IBIS is a workflow creation-engine that abstracts the Hadoop internals of ingesting RDBMS data.
![]()
All you need to do is create a request file containing information about a table that you want to query, and IBIS will:
- manage the information required to create the workflow;
- generate Oozie workflows, following current ingestion processes and standards to make the ingestion as performant as possible;
- creates file that simplify the scheduling of the job through automation; and
- allow easy execution of the workflow to populate the Data Lake of the RDBMS source
The IBIS framework wraps the Hadoop stack technology Oozie, an XML-based workflow scheduler system used to manage Apache Hadoop jobs (Oozie Workflow jobs are Directed Acyclical Graphs (DAGs) of actions).
We support creating "config-based" workflows from any of the standard Oozie actions - such as Hive, Shell and Impala. The main use of IBIS is to use SQOOP for efficiently transferring bulk data between Apache Hadoop and structured datastores such as relational databases (including Oracle, Teradata, SQL Server, and DB2).
Refer here on How to setup IBIS?
Creating XMLs is a painful process, especially when including many other steps in the process, such as converting Avro to Parquet, validating data sets, writing to a checks & balances table for auditing, and making views accessible to users. The XMLs also contain code that creates a backup of the previous load's data, in case somethign goes wrong.
IBIS takes care of all of this for you, with the user's input being only one single configuration file, also called the "Request file".
| What | Function | How is this useful? |
|---|---|---|
| Split by | Provides an automated split by for Teradata, SQL Server, and DB2 | Without the automated split by, on a per table basis, you need to find a column that enables parallel execution of an ingestion |
| Auto generating Oozie workflows | Automatically creates XML workflows | No manual XML creation |
| Generate non ingestion workflows through "building blocks" | Given hive and shell scripts, IBIS generates oozie workflow | Automate running any type of script in the Data Lake |
| Group tables based on schedule | Group workflows into subworkflows based on schedule | Tables with similar schedule can be kicked off using Automation by triggering one workflow. |
| Use Parquet | Store data in Parquet | Efficient storage + fast queries! |
| Follows Lambda Architecture | Storing data in the base layer, as immutable data | |
| Allows for data export to any RDBMS | Allows to export data from hive to oracle, db2, sqlserver, mysql, Teradata | For generating reports based on exported data to RDBMS |
| Creates automated incremental workflows | Allows you to incrementally ingest data | Based on a column, generate a where clause data ingestion that will ingest into partitions automatically |
| Data validation | Validate the data was ingested correctly | Row counts, DDL match, data sampling and stores info in a QA log table |
| Map data types to valid Hadoop types | Match, as close as possible, external data types to Hadoop data types | Oracle has specific data types like NUMBER which don't exist in Hadoop. Map to a valid Hadoop type as best as possible (eg to DECIMAL) by grabbing from metadata tables. Other tools map everything directly as string - doesn't work for SAS! |
| Isolated Env - custom ENV | Every different team is having separate team space for all source tables. Workflows can be generated and scheduled without affecting any team. |
Command --help would list the IBIS Functionalities ./ibis-shell --help
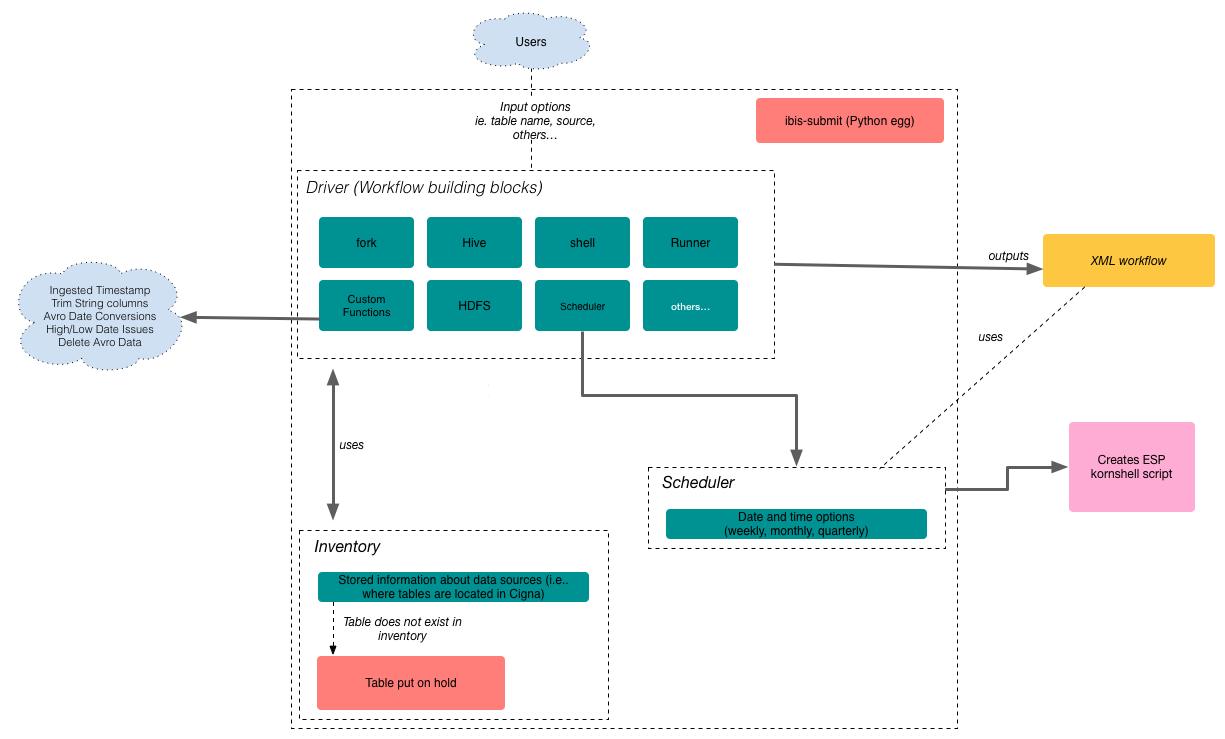
