AlvisNLP ML data model
The data structure is responsible of holding corpus contents that are consumed, processed and produced by a sequence of AlvisNLP/ML modules. Module instances can access it through a shared object.
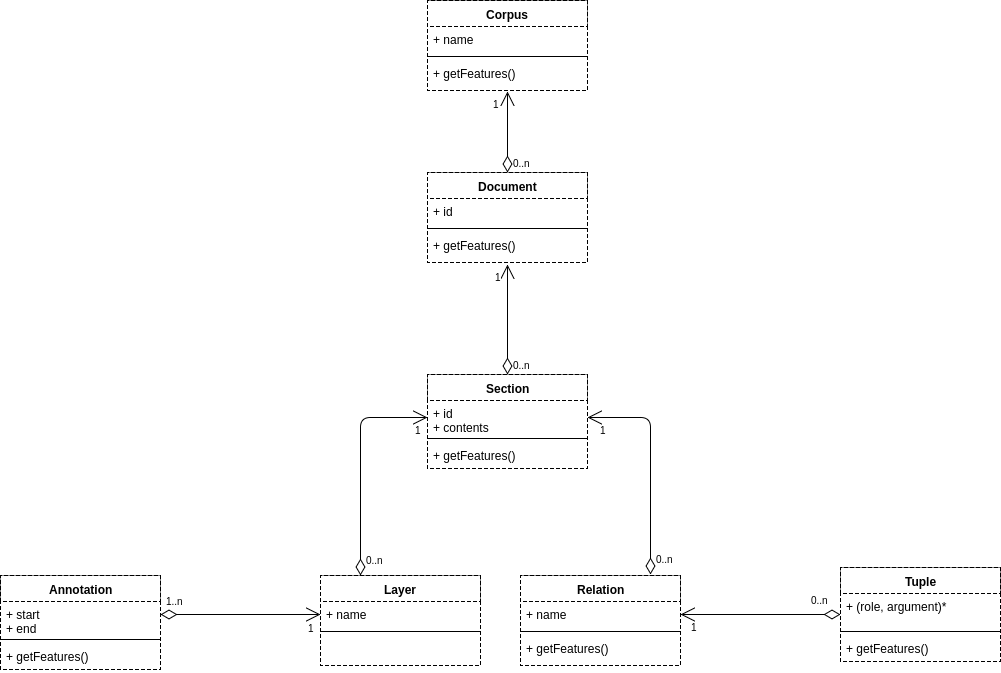
The data structure provides elements that hold the typical information on textual articles (Corpus, Document and Section). It also provides elements to contain annotations, events and features (Annotations, Tuples and Features) and containers consisting of Layers and Relation allow to group information about the elements. The following figure presents an UML-like abstraction of the elements and their composition.
-
Corpus, Documents and Sections respectively serve to contain corpus, documents and sections. A corpus is composed of a set of documents and a document is composed of a list of sections. A section is composed of a text content, a set of layers and a set of relations.
-
Layers and Relations respectively organize annotations and tuples. A layer contains a set of annotations and a Relation contains a set of tuples.
-
Annotations and Tuples contain respectivelly information on text tokens and links between several tokens or between elements. An annotation delimits a token in a text with start and end coordonates. A tuples groups all elements (e.g., annotations, relations) that have link each other. Each tuple express a link that is composed of the role of the link and the element concerned by the link.
-
Features contain information about tags, labels, categories, etc. of an element. Features are
(key, value)variable pairs, where the content of variablekeyis associated to the content of variablevalue. Each element Corpus, Document, Section, Annotation or Tuples has Features. The following example illustrate the usage of the features.-
This feature
("set", "Test"), wherekey="set"andvalue="Test"can be used to tell that a corpus is test set corpus. -
This feature
("pos", "NN"), wherekey="pos"andvalue="NN"can be used to set the part-of-speech of an annotation. -
This feature
("type", "Protein"), wherekey="type"andvalue="Protein"can be used to set a named-entity.
-