Project summary #1
Comments
|
The layout of the course is great. As you go through and start getting rough outlines of code put together, I can come behind and clean things up. My C++ game is really rusty, writing code from scratch may take me a bit. |
|
I can also help clean things up; unfortunately, I don't know much C++. |
|
@expr I know you're more than capable of picking up enough of this to be able to add value! |
|
Sounds nice. I'll help out, starting with some thoughts I had straight away: Exercise 2 should also include cpplint (or some other linter, but I don't know of any). Apart from whitespace-nonsense, following a strict style guide is essential for producing readable, maintainable and less faulty C++, this should be instilled from the beginning, as it is hard to unlearn bad habits. Exercise 4 might not work too well if using NAN, as all v8-exposed methods require Exercise 9 is a good idea, but I don't know if that pi calculator is the best way of showing it, mostly because it seems to do the same work n_worker times. If you compare the sync and async output, the async one is way off from the true value. This is because it does less computation than the sync method per worker and the results of workers don't add up to give more precision. It's akin to an oranges to grapefruits comparison. I'm thinking the standard map-reduce word count sample might work better, provided that the text corpus is large enough so it actually takes some time. General debugging of an addon is a tough problem in itself, but essential for any non-trivial development. What I usually end up doing as a first resort is adding |
|
fantastic input @kkoopa! I might have to get you to explain the map-reduce word count sample though, I don't think I'm familiar with that and tbh finding good simple and understandable exercises to do for "cpu intensive" work is tricky, so ideas like this are more than welcome. |
|
You have a bunch of text and want to count how many times each word occurs (a histogram). Easiest way is to split the input domain (say there are 100 lines of roughly 80 columns, words are separated by spaces, no punctuation or weird abbreviations or other crap; with 10 workers, each gets 10 lines). Each worker makes a dictionary of word:count pairs of their subset, then these partial counts are combined into the final dictionary. This is a common example, because it is trivially parallelizable, as there are no dependencies among computations; it is also easy to grasp intuitively. |
|
great, and that's simple to understand so we'll roll with that |
|
first "exercise" implemented and even compiles a test package, needs attention to wording in problem.md, it's just a skeleton atm if someone wants to have a go at it while I move on. |
|
I'll take a crack at wordsmithing. |
|
TBH I have never used nan. Instead I prefer the masochistic approach and use the V8 API directly. Only few things I can think of.
If I think of any others I'll bring them up. |
|
Great points @trevnorris! I wasn't going to delve too deeply into
|
|
Off topic: would anyone happen to have a spare ticket to nodeconf? I'd love to attend :D |
|
@TooTallNate Mikeal says if you can camp he'll open up a spot for you. Then you could come and help us deliver this workshop! DM him if you're serious. |
|
@rvagg The rule for when you need to use Here are a couple examples to clarify: First, let's say we allow the user to call directly into C++. This will require type checking and possibly coercion. void DirectCall(const FunctionCallbackInfo<Value>& args) {
HandleScope scope(args.GetIsolate());
// Check if the second argument is a function.
assert(args[1]->IsFunction());
// Now force first argument to be a string, and grab the function.
Local<String> str = args[0]->ToString();
Local<Function> fn = args[1]->ToFunction();
}The need for Now let's instead create a JS wrapper around the C++ functions that does all the proper type checking. function jsCall(str, fn) {
if (typeof fn !== 'function')
throw new Error('Expected function');
// Calling the internal C++ class and forcing proper types.
internal.indirectCall(''+str, fn);
}Now the C++ side can look like the following: void IndirectCall(const FunctionCallbackInfo<Value>& args) {
Local<String> str = args[0].As<String>();
Local<Function> fn = args[1].As<Function>();
}This is because the There are additional rules when it comes to the use of Hence why doing arithmetic operations in C++ is actually so fast. Using the new var smalloc = require('smalloc');
// Create an array of external uint32_t.
var data = smalloc.alloc(1024, {}, smalloc.Types.Uint32);
// Sum them up.
var sum = internal.sum(data);Since we know the types it is simple and fast to extract the data: void Sum(const FunctionCallbackInfo<Value>& args) {
Local<Object> obj = args[0].As<Object>();
uint32_t data = obj->GetIndexedPropertiesExternalArrayData();
size_t len = obj->GetIndexedPropertiesExternalArrayDataLength();
uint64_t dsum = 0;
for (size_t i = 0; i < len; i++)
dsum += data[i];
// Slight conversion here since uint64_t isn't supported.
