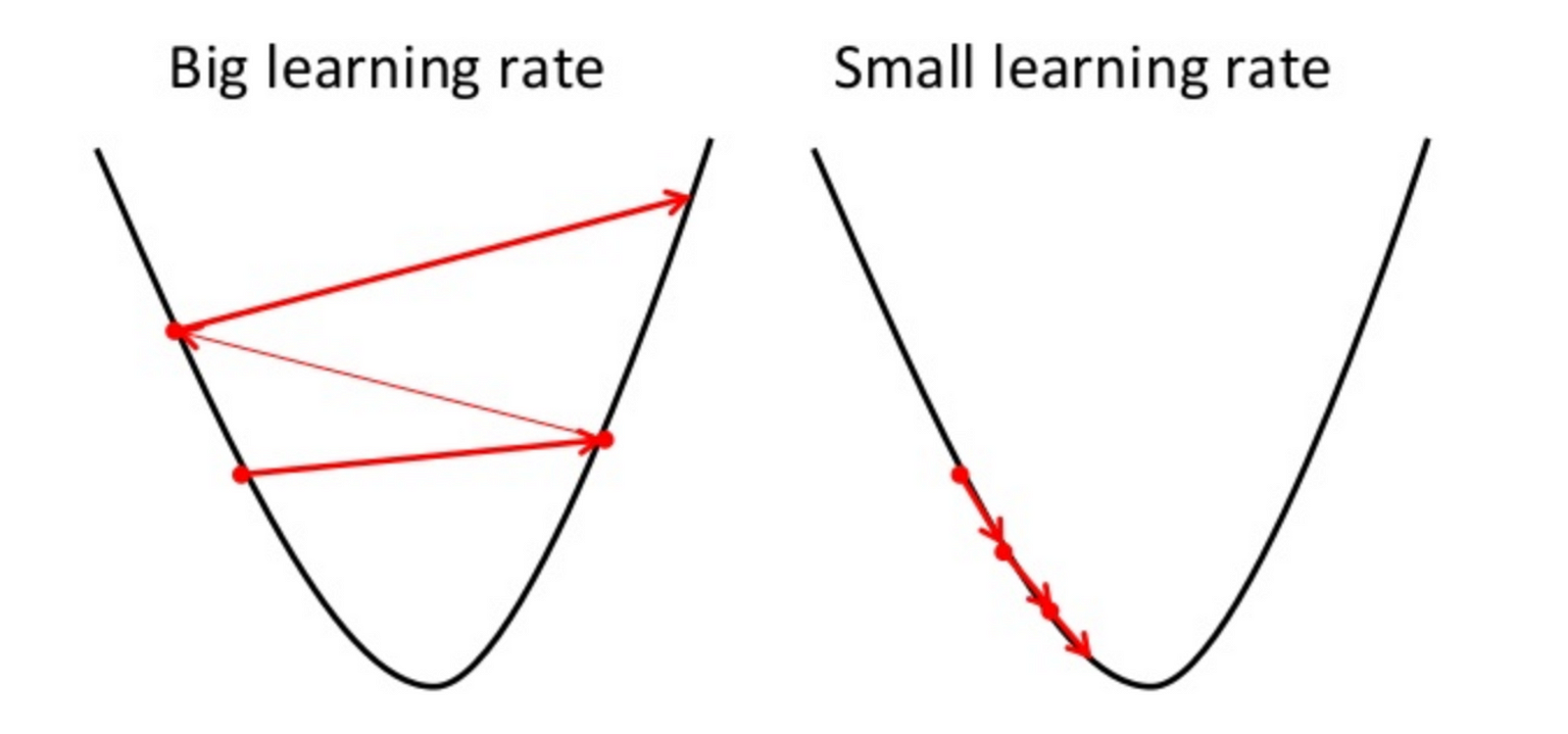
- 너무 작게 되면 cost(W)가 최소가 되는 W 지점으로 수렴하는데 너무 오랜 시간이 걸리므로 적절한 Learning Rate를 설정 하는 것이 중요하다.



- 볼록 함수가 아닌 경우, 위의 그림 처럼 시작하는 지점에 따라서 수렴하는 지점이 달라질 수 있으므로 사용할 수 없다.
