{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
ACM Research, Spring 2022

- Table of Contents
- Abstract
- Dataset
- Data Preprocessing
- Model
- Results
- Contributors
Enjoying music remains as one of the most popular recreational activities since time immemorial. Several people devote their entire lives and careers either to performing the art or to studying its various facets. As such, classifying songs and ascribing them with generic tags seems to be an important aspect of studying music. We aim to harness the power of neural networks to analyze sonic characteristics of various kinds of music and create a model to reliably classify songs into genres based on such characteristics.
We devoted a lot of time to find the right dataset. Some were insufficient for our purpose, some were too complex, and some just didn't have enough supporting documentation. We once even contacted the researchers who had put together an 80+ GB dataset of various kinds of music from around the world. This massive dataset was sponsored by the Government of Spain and put together in the University of Madrid. Unfortunately, it had barely any supporting documentation so we scrapped it. In the end, we settled on the highly popular GTZAN dataset because it is fairly representative in terms of its amount of music genres and is very well documented with lots of freely available codebases online utilizing it. The genres available for classification are blues, classical, country, disco, hiphop, jazz, metal, pop, reggae, and rock.
Our team chose to use the mel-frequency cepstrum of our data in the form of mel-frequency cepstral coefficients (MFCCs). The mel-frequency cepstrum (MFC) is a representation of the short-term power spectrum of sound, based on a linear cosine transform of a log power spectrum on a nonlinear mel scale of frequency. MFCCs are the coefficients that collectively make up an MFC. This process is abstracted away by the librosa library, but the way to extract MFCCs from an audio signal is shown below.

The MFCCs of a sample audio clip are shown below.
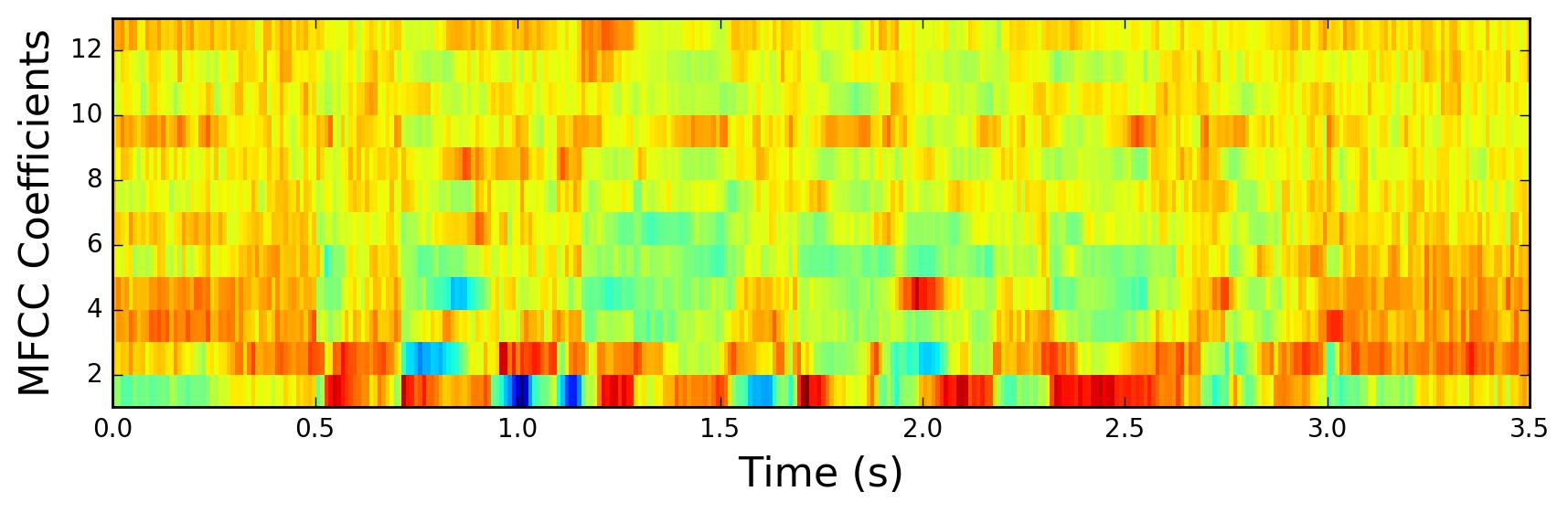
We picked a sample rate of 22050 Hz because it was a good compromise between audio quality loss and convenience. Our sample length for the data was 29 seconds. We then extracted the MFCCs of our samples to a JSON file.
We used the numpy and keras libraries extensively to implement our convolutional neural network (CNN) model.
