| title |
|---|
开箱即用,一键集成 Redis 缓存 |
作者:Tom哥
公众号:微观技术
博客:https://offercome.cn
人生理念:知道的越多,不知道的越多,努力去学
Spring Boot 作为主流微服务框架,拥有成熟的社区生态。市场应用广泛,为了方便大家,整理了一个基于spring boot的常用中间件快速集成入门系列手册,涉及RPC、缓存、消息队列、分库分表、注册中心、分布式配置等常用开源组件,大概有几十篇文章,陆续会开放出来,感兴趣同学可以关注&收藏
Redis 是一个开源、高级的键值存储和一个适用的解决方案,用于构建高性能,可扩展的 Web 应用程序。支持更丰富的数据结构,例如 String、List、hash、 set、 zset 等,同时支持数据持久化。
除此之外,Redis 还提供一些类数据库的特性,比如事务,HA,主从备份。可以说 Redis 兼具了缓存系统和数据库的一些特性。
Redis特性
- 高并发读写
- 持久化
- 丰富的数据类型
- 单进程单线程模型
- 数据自动过期
- 发布订阅
- 分布式
- 支持lua脚本
目前在从阿里巴巴、美团、百度、拼多多、快手等一线大厂到五六线小厂中广泛使用,对系统的高并发能力贡献极大,深受好评,开源社区非常活跃。
1、String
二进制的字符串,最简单的k-v存储,类似于memcached的存储结构,它不仅能够存储字符串、还能存储图片、视频等多种类型, 最大长度512M。支持丰富的操作命令,如:
- GET/MGET
- SET/SETEX/MSET/MSETNX
- INCR/DECR
- GETSET
- DEL
2、Hash
采用主子key存储信息,由field和关联的value组成Map。比如计数器,key表示帖子id,field表示点赞数、评论数、转发数等,value则表示计数值。常用命令:
- HGET/HMGET/HGETALL
- HSET/HMSET/HSETNX
- HEXISTS/HLEN
- HKEYS/HDEL
- HVALS
3、List
该类型是一个有序的元素集合,基于双向链表实现。比较适合存储一些有序且数据相对固定的数据。如省市区表、字典表等。常用命令:
- LPUSH/LPUSHX/LPOP/RPUSH/RPUSHX/RPOP/LINSERT/LSET
- LINDEX/LRANGE
- LLEN/LTRIM
4、Set
Set类型是一种无顺序集合。它和List类型最大的区别是:集合中不允许有重复元素,并且集合中的元素是无序的,不能通过索引下标获取元素。底层是通过哈希表实现的。常用命令:
- SADD/SPOP/SMOVE/SCARD
- SINTER/SDIFF/SDIFFSTORE/SUNION
5、Sorted Set
是set的增强版本,有序集合类型,每个元素都会关联一个double类型的分数权值,通过这个权值来为集合中的成员进行从小到大的排序。与Set类型一样,其底层也是通过哈希表实现的。常用命令:
- ZADD/ZPOP/ZMOVE/ZCARD/ZCOUNT
- ZINTER/ZDIFF/ZDIFFSTORE/ZUNION
1、高性能缓存。缓存现在几乎是所有中大型网站都在用的必杀技,合理的利用缓存不仅能够提升网站访问速度,还能大大降低数据库的压力。Redis提供了键过期功能,也提供了灵活的键淘汰策略,所以Redis用在缓存的场合非常多。
作为缓存使用时,一般有两种方式保存数据:
- 读取前,先去读Redis。如果没有数据,读取数据库,然后将数据预热到Redis。
- 写入时,先更新数据库,然后再写入Redis。
2、丰富的数据类型,满足多样化业务需求。
3、分布式锁
在很多互联网公司中都使用了分布式技术,分布式技术带来的挑战是对同一个资源的并发访问,如全局ID、减库存、秒杀等场景,并发量不大的场景可以使用数据库的悲观锁、乐观锁来实现,但在并发量高的场合中,利用数据库锁来控制资源的并发访问是不太理想的,大大影响了数据库的性能。可以利用Redis的set nx功能来编写分布式锁,如果设置返回1说明获取锁成功,否则获取锁失败。
4、消息队列
Redis 中 list 的数据结构实现是双向链表,所以可以非常便捷的应用于消息队列(生产者 / 消费者模型)。消息的生产者只需要通过 lpush 将消息放入 list,消费者便可以通过 rpop 取出该消息,并且可以保证消息的有序性。如果需要实现带有优先级的消息队列也可以选择 sorted set。而 pub/sub 功能也可以用作发布者 / 订阅者模型的消息。无论使用何种方式,由于 Redis 拥有持久化功能,也不需要担心由于服务器故障导致消息丢失的情况。
5、其他场景,如:秒杀、限流、计数器、排行榜、实时系统、共享session等
- 纯内存操作
- 单线程操作,避免了频繁的上下文切换