args.GetReturnValue.Set(static_cast<double>(dsum));
}Here we never created a new handle, and since the new V8 API allows the return of several natives ( You'll find the above example to be extremely efficient. So much in fact that it'll out perform a JS sum loop with as few as a hundred elements. |
|
That final |
|
@trevnorris, @kkoopa (and others?) I've split up the 3rd exercise into two so that the first of them deals with receiving arguments and the second will return values from C++. The new exercise, called FOR THE SAKE OF ARGUMENT requires that you take I'm doing a |
|
parseInt or such? On June 29, 2014 9:32:52 PM EEST, Rod Vagg [email protected] wrote:
|
|
Force them to use |
|
Something else to point out: Scope, lifetime, garbage collection, memory management, persistent, weak and other handles. |
|
ack, I forgot about persistent handles, that's kind of important but also kind of a mess |
|
all: I don't know how I'm going to do Exercise 3, FOR THE SAKE OF ARGUMENT, gets away with this: NAN_METHOD(Print) {
printf("%s\n", *String::Utf8Value(args[0].As<String>()));
NanReturnUndefined();
}And then to deal with return values in exercise 4, IT'S A TWO WAY STREET, I have to move up to this: NAN_METHOD(Length) {
NanEscapableScope();
int len = strlen(*String::Utf8Value(args[0].As<String>()));
Local<Number> v8len = NanNew(len);
NanReturnValue(v8len);
}Perhaps something could go in between to explain the scope but it needs something that we can force the use of scope, by demonstrating a memory leak or something like that which demonstrates why we have scopes in the code. I just don't know what to do for this that doesn't introduce too many other complexities that need explaining. |
|
That's an exposed method, so you should not use an escapable scope. On June 30, 2014 11:14:58 PM EEST, Rod Vagg [email protected] wrote:
|
|
@ceejbot I'm unlikely to be at the pre-NodeConf thing at your office so you're probably going to have to represent this workshop if anyone actually wants to run it (I have my doubts!). Is that going to work for you? |
|
I will do my best! I plan to invest tomorrow in getting up to speed with it. |
|
FYI this is open source now and it's in npm. Far from complete but it's usable. The docs are either way too verbose or kind of missing for each of the problem statements but that's being worked on (you're welcome to contribute to that!!). |
|
@rvagg First excuse my ignorance of nan. I'm following In the following: NAN_METHOD(Length) {
NanEscapableScope();
int len = strlen(*String::Utf8Value(args[0].As<String>()));
Local<Number> v8len = NanNew(len);
NanReturnValue(v8len);
}This is a call from JS to C++. As such, there's no need for an Next, and I only bring this up because I don't see the accompanying JS, is that Lastly, in latest v8 at least, there's no need to create a And in reality it could have been boiled down to this: NAN_METHOD(Length) {
NanReturnValue(static_cast<uint32_t>((args[0].As<String>())->Utf8Length()));
} |
|
I guess for backwards compatibility users are still required to do a NAN_METHOD(Print) {
printf("%s\n", *String::Utf8Value(args[0].As<String>()));
NanReturnUndefined();
} |
|
There's a significant amount of polish in there now, this is what we have so far:
It's pretty rough for people who haven't had much C++ experience, even if you have, there's V8 to get used to! Even if you've done V8 you have NAN to get used to! So I'm confident that it's not too little for NodeConf but it really does need more and I'll be working on more over the next couple of days at the conference. If you have time, please |
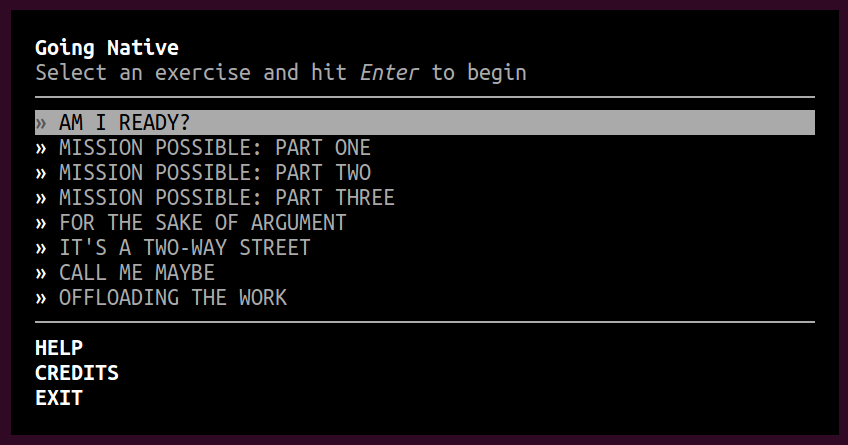
|
I just split the mammoth second exercise into 3 separate exercises, so it's a 3 step process to building their first addon. Thanks for @ceejbot for the suggestion. Unfortunately I'm dead tired and need to go to sleep and this has to be delivered tomorrow at NodeConf. If you have time, please, someone, test it and see if it works and that the wording makes sense! |
Huh?
goingnative is a workshopper for learning how to write native Node.js addons, it's slated for release & use at NodeConf (next week!). I was supposed to start this long ago but ... you know how it goes.