Under the covers, IBIS manages the information required to pull in data sources into HDFS, including usernames, passwords, JBDC connection info, and also keeps track of Automation ids, used for scheduling jobs in Production.
IBIS also has shell that allows you to run your workflow, when it's been created. The goal is to make everything as automated as possible, so many items (workflows, request files) are all resolved around git.
[Request]
split_by:MBR_KEY
mappers:10
jdbcurl:jdbc:teradata://fake.teradata/DATABASE=fake_database
db_username:fake_username
password_file:jceks://hdfs/user/dev/fake.passwords.jceks#fake.password.alias
fetch_size:50000
source_database_name:fake_database
source_table_name:fake_tablename
views:fake_view_open
weight:medium
refresh_frequency:weekly
check_column:TRANS_TIME
db_env:int
| Parameter | Description |
|---|---|
| Split-by | The column used to allow the job to be run in parallel - the best type of column is a primary key or index |
| Mappers | The number of threads that can be used to connect concurrently against the source system. Always check with the DBA on the max number that can be used! |
| JDBC URL | The JDBC URL connection string for the database. See the IBIS Confluence page on specifics for different source systems |
| DB Username | The username that connects to the database |
| Password File | The encrypted password file alias and the location of the JCEKS in HDFS - contact the Big Data team if you're unsure what this is or use the Data Lake 360 Dashboard |
| Fetch Size | The number of batches to pull in at a given time; the default is 50,000. In case of OOM errors, reduce this in 10,000 increments |
| Source Database Name | The name of the database you are connecting to |
| Source Table Name | The name of the table you want to pull in |
| Views | Where you have access to query and manipulate the dataset - if you need it in more than one place, seperate it by a pipe '|' NOTE: this column is append only. To remove all of them, update with null and then add your views. |
| Weight | Provide the size of the table (use your best judgement) on if it's '''light''','''medium''' or '''heavy'''. This is based on the number of columns and the number of rows.This effects how the workflow is generated and the number of tables that can be run in parallel. In the bakend values are translated (100 — light, 010 — medium, 001 — heavy) |
| Refresh Frequency | Only needed for Production, the frequency that is needed. This is used for reporting in checks & balances and other dashboards. All scheduling is physically done through automation. Possible values are none, daily, weekly, monthly, and quarterly |
| Check Column | If you need this table ingested incrementally, provide a check column that is used to split up the load. Note that this only works for some sources right now - check with the team first |
| DB ENV | If you need to run multiple QA cycles then specify the QA cycle name(DEV/CUSTOM-ENV/PROD) the workflows will be created with corresponding filename |
ibis-shell --submit-request <path to requestfile.txt> --env prod
Sample Content of requestfile.txt
[Request]
source_database_name:fake_database <---- db/owner name of table (mandatory)
source_table_name:FAKE_SVC_TABLENAME <---- name of table (mandatory)
db_env:sys <---- env specific (optional)
jdbcurl:jdbc:ora.. <---- JDBC Url (optional)
db_username:fake_username <---- Database username (optional)
password_file:/user/dev/fake.password.file <---- Database password file (optional)
mappers:5 <---- Number of sqoop mappers (optional)
refresh_frequency:weekly <---- if table needs to be on a schedule (optional)
[none, daily, weekly, biweekly, fortnightly, monthly, quarterly, yearly]
weight:heavy <---- load of table (optional)
[small, medium, heavy]