- 合理高效的数据结构
- 采用了非阻塞I/O多路复用机制(有一个文件描述符同时监听多个文件描述符是否有数据到来)
Redis 使用了一个哈希表来保存所有键值对。一个哈希表,其实就是一个数组,数组的每个元素称为一个哈希桶。每个哈希桶中保存了键值对数据。
当然哈希桶中的元素保存的并不是值本身,而是指向具体值的指针。这也就是说,不管值是 String,还是集合类型,哈希桶中的元素都是指向它们的指针。
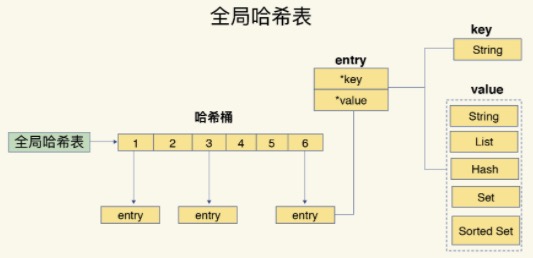
哈希表的最大优势就是让我们可以用 O(1) 的时间复杂度来快速查找到键值对。我们只需要计算key的哈希值,就可以知道它所对应的哈希桶位置,然后就可以访问相应的 entry 元素。
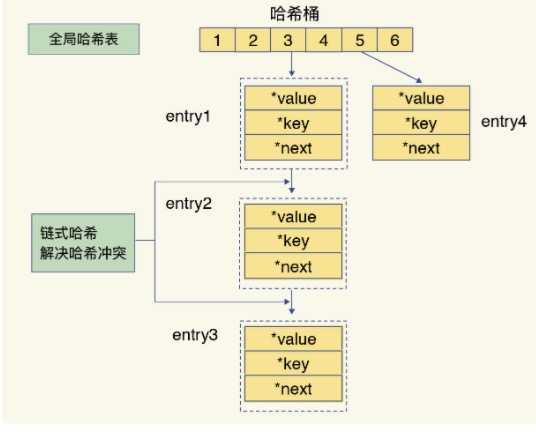
hash值并不是唯一的,当面对海量数据存储,计算时可能会存在哈希冲突,导致两个entry落在同一个哈希桶中。解决方式也比较简单,引入链式哈希。同一个哈希桶中的多个元素用一个链表来保存,它们之间依次用指针连接。
在pom.xml 中引入Spring Boot 官方提供的 starter组件
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
spring-boot-starter-data-redis 依赖于 spring-data-redis 和 lettuce 。
Spring Boot 1.X 版本默认使用的是 Jedis 客户端。2.X 版本替换成 Lettuce 客户端,如果习惯使用 Jedis 的话,可以从 spring-boot-starter-data-redis 中排除 Lettuce 并引入 Jedis。
Lettuce 是一个可伸缩线程安全的 Redis 客户端,多个线程可以共享同一个 RedisConnection,它利用优秀 netty NIO 框架来高效地管理多个连接。
application.yaml 配置redis的地址信息以及lettuce 连接池参数
spring:
redis:
host: 127.0.0.1
port: 6379
# password: abEvH46*YsH&S25d89
lettuce:
pool:
maxIdle: 1000 # 连接池中的最大空闲连接
minIdle: 2 # 连接池中的最小空闲连接
maxWait: 10 # 连接池最大阻塞等待时间(使用负值表示没有限制) 默认 -1
maxActive: 1000 # 连接池最大连接数(使用负值表示没有限制)
初始化 redis的 RedisTemplate 模板bean实例
@Configuration
public class RedisConfig {
@Bean
RedisTemplate<String, String> redisTemplate(RedisConnectionFactory factory) {
final StringRedisTemplate template = new StringRedisTemplate();
template.setConnectionFactory(factory);
template.setKeySerializer(new StringRedisSerializer());
template.setHashValueSerializer(new GenericToStringSerializer<>(Object.class));
template.setValueSerializer(new GenericToStringSerializer<>(Object.class));
template.afterPropertiesSet();
return template;
}
}
RedisTemplate 提供了多种类型的数据类型操作接口,满足多场景的业务需求。

接下来就可以通过单元测试来验证缓存效果了
@RunWith(SpringRunner.class)
@SpringBootTest(classes = StartApplication.class)
@FixMethodOrder(MethodSorters.NAME_ASCENDING)
public class UserMapperTest {
@Resource
private CacheService cacheService;
@Test
public void test1_set1() {
boolean result = cacheService.set("k1", "微观技术");
System.out.println(result);
}
@Test
public void test2_get1() {
