RGBD image
As we work in a 3D scene, we would like to create 3D images, such as RGBD images, where D is depth. The idea is that text-to-3D models are not great, while text-to-image and image-to-RGBD models work well.
As we will work in a 3D scene, a direct RGBD image generation would be great. Yet I know no model that acheives it greatly, so I created a created a small pipeline of image generation and depth from image generation to circumvent it. In the futur, using a real text-to-RGBD model would be more efficient.
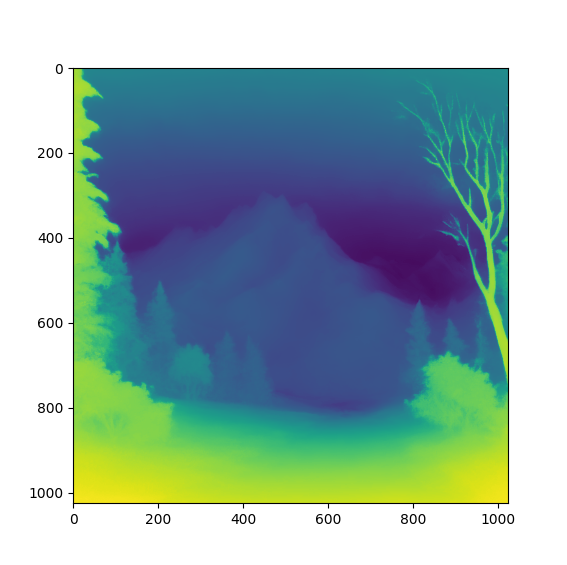
I have tried several models, with a final choice of Marigold. The advantage of this model is that the results are very stable: the depth map does not change a lot when regenerating it, and the "model behavior" is the same from one image to another. The most interesting characteristic of this model is that it always represents the sky with an increasing depth from top-to-bottom, which simplifies the segmentation task greatly.
For the segmentation task, we want to classify voxels between three categories: skybox, terrain and 3D objects (if any). The use of an RGBD image gives great information for the segmentation, especially when compared to direct semantic segmentation on a RGB AI-generated image.
To segment the skybox, we use the following definition: the skybox represents the background. So, we only need to segment the distant voxels, for instance the voxels with D > 80% of maximum depth. Below is is illustration of this selection.

This segment is more complex, as some objects have the same depth as the terrain.
The main idea here is that the terrain has a continuous gradient,
while objects are mostly "flat".
The problem with using a direct vertical gradient is that our data are very noisy,
preventing any segmentation.
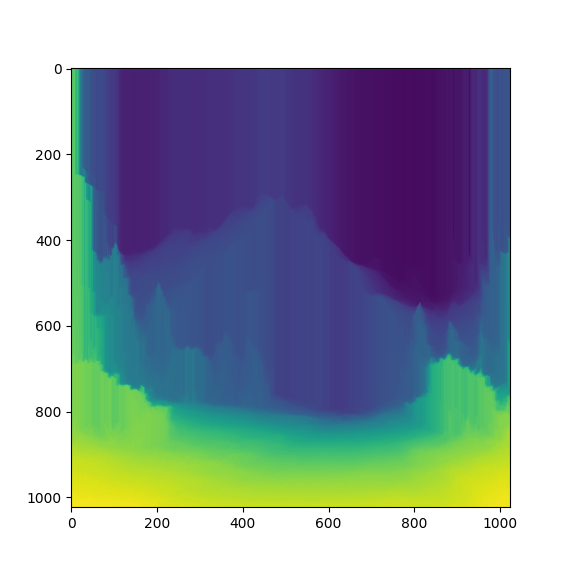
In order to reduce the noise, we first apply a "brushing" of the terrain's depth:
from bottom to top, the depth can only increase.