Who?
I've added a bunch of people to this repo, as far as I'm concerned this will be an open project (well, it's technically "closed" until next week) and I'm happy to share ownership and leadership with anyone that has significant contributions to make.
However, I know I've just thrown a bunch of you in here without asking so please if you don't have time or interest in this at the moment and don't want to be spammed then I'd be happy to take you off the collaborators list, just let me know.
@ceejbot and @tjfontaine are here because they are down as running this workshop at NodeConf with me, unfortunately I know they are both super busy with their respective employment, I'm hoping to be able to squeeze some blood out of that stone though!
@wblankenship and @expr are here because I know, through my work with them at NodeSource that they are awesome and should have a lot to offer here in terms of the learning experience.
@trevnorris and @thlorenz are here because I know they have a ton to offer on the C++ side, I don't know realistically how much I can expect to squeeze out of them in terms of time though and @thlorenz is scheduled to help with another workshop at NodeConf anyway.
@TooTallNate and @kkoopa are here because I know from experience that they have a ton of skill and knowledge in this area that would be hugely valuable if they are able to contribute.
What?
The goal here is pretty ambitious, particularly for NodeConf. We need to teach Node/JS programmers how to write native addons. Unfortunately, there is a strong allergy to C++ amongst that cohort in general so we'll have to do lots of handholding and provide lots of up-front boilerplate to point people in the right direction. The success of this will come from the right balance of boilerplate and document to actual code challenges.
learnyounode is the foundational example for building this type of thing, it's basically a terminal-based self-driven programming learning tool that provides you with challenges that ramp up in complexity and you have to complete those challenges successfully to proceed. The expectation is not that people will be able to finish this in a sitting, or even want to finish it all, it's just to give them a taste and get them started and provide enough of a learning path for those wanting to dig deeper.
I'm also thinking of ditching hopes of Windows support, for NodeConf at least. I have a docker build script that can build a dev environment that I can spin up enough instances of and hand out ssh access to separate containers to people in the workshop (@ NodeConf) who don't have suitable dev environments, or who would waste the whole time trying to get their dev environment ready. Unfortunately this assumes you're comfortable with dev over SSH and using a unixy code editor!
Another complication is the V8 variability, so I'm going to lean on nan to get this done in a way that doesn't involve having to explain all that junk. Unfortunately this is quite heavy so it'll almost make it a "nan workshopper" but I don't see a good way around that, and besides, a good portion of current native addons are using nan so it's not an isolated ecosystem. It might be possible to offer a raw 0.10 and another 0.12 version that doesn't use nan without too much hassle, but that's too complex for now.
Structure
Here's my current thoughts on an exercise structure, this is really rough and will likely change as we develop and I'm hoping that you all have ideas on how to improve this:
goingnative verifyfor this will invoke a checker that will determine if you have: a compiler, node-gyp, python 2.x, and anything else that might be needed to get started.printfto print something to stdout so there's very little complex C++ or V8 involved in making this work. Validation will be tricky but it'll have to involve at least invoking a build and running the resulting addon to make sure it works as expected.NanScope()(HandleScope) off the previous exercises completely, perhaps leaving a note in the boilerplate file saying something like// this code is intentionally incomplete and requires a Scopeand point them to a later exercise that will introduce the concept of a scope. This exercise could have provide them with an addon that has no scope and when run is observed leaking memory. Their job is to stop the leak by adding aNanScope(). Maybe too simple?MakeCallback(well,NanMakeCallbackanyway)v8::Objectand populate it with something, aStringproperty, aNumberproperty and maybe even aFunction?ObjectWrapto wrap up a C++ object for JS use.Validation in most existing workshoppers is done via running the solution code in parallel to the submission code and using stdout to compare the results. Sometimes this involves hijacking stdout to replace it with some kind of reporter. The latest workshopper incarnation (v1) doesn't force this as a requirement and I don't imagine we'll have use for it here. Validation will take the form of a script that performs a series of actions to confirm that individual components of the work are complete and correct. The user gets feedback in the form of ticks and crosses to their console for each of these so they can clearly see where they messed up if they get a failure.
Action
I'm diving right in to this, but I'm going to be doing a rough job of each of them as I go and come back and perfect later. Help would be appreciated with coding and also wording the questions, coding the solutions and making the validations fine-grained enough so that the user gets clear feedback about what they've done wrong and it's very difficult to cheat the system.
Could you please let me know if you don't want to be involved, and if you do want to be involved, in what capacity do you think you could be helpful and what would you like to try and tackle?
The text was updated successfully, but these errors were encountered: