Benchmark Details:
- Amazon EC2 m1.large: 7.5GB memory, 2 virtual cores
- 64-bit Ubuntu 11.10
- Darner 0.1.3, compiled Boost 1.46 and leveldb 1.2.0
- Kestrel 2.2.0 with OpenJDK 1.6
How much memory does the queue server use? We are testing both steady-state memory resident, and also how aggressively
the server acquires and releases memory as queues expand and contract. We tuned Kestrel's JVM down to the smallest
heap that didn't cause OOM's and didn't impact performance: -Xmx512m.
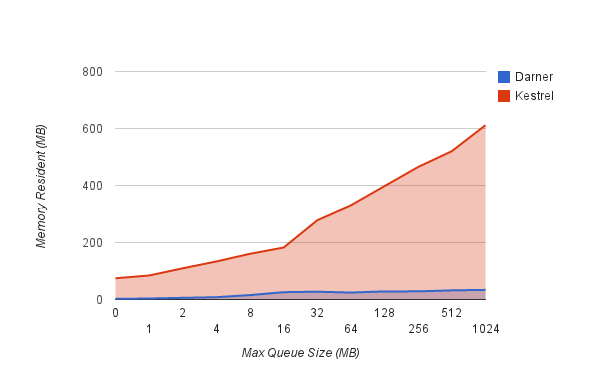
ubuntu@ip-10-6-51-186:~/darner$ bench/mem_rss.sh
kestrel 0 requests: 74476 kB
kestrel 1024 requests: 84256 kB
kestrel 2048 requests: 109508 kB
kestrel 4096 requests: 133492 kB
kestrel 8192 requests: 160404 kB
kestrel 16384 requests: 182460 kB
kestrel 32768 requests: 278340 kB
kestrel 65536 requests: 330300 kB
kestrel 131072 requests: 397852 kB
kestrel 262024 requests: 465148 kB
kestrel 524048 requests: 520476 kB
kestrel 1048576 requests: 611612 kB
darner 0 requests: 2220 kB
darner 1024 requests: 3492 kB
darner 2048 requests: 5872 kB
darner 4096 requests: 8136 kB
darner 8192 requests: 15520 kB
darner 16384 requests: 25656 kB
darner 32768 requests: 27412 kB
darner 65536 requests: 24324 kB
darner 131072 requests: 28440 kB
darner 262024 requests: 28524 kB
darner 524048 requests: 32104 kB
kestrel 1048576 requests: 33848 kB
How quickly can we flood items through an empty queue? This tests the raw throughput of the server. We also include
memcache as an upper bound - a throughput at which we are likely saturating on send/recv syscalls.
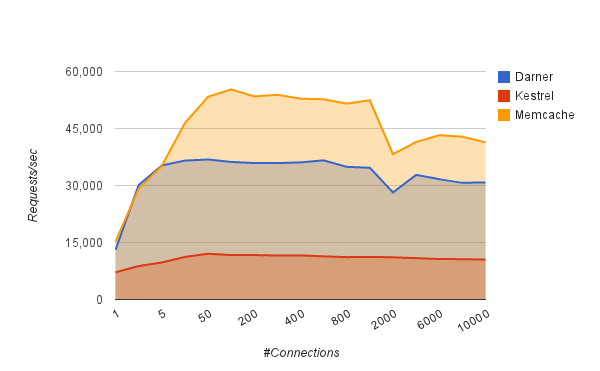
ubuntu@domU-12-31-39-0E-0C-72:~/darner$ bench/flood.sh
warming up kestrel...done.
kestrel 1 conns: 7163.58 #/sec (mean)
kestrel 2 conns: 8802.04 #/sec (mean)
kestrel 5 conns: 9742.79 #/sec (mean)
kestrel 10 conns: 11200.7 #/sec (mean)
kestrel 50 conns: 12038.8 #/sec (mean)
kestrel 100 conns: 11705.5 #/sec (mean)
kestrel 200 conns: 11700 #/sec (mean)
kestrel 300 conns: 11562.7 #/sec (mean)
kestrel 400 conns: 11596.9 #/sec (mean)
kestrel 600 conns: 11357.2 #/sec (mean)
kestrel 800 conns: 11147 #/sec (mean)
kestrel 1000 conns: 11218.9 #/sec (mean)
kestrel 2000 conns: 11101.9 #/sec (mean)
kestrel 4000 conns: 10879 #/sec (mean)
kestrel 6000 conns: 10639.4 #/sec (mean)
kestrel 8000 conns: 10618 #/sec (mean)
kestrel 10000 conns: 10486.6 #/sec (mean)
darner 1 conns: 13088.1 #/sec (mean)
darner 2 conns: 30102.3 #/sec (mean)
darner 5 conns: 35279.6 #/sec (mean)
darner 10 conns: 36549.7 #/sec (mean)
darner 50 conns: 36846 #/sec (mean)
darner 100 conns: 36199.1 #/sec (mean)
darner 200 conns: 35906.6 #/sec (mean)
darner 300 conns: 35893.8 #/sec (mean)
darner 400 conns: 36081.5 #/sec (mean)
darner 600 conns: 36616.6 #/sec (mean)
darner 800 conns: 34910.1 #/sec (mean)
darner 1000 conns: 34668.1 #/sec (mean)
darner 2000 conns: 28169 #/sec (mean)
darner 4000 conns: 32792.3 #/sec (mean)
darner 6000 conns: 31680.7 #/sec (mean)
darner 8000 conns: 30726.7 #/sec (mean)
darner 10000 conns: 30792.9 #/sec (mean)
memcache 1 conns: 15227.7 #/sec (mean)
memcache 2 conns: 29133.3 #/sec (mean)
memcache 5 conns: 35155.6 #/sec (mean)
memcache 10 conns: 46414.5 #/sec (mean)
memcache 50 conns: 53347.6 #/sec (mean)
memcache 100 conns: 55294.4 #/sec (mean)
memcache 200 conns: 53447.4 #/sec (mean)
memcache 300 conns: 53864.8 #/sec (mean)
memcache 400 conns: 52854.1 #/sec (mean)
memcache 600 conns: 52700.9 #/sec (mean)
memcache 800 conns: 51546.4 #/sec (mean)
memcache 1000 conns: 52438.4 #/sec (mean)
memcache 2000 conns: 38255.5 #/sec (mean)
memcache 4000 conns: 41442.2 #/sec (mean)
memcache 6000 conns: 43224.6 #/sec (mean)
memcache 8000 conns: 42844.9 #/sec (mean)
memcache 10000 conns: 41347.9 #/sec (mean)
How does the queue server deal with messages of varying sizes? This benchmark pushes large messages through the queue in order to see whether they cause latency spikes for smaller requests, which can lead to timeouts. For the graph below, a flatter curve means each request is more fairly served in time.
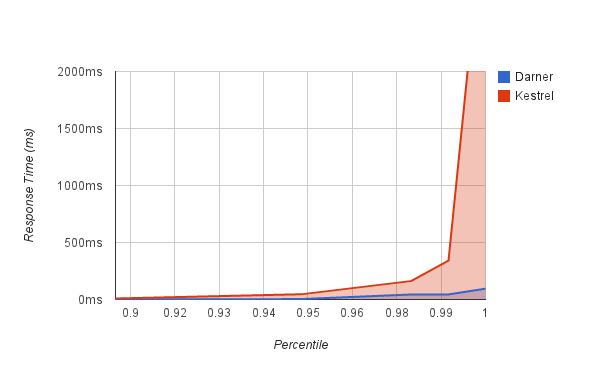
ubuntu@ip-10-6-51-186:~/darner$ bench/fairness.sh
warming up kestrel...done.
kestrel stats:
Concurrency Level: 10
Gets: 0
Sets: 100000
Time taken for tests: 208.706 seconds
Bytes read: 800000 bytes
Read rate: 3.7433 Kbytes/sec
Bytes written: 8700000 bytes
Write rate: 40.7084 Kbytes/sec
Requests per second: 479.143 #/sec (mean)
Time per request: 20868.3 us (mean)
Percentage of the requests served within a certain time (us)
50%: 827
66%: 1434
75%: 1984
80%: 2528
90%: 8809
95%: 45956
98%: 163431
99%: 341297
100%: 3557554 (longest request)
darner stats:
Concurrency Level: 10
Gets: 0
Sets: 100000
Time taken for tests: 26.26 seconds
Bytes read: 800000 bytes
Read rate: 29.7506 Kbytes/sec
Bytes written: 8700000 bytes
Write rate: 323.537 Kbytes/sec
Requests per second: 3808.07 #/sec (mean)
Time per request: 2624.35 us (mean)
Percentage of the requests served within a certain time (us)
50%: 729
66%: 767
75%: 817
80%: 885
90%: 1196
95%: 3507
98%: 43966
99%: 44476
100%: 94989 (longest request)
This tests the queue server's behavior with a backlog of items. The challenge for the queue server is to serve items that no longer all fit in memory. Absolute throughput isn't important here - item sizes are large to quickly saturate free memory. Instead it's important for the throughput to flatten out as the backlog grows.

ubuntu@ip-10-6-51-186:~/darner$ bench/packing.sh
warming up kestrel...done.
kestrel 0 sets: 10350.9 #/sec (mean)
kestrel 4096 sets: 10137.9 #/sec (mean)
kestrel 16384 sets: 10016.5 #/sec (mean)
kestrel 65536 sets: 10073 #/sec (mean)
kestrel 262144 sets: 9243 #/sec (mean)
kestrel 1048576 sets: 9220.41 #/sec (mean)
kestrel 4194304 sets: 9000.9 #/sec (mean)
kestrel 16777216 sets: 7990.73 #/sec (mean)
darner 0 sets: 25723.5 #/sec (mean)
darner 4096 sets: 21853.1 #/sec (mean)
darner 16384 sets: 17792 #/sec (mean)
darner 65536 sets: 13606.4 #/sec (mean)
darner 262144 sets: 13798.8 #/sec (mean)
darner 1048576 sets: 14479.1 #/sec (mean)
darner 4194304 sets: 13535.5 #/sec (mean)
darner 16777216 sets: 12786.9 #/sec (mean)