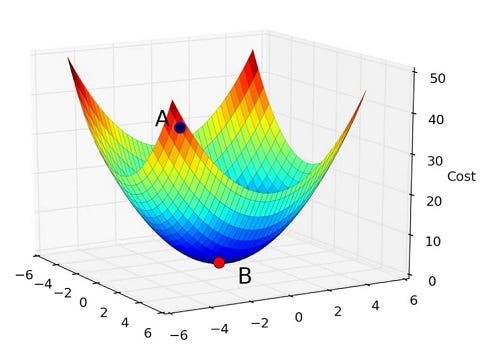
- 위의 그림처럼 볼록 함수일때만 어느 지점에서 출발하던 같은 지점으로 수렴해 같은 결과를 얻을 수 있다.
- 변수를 더 추가하면 된다.

- 변수를 더 추가만 하면 되지만, 수가 너무 많아질 경우 프로그램에 불필요한 코드가 많아지게 되므로 행렬을 사용한다.

import tensorflow as tf
import matplotlib.pyplot as plt
X = [1, 2, 3]
Y = [1, 2, 3]
W = tf.placeholder(tf.float32)
# Our hypothesis for linear model X * W
hypothesis = X * W
# cost/loss function
cost = tf.reduce_mean(tf.square(hypothesis - Y))
# Launch the graph in a session.
sess = tf.Session()
# Initializes global variables in the graph.
sess.run(tf.global_variables_initializer())
# Variables for plotting cost function
W_val = []
cost_val = []
for i in range(-30, 50):
feed_W = i * 0.1
curr_cost, curr_W = sess.run([cost, W], feed_dict={W: feed_W})
W_val.append(curr_W)
cost_val.append(curr_cost)
# Show the cost function
plt.plot(W_val, cost_val)
plt.show()import tensorflow as tf
x_data = [1, 2, 3]
y_data = [1, 2, 3]
W = tf.Variable(tf.random_normal([1]), name='weight')
X = tf.placeholder(tf.float32)
Y = tf.placeholder(tf.float32)
# Our hypothesis for linear model X * W
hypothesis = X * W
# cost/loss function
cost = tf.reduce_sum(tf.square(hypothesis - Y))
# Minimize: Gradient Descent using derivative: W -= learning_rate * derivative
learning_rate = 0.1
gradient = tf.reduce_mean((W * X - Y) * X)
descent = W - learning_rate * gradient
update = W.assign(descent)
# Launch the graph in a session.
sess = tf.Session()
# Initializes global variables in the graph.
sess.run(tf.global_variables_initializer())
for step in range(21):
sess.run(update, feed_dict={X: x_data, Y: y_data})
print(step, sess.run(cost, feed_dict={X: x_data, Y: y_data}), sess.run(W))import tensorflow as tf
X = [1, 2, 3]
Y = [1, 2, 3]
# Set wrong model weights
W = tf.Variable(5.)
# Linear model
hypothesis = X * W
# Manual gradient
gradient = tf.reduce_mean((W * X - Y) * X) * 2
# cost/loss function
cost = tf.reduce_mean(tf.square(hypothesis - Y))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01)
# Get gradients
gvs = optimizer.compute_gradients(cost, [W])
# Apply gradients
apply_gradients = optimizer.apply_gradients(gvs)
# Launch the graph in a session.
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for step in range(100):
print(step, sess.run([gradient, W, gvs]))
sess.run(apply_gradients)95 [0.0033854644, 1.0003628, [(0.0033854644, 1.0003628)]]
96 [0.0030694802, 1.0003289, [(0.0030694804, 1.0003289)]]
97 [0.0027837753, 1.0002983, [(0.0027837753, 1.0002983)]]
98 [0.0025234222, 1.0002704, [(0.0025234222, 1.0002704)]]
99 [0.0022875469, 1.0002451, [(0.0022875469, 1.0002451)]]import tensorflow as tf
x1_data = [73., 93., 89., 96., 73.]
x2_data = [80., 88., 91., 98., 66.]
x3_data = [75., 93., 90., 100., 70.]
y_data = [152., 185., 180., 196., 142.]
