diff --git a/docs/source/en/model_doc/m2m_100.md b/docs/source/en/model_doc/m2m_100.md
index fa808c2e94bbfd..449e06ec30c29b 100644
--- a/docs/source/en/model_doc/m2m_100.md
+++ b/docs/source/en/model_doc/m2m_100.md
@@ -121,3 +121,45 @@ Hindi to French and Chinese to English using the *facebook/m2m100_418M* checkpoi
[[autodoc]] M2M100ForConditionalGeneration
- forward
+
+## Using Flash Attention 2
+
+Flash Attention 2 is a faster, optimized version of the attention scores computation which relies on `cuda` kernels.
+
+### Installation
+
+First, check whether your hardware is compatible with Flash Attention 2. The latest list of compatible hardware can be found in the [official documentation](https://github.com/Dao-AILab/flash-attention#installation-and-features).
+
+Next, [install](https://github.com/Dao-AILab/flash-attention#installation-and-features) the latest version of Flash Attention 2:
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+### Usage
+
+To load a model using Flash Attention 2, we can pass the argument `attn_implementation="flash_attention_2"` to [`.from_pretrained`](https://huggingface.co/docs/transformers/main/en/main_classes/model#transformers.PreTrainedModel.from_pretrained). You can use either `torch.float16` or `torch.bfloat16` precision.
+
+```python
+>>> import torch
+>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
+
+>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to("cuda").eval()
+>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M")
+
+>>> # translate Hindi to French
+>>> hi_text = "जीवन एक चॉकलेट बॉक्स की तरह है।"
+>>> tokenizer.src_lang = "hi"
+>>> encoded_hi = tokenizer(hi_text, return_tensors="pt").to("cuda")
+>>> generated_tokens = model.generate(**encoded_hi, forced_bos_token_id=tokenizer.get_lang_id("fr"))
+>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
+"La vie est comme une boîte de chocolat."
+```
+
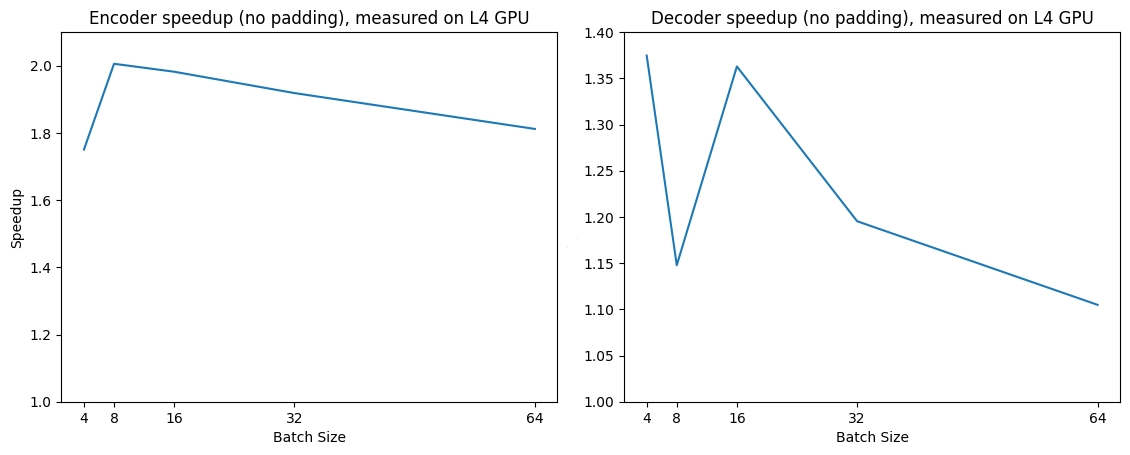
+### Expected speedups
+
+Below is an expected speedup diagram that compares pure inference time between the native implementation and the Flash Attention 2.
+
+
+
+
+
+