String cacheResult = cacheService.get("k1");
System.out.println("k1 的缓存结果:" + cacheResult);
}
}
上面讲的都是通过手动方式写入、删除、查询缓存,缓存的处理逻辑散落在业务代码中。有没有更简单的方式?比如调用一个方法,通过方法上标注的注解自动从缓存中获取,如果查找不到再从数据库查,并自动将结果预热到缓存中。
首先通过 RedisCacheConfiguration 生成默认配置,然后对缓存进行自定义化配置,比如过期时间、缓存前缀、key/value 序列化方法等,然后构建出一个RedisCacheManager,其中通过keySerializationPair 方法为 key 配置序列化,valueSerializationPair方法为 value 配置序列化。
@Bean
public CacheManager cacheManager(RedisConnectionFactory factory) {
RedisCacheConfiguration redisCacheConfiguration = RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofMinutes(30))
.prefixKeysWith("cache:user:")
.disableCachingNullValues()
.serializeKeysWith(keySerializationPair())
.serializeValuesWith(valueSerializationPair());
Map map = new HashMap<String, RedisCacheConfiguration>();
map.put("user", redisCacheConfiguration);
return RedisCacheManager.builder(factory)
.withInitialCacheConfigurations(map).build();
}
private RedisSerializationContext.SerializationPair<String> keySerializationPair() {
return RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer());
}
private RedisSerializationContext.SerializationPair<Object> valueSerializationPair() {
return RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer());
}
修改、删除、查询等常见操作,官方都提供了对应的注解类,只需要在对应的方法上标注即可享受缓存功能,对研发同学及其便利,可以将精力专注到其它业务逻辑处理上。
@Component
@CacheConfig(cacheNames = "user")
public class UserService {
@Cacheable(key = "#id")
public User getUserById(Long id) {
User user = User.builder().id(id).userName("雪糕( " + id + ")").age(18).address("杭州").build();
return user;
}
@CachePut(key = "#user.id")
public User updateUser(User user) {
user.setUserName("雪糕(新名称)");
return user;
}
@CacheEvict(key = "#id")
public void deleteById(Long id) {
System.out.println("db删除数据:" + id);
}
}
常用注解类:
1、 @CacheConfig 类级别的缓存注解,允许共享缓存名称
2、 @Cacheable 一般用于查询操作,根据 key 查询缓存
- 如果 key 存在,直接返回缓存中的数据。
- 如果 key 不存在,查询 db,并将结果更新到缓存中。
3、 @CachePut 一般用于更新和插入操作,每次都会请求 db,然后通过 key 对 Redis 进行写操作。
- 如果 key 存在,更新缓存
- 如果 key 不存在,插入缓存
4、 @CacheEvict 触发移除缓存
- 根据 key 删除缓存中的数据。
https://github.com/aalansehaiyang/spring-boot-bulking
模块:spring-boot-bulking-redis