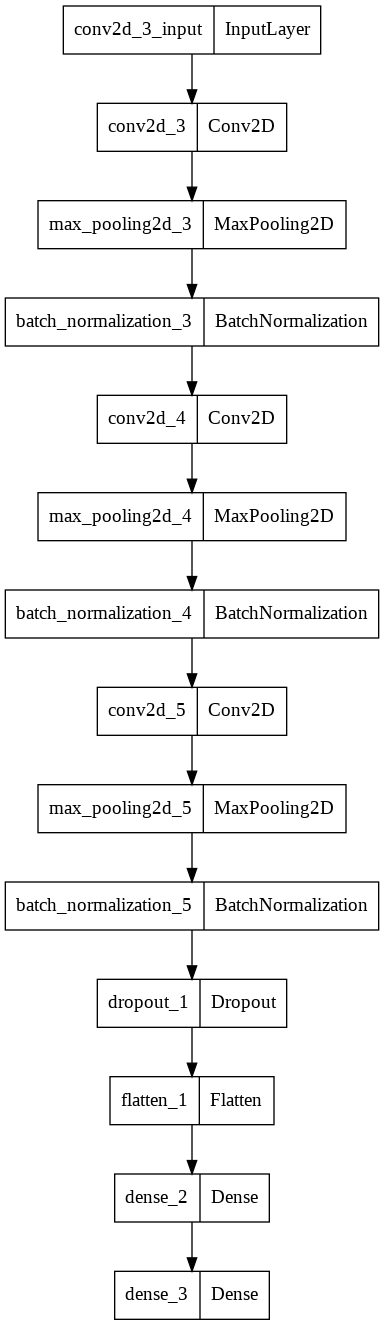
Our model drew on previous example codebases for inspiration. It samples various Kaggle implementations on the GTZAN data-set. After the aforementioned data preprocessing, we associated each sample with its corresponding genre using one-hot encoding. We split the data-set into 3 independent sets: train, validation, and test. Our model is composed of a series of convolutional layers with max pooling layers to reduce dimensionality and batch normalization layers to normalize data to have consistent mean and standard deviation as intermediaries. Finally, a dense layer layer of 64 neurons connects to a final dense layer which outputs predictions for each of the 10 genres in the data set.
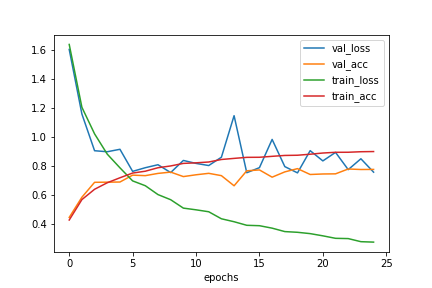
After training the model on the training data, we tested its accuracy on an independent test data-set. Accuracy on the test set was approximately 77.42%.
The training progression is shown below.
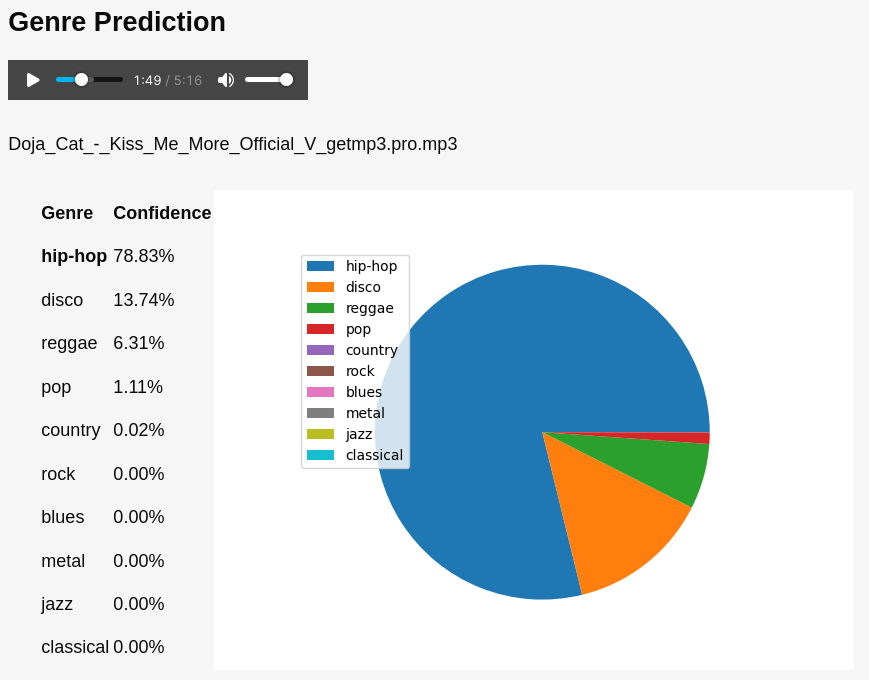
A user-facing demo deployment of our model allowing uploading or downloading audio files can be found at https://acm-music-classification.herokuapp.com/.
Sample output is shown below.
- Agastya Bose
- Ethan Emmanuel
- Jack Myrick
- Zayne Lumpkin
- Megan Vu - Research Lead
- Dr. Feng Chen - Faculty Advisor