# placeholders for a tensor that will be always fed.
x1 = tf.placeholder(tf.float32)
x2 = tf.placeholder(tf.float32)
x3 = tf.placeholder(tf.float32)
Y = tf.placeholder(tf.float32)
w1 = tf.Variable(tf.random_normal([1]), name='weight1')
w2 = tf.Variable(tf.random_normal([1]), name='weight2')
w3 = tf.Variable(tf.random_normal([1]), name='weight3')
b = tf.Variable(tf.random_normal([1]), name='bias')
hypothesis = x1 * w1 + x2 * w2 + x3 * w3 + b
# cost/loss function
cost = tf.reduce_mean(tf.square(hypothesis - Y))
# Minimize. Need a very small learning rate for this data set
optimizer = tf.train.GradientDescentOptimizer(learning_rate=1e-5)
train = optimizer.minimize(cost)
# Launch the graph in a session.
sess = tf.Session()
# Initializes global variables in the graph.
sess.run(tf.global_variables_initializer())
for step in range(2001):
cost_val, hy_val, _ = sess.run([cost, hypothesis, train],
feed_dict={x1: x1_data, x2: x2_data, x3: x3_data, Y: y_data})
if step % 10 == 0:
print(step, "Cost: ", cost_val, "\nPrediction:\n", hy_val)
import tensorflow as tf
x_data = [[73., 80., 75.], [93., 88., 93.],
[89., 91., 90.], [96., 98., 100.], [73., 66., 70.]]
y_data = [[152.], [185.], [180.], [196.], [142.]]
# placeholders for a tensor that will be always fed.
X = tf.placeholder(tf.float32, shape=[None, 3])
Y = tf.placeholder(tf.float32, shape=[None, 1])
W = tf.Variable(tf.random_normal([3, 1]), name='weight')
b = tf.Variable(tf.random_normal([1]), name='bias')
# Hypothesis
hypothesis = tf.matmul(X, W) + b
# Simplified cost/loss function
cost = tf.reduce_mean(tf.square(hypothesis - Y))
# Minimize
optimizer = tf.train.GradientDescentOptimizer(learning_rate=1e-5)
train = optimizer.minimize(cost)
# Launch the graph in a session.
sess = tf.Session()
# Initializes global variables in the graph.
sess.run(tf.global_variables_initializer())
for step in range(2001):
cost_val, hy_val, _ = sess.run(
[cost, hypothesis, train], feed_dict={X: x_data, Y: y_data})
if step % 10 == 0:
print(step, "Cost: ", cost_val, "\nPrediction:\n", hy_val)import tensorflow as tf
import numpy as np
tf.set_random_seed(777) # for reproducibility
xy = np.loadtxt('data-01-test-score.csv', delimiter=',', dtype=np.float32)
x_data = xy[:, 0:-1]
y_data = xy[:, [-1]]
- 다량의 트레이닝 데이터가 있을 경우, 리스트를 사용하면 모든 데이터를 메모리에 적재해야 하는 문제점이 있다.
- 따라서 데이터를 큐에 넣고 feed에서 데이터를 요구할때 마다 데이터를 돌려주는 방식을 취하고 있다.
import tensorflow as tf
filename_queue = tf.train.string_input_producer(
['data-01-test-score.csv'], shuffle=False, name='filename_queue')
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# Default values, in case of empty columns. Also specifies the type of the
# decoded result.
record_defaults = [[0.], [0.], [0.], [0.]]
xy = tf.decode_csv(value, record_defaults=record_defaults)
# collect batches of csv in
train_x_batch, train_y_batch = \
tf.train.batch([xy[0:-1], xy[-1:]], batch_size=10)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
for step in range(2001):
x_batch, y_batch = sess.run([train_x_batch, train_y_batch])
cost_val, hy_val, _ = sess.run(
[cost, hypothesis, train],
feed_dict={X: x_batch, Y: y_batch})
if step % 10 == 0:
print(step, "Cost: ", cost_val,
"\nPrediction:\n", hy_val)
coord.request_stop()
coord.join(threads)