views:fake_view_im|fake_view_open <---- Views (optional)
check_column:TRANS_TIME <---- Column for incremental (optional)
automation_group:magic <---- used for grouping tables in Automation (optional)
fetch_size:50000 <---- sqoop rows fetch size (optional)
hold:1 <---- workflow wont be generated (optional)
split_by:fake_nd_tablename_NUM <---- Used for sqoop import (recommended)
source_schema_name:dbo <---- Sql-server specific schema name (optional)
sql_query:S_NO > 50 AND ID = "ABC" <---- Sqoop import based on custom where clause (optional)
ibis-shell --auth-test --env prod --source-db fake_database --source-table fake_dim_tablename
--user-name fake_username --password-file /user/dev/fake.password.file
--jdbc-url jdbc:oracle:thin:@//fake.oracle:1521/fake_servicename
ibis-shell --export-request-prod <path to requestfile.txt> --env prod
Sample Content of requestfile.txt
[Request]
source_database_name:test_oracle_export <---- db/owner name of table (mandatory)
source_table_name:test_oracle <---- name of table (mandatory)
source_dir:/user/data/mdm/test_oracle/test_oracle_export <---- source dir (optional)
jdbcurl:jdbc:ora... <---- JDBC Url (mandatory)
target_schema:fake_schema <---- Target schema (mandatory)
target_table:test <---- Target table (mandatory)
db_username:fake_username <---- Database username (mandatory)
password_file:/user/dev/fake.password.file <---- Database password file (mandatory)
staging_database:fake_staging_database <---- Staging database for TD (optional)
ibis-shell --run-job table_workflow --env prod
ibis-shell --update-it-table <path to tables.txt> --env prod
Sample Content of tables.txt
[Request]
split_by:CLIENT_STRUC_KEY
mappers:6
jdbcurl:jdbc:teradata://fake.teradata/DATABASE=fake_database # DATABASE= required for teradata
db_username:fake_username
password_file:/user/dev/fake.password.file
refresh_frequency:weekly <---- if table needs to be on a schedule (optional)
[none, daily, weekly, biweekly, fortnightly, monthly, quarterly]
weight:heavy <---- load of table (optional)
[small, medium, heavy]
fetch_size: <---- No value given. Just ignores
hold:0
automation_appl_id:null <---- set null to empty the column value
views:fake_view_im|fake_view_open <---- Pipe(|) seperated values
automation_group:magic_table
check_column:fake_nd_tablename_NUM <---- Sqoop incremental column
source_database_name:fake_database (mandatory)
source_table_name:fake_client_tablename (mandatory)
ibis-shell --view --view-name <view_name> --db <name> --table <name> # Minimum
# OPTIONAL PARAMETERS: --select {cols} , --where {statement}
eg. ibis-shell --view --view-name myview --db mydb --table mytable --select col1 col2 col3 --where 'Country=USA'
ibis-shell --gen-automation-workflows <frequency> # frequency choices['weekly', 'monthly', 'quarterly', or 'biweekly']
ibis-shell --gen-automation-workflow schedule=None database=None jdbc_source=None
# schedule choices - none, daily, biweekly, weekly, fortnightly, monthly, quarterly
jdbc_source choices - oracle, db2, teradata, sqlserver
ibis-shell --save-it-table --source-type sqlserver
To ensure that IBIS can be automatically deployed, has consistency and reliability, unit tests are a must. The development team follows TDD practices. To run unit tests, run the following:
python ibis_test_suite.py
- Source Code: https://github.com/Cigna/ibis
- Issue Tracker: https://github.com/Cigna/ibis/issues
- Matthew Wood
- Bhaskar Teja Yerneni
- Mohammad Quraishi
- IBIS logo artwork by Sam Menza
The project is licensed under the Apache 2 license
▄█ ▀█████████▄ ▄█ ▄████████
███ ███ ███ ███ ███ ███
███▌ ███ ███ ███▌ ███ █▀
███▌ ▄███▄▄▄██▀ ███▌ ███
███▌ ▀▀███▀▀▀██▄ ███▌ ▀███████████
███ ███ ██▄ ███ ███
███ ███ ███ ███ ▄█ ███
█▀ ▄█████████▀ █▀ ▄████████▀