It generates a "monotonous" depth map:
Then, we compute the vertical gradient:
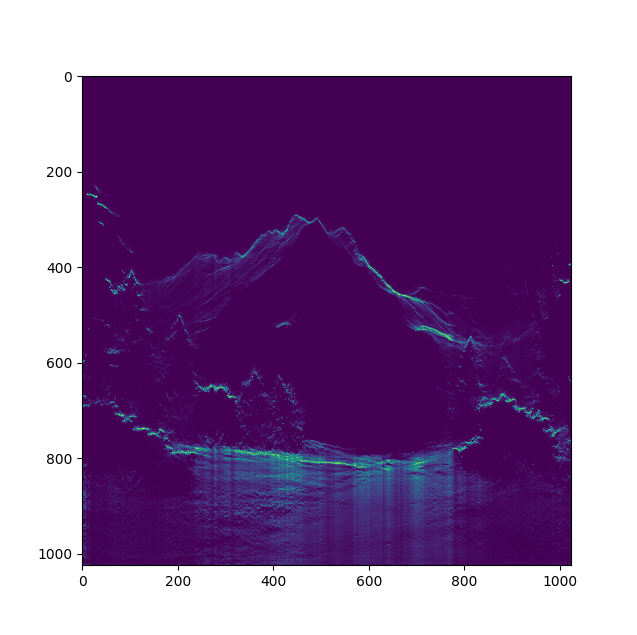
Here, we can start to see the shape of the terrain, and wide areas where the vertical gradient is positive or null.
For each horizontal line, we replace the areas of gradient >= 0 by the mean of the other pixels with striclty negative gradient on this horizontal line.
It gives use a new "completed" depth map, that we call "corrupted" depth.
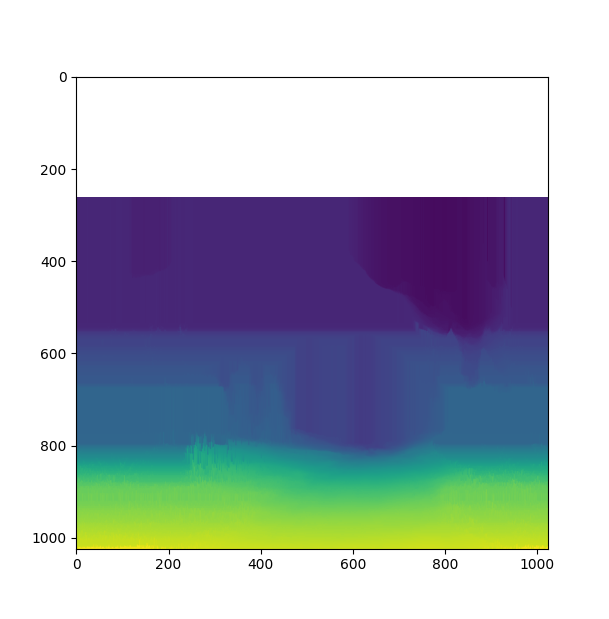
The top white areas is a zone where the gradient is null everywhere, which is normal for the sky. We don't have to fill this area with depth, so it's not an issue.
Now, we have an expected depth reconstruction of the terrain, but not a segmentation of the terrain itself. It is no longer hard, in fact, we just need to substract the "monotonous" depth map (that contain objects depth) by the "corrupted" depth map (without objects). In order to get an absolute difference (not relative to the distance), we also multiply each horizontal line by it's average depth. It gives us an "adherence" depth map where the terrain is clearly isolated.
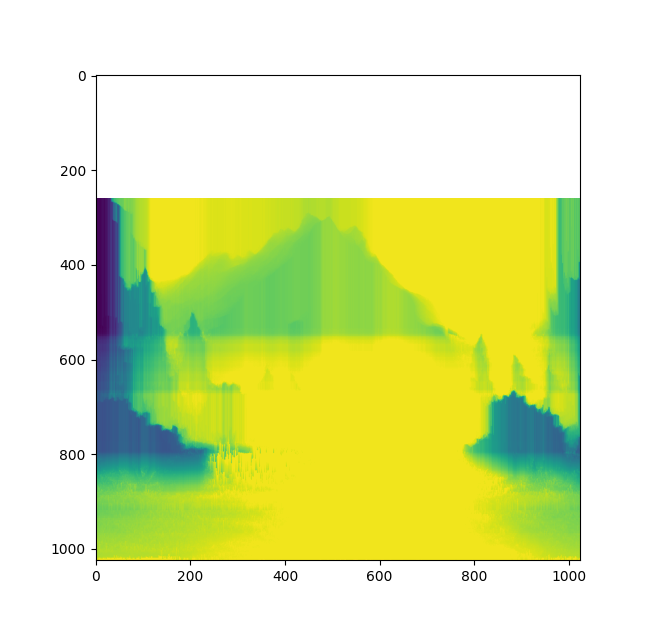
We can only use a thresold on the map to create a binary mask.

Terrain segmentation is achieved!
When the skybox and the terrain are segmented, the 3D elements are what remain.